

Su modelo insignia, MiMo-V2-Pro, utiliza una arquitectura mixture-of-experts que, según Xiaomi, supera un billón de parámetros en total, con 42.000 millones activos por consulta. Eso lo hace aproximadamente tres veces más grande que su predecesor, MiMo-V2-Flash, presentado en diciembre de 2025. A pesar de su escala, Xiaomi afirma que el modelo sigue siendo eficiente gracias a un mecanismo de atención híbrida y puede procesar hasta un millón de tokens de contexto. En lugar de predecir un token a la vez, genera varios tokens en paralelo, lo que lo hace significativamente más rápido.
Dos gráficos de barras muestran los resultados de referencia de MiMo-V2-Pro. A la izquierda, obtiene 81,0 en PinchBench, ocupando el tercer lugar detrás de Claude Opus 4.6 (81,5) y MiMo-V2-Omni (81,2). A la derecha, obtiene 61,5 en ClawEval, también en tercer lugar detrás de Claude Opus 4.6 y Claude Sonnet 4.6 (ambos con 66,3).

MiMo-V2-Pro ocupa el séptimo puesto mundial en el Artificial Analysis Intelligence Index y es el modelo de lenguaje chino más potente después de GLM-5 y MiniMax-M2.7. En el benchmark de programación SWE-bench Verified, obtiene 78%, ligeramente por debajo de Claude Opus 4.6 (80,8), pero cerca de Claude Sonnet 4.6 (79,6). En el benchmark de agentes ClawEval, alcanza 81 puntos, acercándose a Claude Opus 4.6 (81,5), mientras que GPT-5.2 se sitúa en 77.
A partir de un solo prompt, MiMo-V2-Pro puede generar un juego 3D de tower defense con distintos tipos de torres, oleadas de enemigos y efectos de explosión.
MiMo-V2-Pro es considerablemente más barato que Anthropic
Xiaomi también supera a sus competidores en precio. Según su plataforma, MiMo-V2-Pro cuesta 1 dólar por millón de tokens de entrada y 3 dólares por millón de tokens de salida para contextos de hasta 256.000 tokens. En comparación, Claude Sonnet 4.6 cuesta 3 y 15 dólares, mientras que Claude Opus 4.6 cuesta 5 y 25 dólares. Xiaomi actualmente no cobra tarifas por escritura en caché.
El modelo está disponible a través de una API pública. En su lanzamiento, Xiaomi se asoció con cinco frameworks de agentes: OpenClaw, OpenCode, KiloCode, Blackbox y Cline. Se espera que desarrolladores de todo el mundo reciban acceso gratuito a la API durante una semana.
MiMo-V2-Omni ve, oye y actúa en un solo modelo
MiMo-V2-Omni combina codificadores de imagen, vídeo y audio en una arquitectura compartida. El modelo está diseñado no solo para percibir, sino también para actuar directamente sobre lo que percibe. Admite de forma nativa llamadas estructuradas a herramientas, puede ejecutar funciones y navegar por interfaces de usuario.
Seis gráficos de barras comparan MiMo-V2-Omni con Claude Opus 4.6, GPT-5.2, Gemini 3 Pro y Gemini 3 Flash en categorías de audio, imagen y vídeo. MiMo-V2-Omni lidera en MMAU-Pro (69,4), MMMU-Pro (76,8), BigBench Audio (94,0), Video-MME (85,3) y FutureOmni (66,7), mientras queda ligeramente por detrás de Gemini 3 Pro (82,1) en CharXiv RQ (80,1).
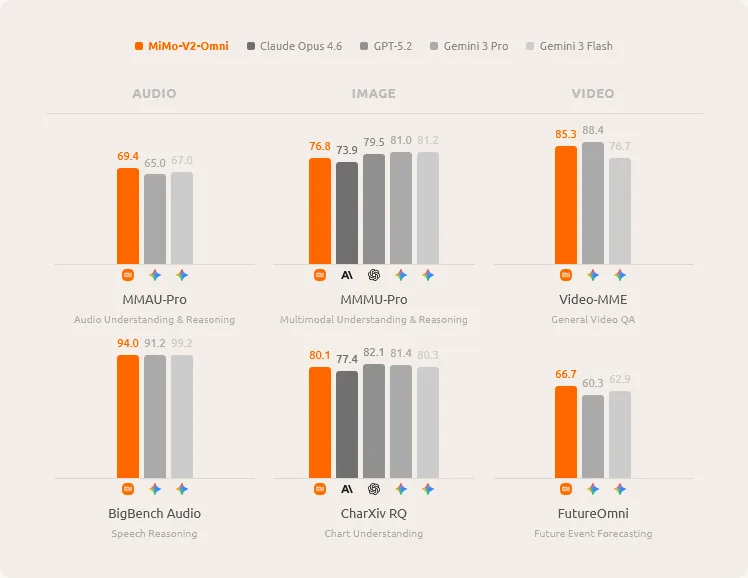
Según Xiaomi, MiMo-V2-Omni supera a Gemini 3 Pro en audio y puede comprender grabaciones continuas de más de 10 horas. En tareas de imagen (MMMU-Pro: 76,8), supera a Claude Opus 4.6 (73,9). Los resultados en benchmarks de agentes son más mixtos: en ClawEval, el modelo Omni obtiene 54,8, claramente por debajo de Claude Opus 4.6 (66,3) y GPT-5.2 (59,6). Sin embargo, en MM-BrowserComp para navegación web, supera a Gemini 3 Pro y GPT-5.2.
En una demostración, Xiaomi utilizó el modelo para analizar imágenes de una cámara de tablero. Identificó peatones, vehículos aproximándose y tramos estrechos de la carretera en tiempo real como peligros potenciales. En otro escenario, MiMo-V2-Omni navegó por un navegador por sí solo, investigó reseñas de productos en la plataforma china Xiaohongshu, comparó precios en JD.com, negoció descuentos con el servicio de atención al cliente por chat y completó la compra.
