

Investigadores de Meta FAIR y de la Universidad de Nueva York han realizado un estudio sistemático sobre cómo entrenar modelos de inteligencia artificial multimodales desde cero. Sus resultados cuestionan varias suposiciones ampliamente aceptadas en el campo.
Los grandes modelos de lenguaje han definido la era de los modelos fundacionales. Sin embargo, en su artículo “Beyond Language Modeling”, los investigadores argumentan que el texto es, en última instancia, una compresión con pérdida de la realidad. Haciendo referencia a la alegoría de la cueva de Platón, sugieren que los modelos de lenguaje han aprendido a describir las sombras en la pared sin haber visto nunca los objetos que las proyectan. Además, los datos de texto de alta calidad son finitos y eventualmente podrían agotarse.

Para abordar esta limitación, el equipo entrenó un único modelo completamente desde cero. Combina la predicción tradicional de tokens para el lenguaje con un método de difusión llamado Flow Matching para los datos visuales. El entrenamiento incluyó texto, video sin procesar, pares imagen-texto y videos condicionados por acciones. Un punto metodológico clave fue evitar construir el modelo sobre uno de lenguaje ya existente, lo que previene que conocimientos previos distorsionen los resultados.
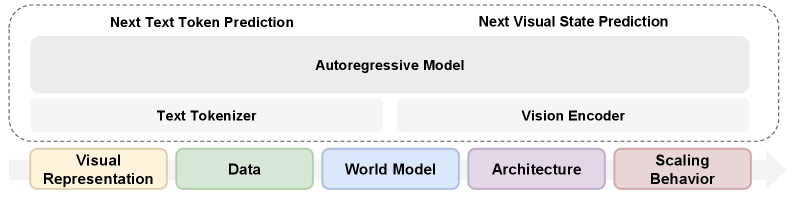
Un único codificador visual basta para comprender y generar imágenes
Enfoques anteriores como Janus o BAGEL utilizan codificadores visuales separados para la comprensión y la generación de imágenes. Según el estudio, esta separación podría no ser necesaria.
Un Representation Autoencoder (RAE) basado en el modelo visual SigLIP 2 superó a los codificadores VAE tradicionales tanto en generación de imágenes como en comprensión visual, manteniendo al mismo tiempo el rendimiento lingüístico al nivel de un modelo puramente textual.
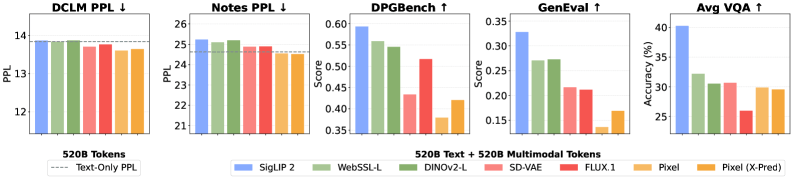
En lugar de dos rutas de procesamiento separadas, un único codificador puede manejar ambas tareas, simplificando considerablemente la arquitectura.
Otra suposición común sostiene que la visión y el lenguaje compiten dentro de un mismo modelo. El estudio sugiere lo contrario. El entrenamiento con video sin anotaciones de texto no perjudicó el rendimiento lingüístico. De hecho, en un conjunto de validación, el modelo entrenado con texto y video superó ligeramente la línea base basada únicamente en texto.
