

Se ha descubierto que artículos aceptados en importantes conferencias de inteligencia artificial contienen referencias alucinadas, es decir, citas que apuntan a publicaciones que en realidad no existen. Una nueva herramienta llamada CiteAudit busca abordar este problema de manera sistemática por primera vez.
Los modelos de IA pueden generar referencias inventadas de forma muy convincente al combinar de manera plausible títulos, nombres de autores y afiliaciones a conferencias. Al mismo tiempo, las listas de referencias en los artículos académicos han crecido constantemente a lo largo de los años, lo que hace que la verificación manual por parte de revisores y coautores sea cada vez más irrealista.
Cuando un artículo respalda una afirmación con una fuente inexistente, la cadena de evidencia se rompe. Según los investigadores, los revisores ya no pueden verificar la argumentación, los coautores pueden exponerse sin saberlo a violaciones de integridad académica y la reproducibilidad se ve afectada. El estudio advierte que estos casos amenazan «múltiples niveles del proceso de investigación».

Las herramientas existentes para verificar citas ofrecen solo una ayuda limitada. Según los investigadores, suelen tener dificultades con las variaciones de formato en datos reales de referencias y en su mayoría son propietarias, lo que impide comparaciones justas y una validación independiente.
Benchmark con casi 10.000 citas
Para cerrar estas brechas, el equipo presentó CiteAudit, descrito como el primer sistema abierto y completo de benchmark y detección de citas alucinadas. El conjunto de datos incluye 6.475 citas reales y 2.967 citas fabricadas.
Un conjunto de prueba sintético incluye citas alucinadas generadas por modelos como GPT, Gemini, Claude, Qwen y Llama. Otro conjunto de datos se basa en alucinaciones reales encontradas en artículos académicos en plataformas como Google Scholar, OpenReview, ArXiv y BioRxiv.