En otra demostración, el modelo creó contenido multimedia de forma autónoma, depuró el código relacionado y publicó el resultado en TikTok a través de un navegador, sin intervención humana. En todos los casos, MiMo-V2-Omni tomó las decisiones, mientras que el framework de código abierto OpenClaw ejecutó las acciones reales en el navegador y el sistema de archivos.
MiMo-V2-TTS habla con emoción en lugar de un menú desplegable
Según Xiaomi, el modelo de síntesis de voz MiMo-V2-TTS fue entrenado con más de 100 millones de horas de datos de voz. Internamente descompone el habla en múltiples capas paralelas de unidades discretas, lo que permite un control más preciso del sonido, el ritmo y la emoción que los sistemas convencionales.
La diferencia clave frente a los sistemas TTS tradicionales es que los usuarios no eligen emociones de una lista. En su lugar, describen libremente el estilo de habla deseado en lenguaje natural. Por ejemplo, “somnoliento, recién despierto, ligeramente ronco” debería sonar diferente de “enojado, pero intentando mantenerse calmado”. El modelo también genera elementos paralingüísticos como tos, vacilaciones, suspiros y risas como partes nativas de la salida, en lugar de clips de audio añadidos después.
Según Xiaomi, MiMo-V2-TTS es la única API TTS disponible comercialmente que admite de forma nativa tanto voz como canto en el mismo modelo. Pistas tipográficas como mayúsculas o repeticiones de caracteres se interpretan como indicaciones de dirección para el énfasis y el ritmo. “THIS IS IMPORTANT” no se pronuncia simplemente más alto, sino con énfasis. Incluso sin instrucciones explícitas de estilo, el modelo puede inferir el tono apropiado directamente del contenido del texto.
Benchmarks sólidos, pero todavía no es el líder
Al lanzar tres modelos especializados al mismo tiempo, Xiaomi deja claro que quiere ofrecer una plataforma completa para agentes de IA. Los benchmarks muestran que los modelos se acercan a Anthropic y OpenAI en algunas disciplinas, aunque siguen por detrás en otras. En particular, MiMo-V2-Pro todavía se mantiene varios puntos por debajo de Claude Opus 4.6 en tareas generales de agentes.
Como próximos pasos, el equipo de MiMo dice que está trabajando en planificación a largo plazo durante horas y días, streaming en tiempo real, sistemas multiagente coordinados y robótica.
“Creemos que el camino hacia la inteligencia general pasa por el mundo real”, escribió el equipo. “Un modelo que solo lee texto vive en una biblioteca. Un modelo que ve, oye, piensa y actúa vive en el mundo”.
Hunter Alpha no era DeepSeek
Antes de que Xiaomi revelara oficialmente el modelo, MiMo-V2-Pro había aparecido de forma anónima en la plataforma API OpenRouter bajo el nombre en clave Hunter Alpha. Según Xiaomi, el volumen de uso en la plataforma aumentó de forma constante, y el modelo lideró la clasificación diaria durante varios días consecutivos, superando finalmente un billón de tokens utilizados. Las aplicaciones más frecuentes fueron herramientas de programación.
Muchos usuarios especularon con que Hunter Alpha podría ser DeepSeek V4. Pero DeepSeek sigue retrasado. Según un informe, el próximo gran modelo de DeepSeek se ha pospuesto debido al aumento en el tamaño del modelo.
En cambio, otros proveedores chinos están avanzando. Zhipu AI lanzó recientemente GLM-5, un modelo open source con 744.000 millones de parámetros diseñado para competir con Claude Opus 4.5 y GPT-5.2 en tareas de programación y agentes. Moonshot AI apuesta por enjambres de agentes paralelos con Kimi K2.5, mientras que Alibaba ha ampliado su serie Qwen-3.5.
Xiaomi se está posicionando rápidamente como un competidor serio en la carrera de la IA al lanzar un ecosistema completo de modelos centrados en agentes, en lugar de un único LLM. Aunque sus modelos ya se acercan a líderes como Anthropic en varios benchmarks, la principal ventaja está en los precios más bajos y en las capacidades de agentes para aplicaciones reales. Si Xiaomi logra escalar sistemas multiagente e integración con robótica, podría convertirse en un actor importante en la próxima fase de la automatización impulsada por IA.

 ES
ES  EN
EN