

Anthropic lanzó Claude Opus 4.6 como una actualización de su anterior modelo tope de gama, Opus 4.5. El cambio más significativo es la introducción de una ventana de contexto de un millón de tokens, actualmente disponible en fase beta.
Sin embargo, esto intensifica un desafío conocido: cuanto más contexto debe procesar un modelo, más puede degradarse su rendimiento, un fenómeno conocido como “context rot”. Anthropic aborda este problema con mejoras en el propio modelo y una nueva función de “Compaction” que resume automáticamente el contexto antiguo antes de que la ventana se llene.
Según Anthropic, la mejora es claramente visible en los benchmarks. En MRCR v2, una prueba que mide la capacidad de encontrar información oculta en grandes corpus de texto, Opus 4.6 alcanza un 76% con un millón de tokens. En las mismas condiciones, el modelo más pequeño Sonnet 4.5 logra solo 18,5%.
El modelo está disponible de inmediato en claude.ai, a través de la API y en todas las principales plataformas cloud. Los precios estándar se mantienen en 5 dólares por millón de tokens de entrada y 25 dólares por millón de tokens de salida. Para prompts que superan los 200.000 tokens, se aplica una tarifa premium: 10 dólares por millón de tokens de entrada y 37,50 dólares por millón de tokens de salida.
Opus 4.6 supera a GPT-5.2 en benchmarks de trabajo de conocimiento
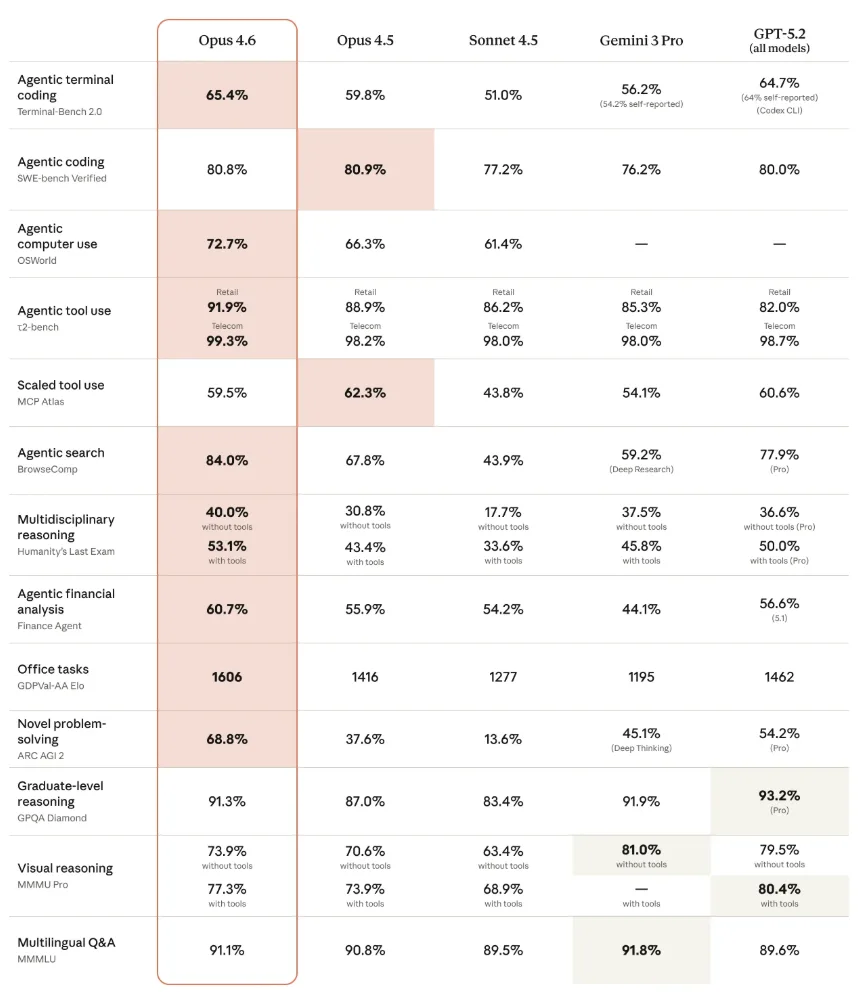
En múltiples benchmarks, Anthropic informa de resultados líderes en la industria. En el benchmark GDPval-AA, que evalúa trabajo de conocimiento económicamente relevante en áreas como finanzas y derecho, Opus 4.6 alcanza una puntuación Elo de 1606. Esto supone una ventaja de 144 puntos frente a la variante más potente de GPT-5.2 de OpenAI (1462) y una mejora de 190 puntos respecto a su propio predecesor, Opus 4.5 (1416).