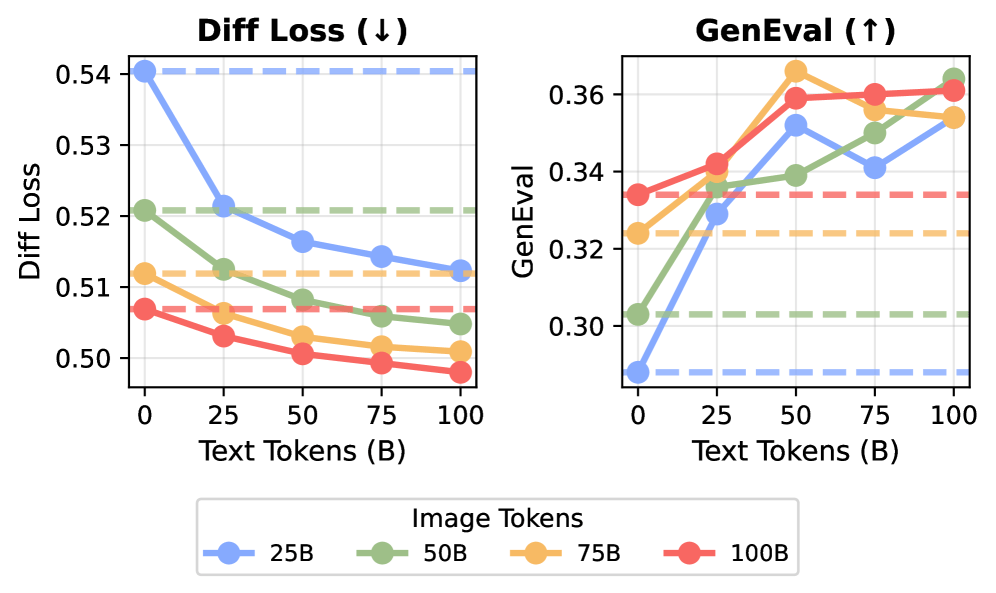
También apareció un efecto de sinergia interesante. Cuando se combinaron 20 mil millones de tokens de VQA (datos de preguntas y respuestas visuales) con 80 mil millones de tokens de video, pares imagen-texto (MetaCLIP) o texto, el modelo resultante superó a otro entrenado con 100 mil millones de tokens de VQA exclusivamente.
El modelado del mundo surge de forma natural
Los investigadores también probaron si el modelo podía predecir estados visuales futuros. Dada una imagen actual y una instrucción de navegación, el sistema debía generar el siguiente estado visual. Las acciones se codificaron directamente como texto, sin necesidad de modificar la arquitectura.
Los resultados sugieren que las capacidades de modelado del mundo surgen principalmente del entrenamiento multimodal general, y no de datos de navegación específicos. Con apenas un 1 % de datos específicos de la tarea, el modelo ya alcanzó un rendimiento competitivo.

El sistema incluso pudo responder a comandos en lenguaje natural como “Get out of the shadow!” y generar secuencias de imágenes apropiadas, a pesar de no haber visto nunca ese tipo de instrucciones durante el entrenamiento.
Mixture-of-Experts aprende especialización automáticamente
El estudio también analizó arquitecturas Mixture-of-Experts (MoE). En este enfoque, cada token de entrada se dirige solo a un subconjunto de módulos especializados, en lugar de activar todo el modelo. Esto reduce el coste computacional mientras aumenta la capacidad total del sistema.
En un modelo con 13,5 mil millones de parámetros, de los cuales solo 1,5 mil millones se activan por token, la arquitectura MoE superó tanto a modelos densos como a estrategias de separación diseñadas manualmente.
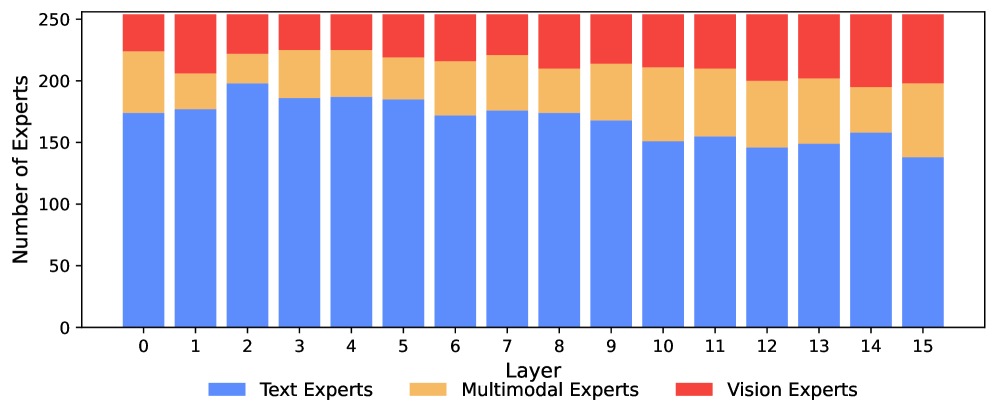
Otro hallazgo notable es que la comprensión y la generación de imágenes activan los mismos expertos, con correlaciones de al menos 0,90 en todas las capas. Los investigadores interpretan esto como evidencia de la llamada “Bitter Lesson” de Rich Sutton: aprender a partir de grandes volúmenes de datos suele superar a las soluciones diseñadas manualmente.
