

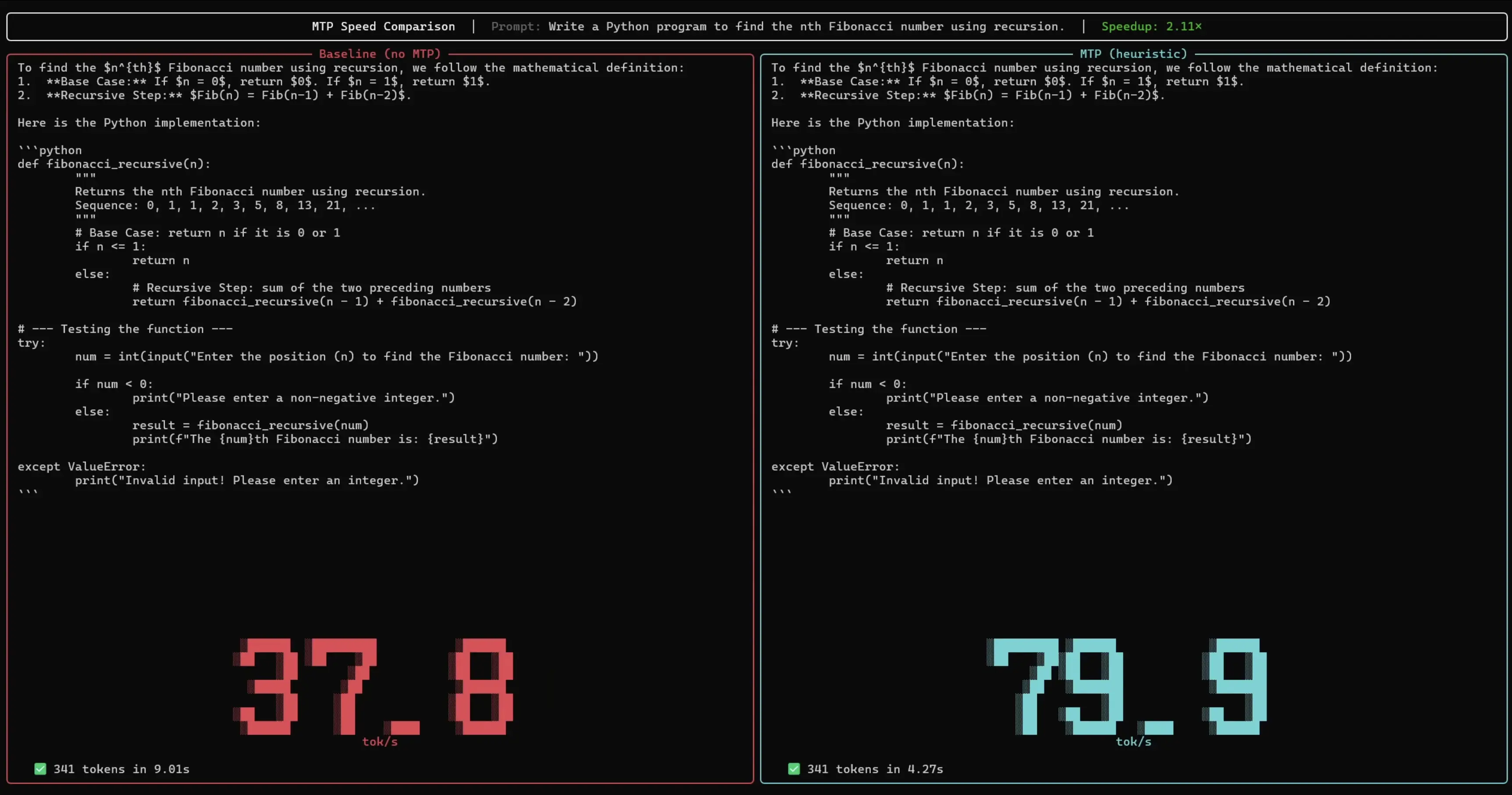
Por lo general, los grandes modelos de lenguaje generan texto token a token. En cada paso individual deben cargarse miles de millones de parámetros desde la memoria, lo que deja al núcleo de cálculo del procesador prácticamente inactivo, esperando la mayor parte del tiempo a que lleguen los datos.
Aquí es exactamente donde entra en juego la tecnología MTP. Mientras el modelo principal espera por sus datos, un modelo auxiliar pequeño y rápido aprovecha la capacidad de cálculo libre para proponer varias palabras a la vez. El modelo principal revisa después estas sugerencias en una única pasada conjunta. Si las propuestas son correctas, se aceptan todas de una sola vez. Aunque se ejecutan dos modelos simultáneamente, el modelo auxiliar pequeño aprovecha ciclos de espera que de otro modo se desperdiciarían, produciendo el mismo resultado en mucho menos tiempo y, según se afirma, sin ninguna pérdida de calidad ni precisión.
Según Google, los smartphones, los equipos locales y las aplicaciones en la nube se benefician por igual. Los drafters están disponibles bajo la licencia abierta Apache 2.0 en Hugging Face y Kaggle. El modelo de pesos abiertos Gemma 4, presentado a principios de abril, ya ha sido descargado más de 60 millones de veces, según informa Google.
Los MTP Drafters representan un avance de ingeniería relevante para hacer que los grandes modelos de lenguaje resulten realmente prácticos en hardware de consumo, cerrando la brecha entre la capacidad bruta del modelo y la velocidad real de despliegue. Si los aumentos de rendimiento de hasta el triple se confirman en cargas de trabajo diversas, esto podría acelerar significativamente la adopción de la IA en dispositivos sin necesidad de actualizar el hardware.

 ES
ES  EN
EN