En Humanity’s Last Exam, una prueba compleja de razonamiento multidisciplinar, el modelo obtiene un 53,1% con herramientas, por delante de todos los competidores. En el benchmark de programación agentica Terminal-Bench 2.0, Opus 4.6 logra un 65,4%, nuevamente la puntuación más alta. En BrowseComp, que mide la capacidad de localizar información difícil de encontrar en línea, el modelo alcanza un 84%. Como siempre, los benchmarks son solo un indicador del rendimiento en tareas reales.
Capacidades de programación mejoradas para un trabajo más autónomo
Más allá de la recuperación de información, Anthropic ha mejorado las capacidades de programación del modelo. Opus 4.6 está diseñado para planificar con mayor cuidado, trabajar de forma autónoma durante períodos más largos y operar con mayor fiabilidad en grandes bases de código. También incorpora mejores capacidades de revisión de código y depuración, lo que le permite identificar mejor sus propios errores.
En el conocido benchmark de programación SWE-bench, Opus 4.6 no supera a Opus 4.5 con el prompt estándar. Sin embargo, con ajuste de prompts, rinde ligeramente mejor, alcanzando un 81,42%.
Anthropic señala que el modelo puede sobreanalizar tareas simples. Opus 4.6 verifica sus conclusiones con mayor frecuencia y profundidad, lo que mejora los resultados en problemas complejos, pero puede aumentar el coste y la latencia en consultas sencillas. En esos casos, Anthropic recomienda reducir el nuevo parámetro Effort del valor predeterminado “high” a “medium”.
Nuevas funciones para desarrolladores y usuarios de oficina
Anthropic introduce varias funciones nuevas en la API para desarrolladores. Con “Adaptive Thinking”, el modelo puede decidir por sí mismo cuándo es beneficioso un razonamiento más profundo. La función Compaction resume automáticamente el contexto antiguo a medida que las conversaciones se acercan al límite de la ventana de contexto. La longitud máxima de salida se ha incrementado a 128.000 tokens.
En Claude Code, los usuarios pueden desplegar ahora “Agent Teams”, donde múltiples agentes de IA trabajan en paralelo y se coordinan de forma autónoma. Esta función está disponible actualmente como vista previa de investigación.
Para los usuarios de oficina, Anthropic ha mejorado la integración con Excel e introducido una nueva integración con PowerPoint, también como vista previa de investigación. Claude en Excel ahora puede procesar datos no estructurados, inferir automáticamente la estructura correcta y aplicar cambios de varios pasos en una sola pasada.
Sin grandes avances en seguridad
Anthropic subraya que las mejoras de rendimiento no se han logrado a costa de la seguridad. En auditorías de comportamiento automatizadas, Opus 4.6 muestra tasas bajas de conductas indeseables como el engaño, la adulación o la cooperación en usos indebidos.
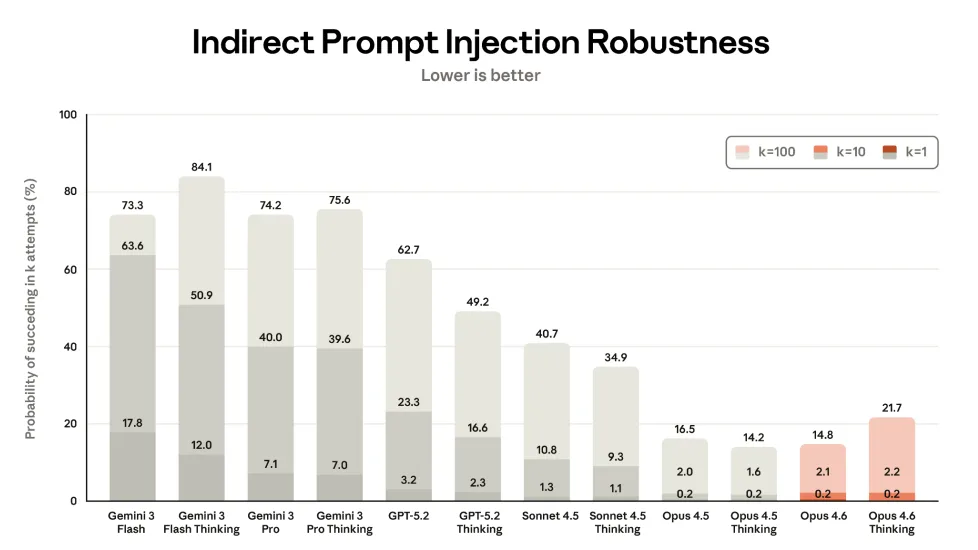
No obstante, Opus 4.6 Thinking es ligeramente más vulnerable a ataques de inyección indirecta de prompts que su ya vulnerable predecesor, un aspecto especialmente preocupante en el contexto de modelos de IA agentica.