La visión requiere muchos más datos que el lenguaje
Entrenar modelos de IA siempre implica decidir cómo distribuir el presupuesto computacional entre tamaño del modelo y volumen de datos. Las conocidas leyes de escalado Chinchilla sugieren que, para modelos de lenguaje, ambos deben crecer a un ritmo similar.
Sin embargo, al aplicar estas leyes a un modelo conjunto de visión y lenguaje, los investigadores encontraron una fuerte asimetría. Para el lenguaje se mantiene el equilibrio tradicional, pero para la visión la estrategia óptima se desplaza claramente hacia más datos en lugar de un modelo más grande.
A medida que los modelos crecen, la diferencia se vuelve dramática. Partiendo de un modelo base de 1 mil millón de parámetros, la necesidad relativa de datos visuales frente a datos de lenguaje aumenta 14 veces con 100 mil millones de parámetros y 51 veces con 1 billón de parámetros.
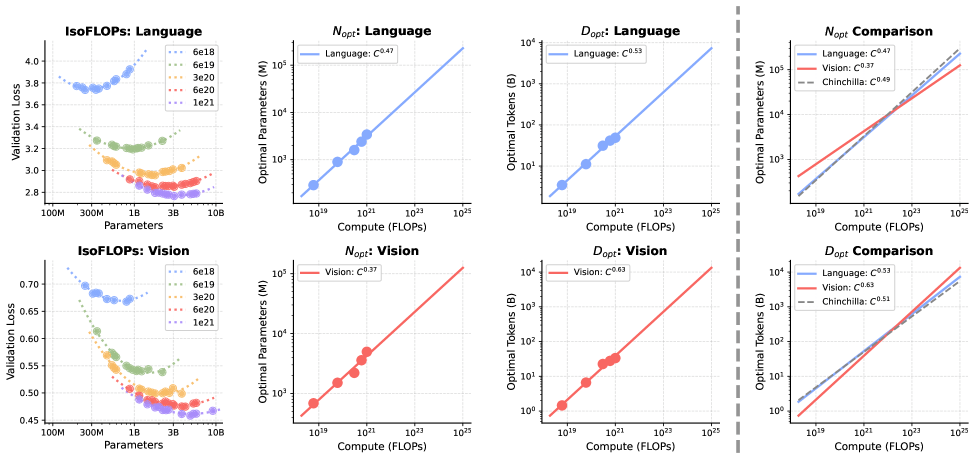
Este desequilibrio es difícil de resolver en modelos densos tradicionales, donde todos los parámetros se activan en cada paso de cálculo.
La arquitectura Mixture-of-Experts ayuda a mitigar el problema. Como solo se activa una fracción de expertos por token, el modelo puede tener una gran cantidad total de parámetros sin aumentar proporcionalmente el coste computacional. Así, el lenguaje se beneficia de una alta capacidad de parámetros mientras que la visión aprovecha grandes volúmenes de datos. Según el estudio, MoE reduce la asimetría de escalado entre ambas modalidades aproximadamente a la mitad.
Los investigadores subrayan que su trabajo se centra únicamente en el preentrenamiento. El ajuste fino y el aprendizaje por refuerzo no fueron analizados en profundidad. Aun así, los resultados sugieren que la frontera entre modelos multimodales y modelos del mundo podría difuminarse cada vez más.
En la actualidad, enormes volúmenes de video sin etiquetar siguen prácticamente sin utilizarse. El estudio indica que estos datos podrían integrarse en el entrenamiento de IA sin perjudicar el rendimiento lingüístico, lo que podría abrir la puerta a sistemas multimodales mucho más potentes en el futuro.



 ES
ES  EN
EN