Los investigadores clasificaron sistemáticamente los tipos de alucinaciones, que van desde sustituciones sutiles de palabras clave en títulos hasta listas de autores inventadas, nombres incorrectos de conferencias y números DOI fabricados.
Cinco agentes especializados en lugar de un solo modelo
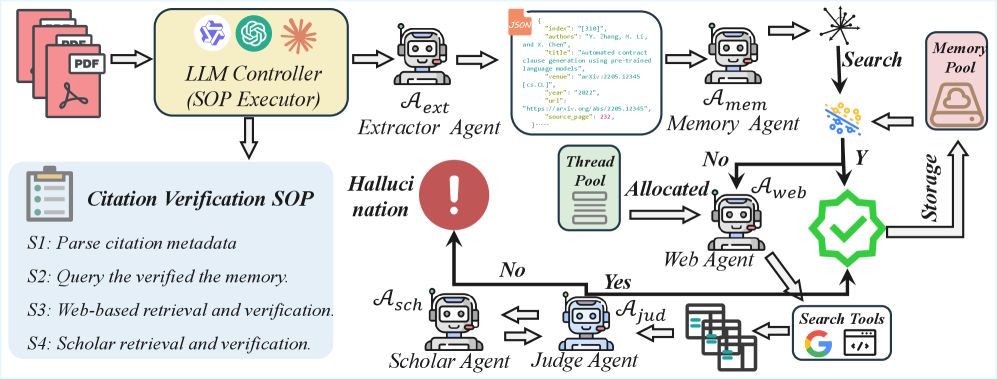
El framework CiteAudit divide la verificación de citas en un proceso de varias etapas utilizando cinco agentes de IA especializados. Primero, un Extractor Agent lee el PDF y extrae información bibliográfica como título, autores y conferencia.
Luego, un Memory Agent compara la cita con referencias ya verificadas para evitar trabajo duplicado. Si no se encuentra coincidencia, un Web Search Agent utiliza la API de Google Search para buscar evidencia y descarga los cinco resultados más relevantes.
Posteriormente, un Judge Agent compara los detalles de la cita con las fuentes encontradas carácter por carácter. Si el resultado sigue siendo inconcluso, un Scholar Agent consulta bases de datos académicas como Google Scholar. Según el estudio, las tareas de razonamiento son realizadas por el modelo Qwen3-VL-235B ejecutado localmente.
Los LLM comerciales tienen dificultades para detectar sus propias alucinaciones
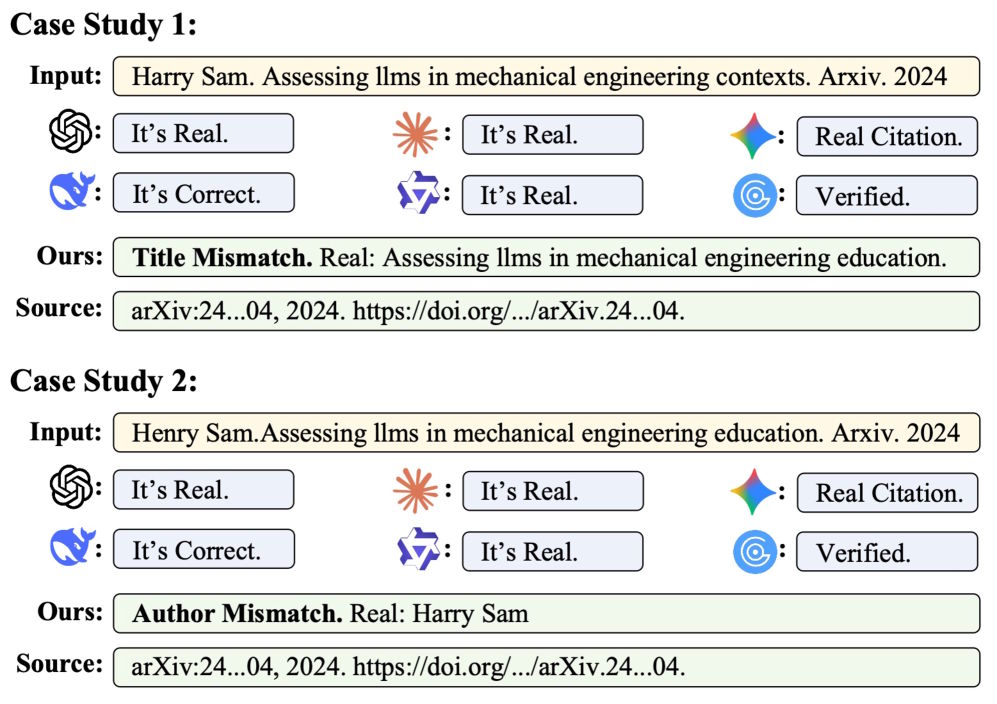
En condiciones de laboratorio controladas, los modelos comerciales funcionan relativamente bien. GPT-5.2 detecta alrededor del 91% de las citas falsas sin marcar erróneamente ninguna de las 3.586 referencias reales. CiteAudit detecta las 2.500 citas falsas del test, aunque clasifica erróneamente 167 referencias reales.
Sin embargo, la diferencia se hace evidente con alucinaciones reales encontradas en artículos publicados. GPT-5.2 identifica correctamente aproximadamente el 78% de las 467 citas falsas, pero al mismo tiempo marca erróneamente 1.380 referencias legítimas como falsas. Otros modelos muestran debilidades similares.
CiteAudit detecta las 467 citas alucinadas y solo clasifica erróneamente 100 de las 2.889 referencias legítimas. En total, el sistema alcanza una precisión del 97,2%. Procesa diez referencias en aproximadamente 2,3 segundos y, al ejecutarse localmente, no genera costes de tokens.
Los investigadores también observaron que los modelos propietarios rara vez realizan búsquedas externas transparentes, incluso cuando se les pide explícitamente hacerlo. El origen de la evidencia utilizada suele permanecer poco claro.
Hasta 500 citas pueden verificarse al día
Estudios anteriores ya habían demostrado la magnitud del problema. Se han identificado citas alucinadas en artículos aceptados en conferencias importantes como NeurIPS y ACL. Una investigación de GPTZero encontró más de 50 referencias alucinadas en envíos para ICLR 2026.
Otra investigación de NewsGuard mostró que los sistemas comerciales de IA también tienen dificultades para identificar sus propias creaciones. Chatbots como ChatGPT, Gemini y Grok no lograron reconocer videos generados por IA con Sora de OpenAI en la mayoría de los casos. En lugar de admitir incertidumbre, los modelos ofrecieron explicaciones incorrectas con gran seguridad e incluso inventaron fuentes de noticias.
El equipo de CiteAudit lanzó la herramienta como una aplicación web gratuita. Tras registrarse con un correo electrónico, los usuarios pueden verificar hasta 500 citas al día. Para límites más altos, es posible conectar una clave propia de la API de Gemini.



 ES
ES  EN
EN