Seguridad
Las auditorías automatizadas muestran que Opus 4.6 presenta una baja propensión a comportamientos no deseados, como el engaño, la adulación, el refuerzo de ideas erróneas del usuario o la facilitación de actividades indebidas.
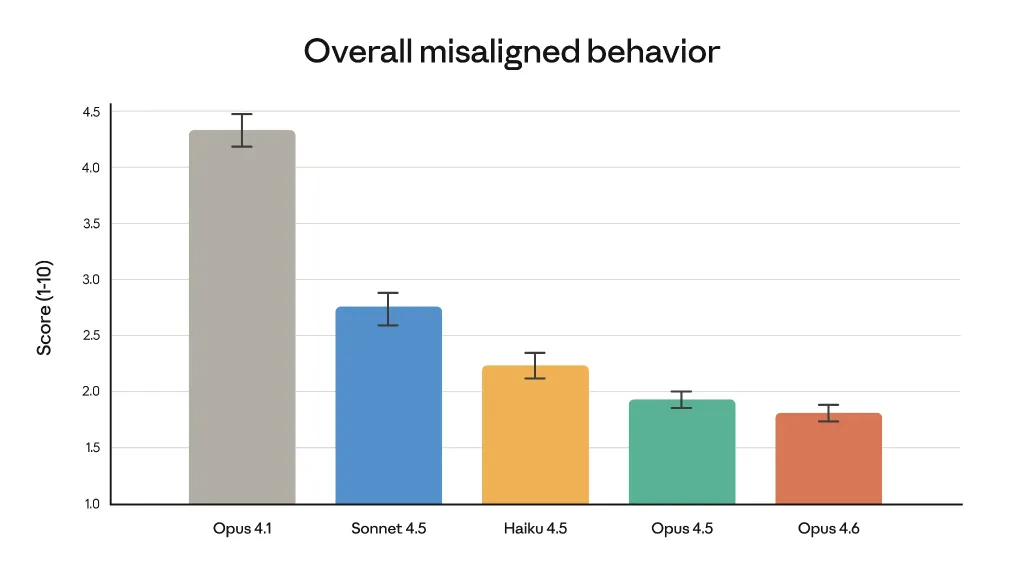
Para evaluar el modelo, la compañía llevó a cabo su serie de evaluaciones más completa hasta la fecha, aplicando por primera vez nuevas metodologías de prueba y perfeccionando los enfoques de evaluación existentes.
Disponibilidad y nuevas funciones
Claude Opus 4.6 ya está disponible a través de la interfaz web, la API y en las principales plataformas en la nube.
Entre las nuevas funciones del conjunto de herramientas para desarrolladores se incluyen:
-
Pensamiento adaptativo: el modelo decide de forma autónoma cuándo es necesario activar un razonamiento más profundo;
-
Control del esfuerzo: cuatro niveles de intensidad de trabajo, desde bajo hasta máximo;
-
Compactación del contexto: resume y reemplaza automáticamente el contexto antiguo cuando las conversaciones se acercan al límite de tokens.
Opus 4.6 también ofrece un mejor rendimiento con herramientas de oficina como Excel y PowerPoint.
Conclusión
Claude Opus 4.6 marca un claro avance en los sistemas de IA con grandes contextos. Al combinar una ventana de un millón de tokens con una compacción de contexto mejorada, Anthropic demuestra que puede escalar el razonamiento sobre documentos extensos sin una caída proporcional de la utilidad. Los sólidos resultados en benchmarks de trabajo de conocimiento, programación agentica y recuperación de información posicionan a Opus 4.6 como un serio competidor frente a las principales variantes de GPT-5.x, especialmente para tareas profesionales complejas.
Al mismo tiempo, la tendencia del modelo a sobreanalizar solicitudes simples y su mayor sensibilidad a la inyección indirecta de prompts ponen de relieve los compromisos que implica ampliar la autonomía y la longitud del contexto. En conjunto, Opus 4.6 refuerza la estrategia de Anthropic: priorizar la fiabilidad en el razonamiento a gran escala y en los flujos de trabajo para desarrolladores, aceptando que una configuración cuidadosa y la supervisión humana siguen siendo esenciales a medida que los modelos se vuelven más potentes.

 ES
ES  EN
EN