

GPT-5.2 Pro de OpenAI ha logrado un nuevo récord en el exigente benchmark FrontierMath, según las pruebas realizadas por Epoch AI. El modelo alcanzó un 31% en el nivel más difícil, Tier 4, lo que representa un salto significativo frente al anterior mejor resultado del 19% obtenido por Gemini 3 Pro. Debido a problemas con la API, Epoch AI evaluó el modelo manualmente a través de la interfaz web de ChatGPT.
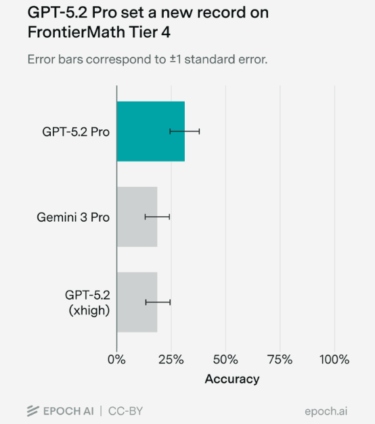
El rendimiento de GPT-5.2 Pro superó claramente a sus competidores más cercanos: Gemini 3 Pro (19%) y GPT-5.2 xhigh (17%). Fuente: Epoch AI
De un total de 48 tareas, GPT-5.2 Pro resolvió con éxito 15, incluidas cuatro que ningún modelo anterior había logrado solucionar. Varios matemáticos profesionales evaluaron las respuestas, elogiando en general su calidad, aunque señalaron en algunos casos una falta ocasional de precisión en los razonamientos.
Los resultados refuerzan los informes positivos recientes sobre los modelos avanzados de IA — en particular GPT-5 Thinking y GPT-5 Pro — como herramientas potentes para la resolución de problemas matemáticos complejos. Según algunos testimonios, GPT-5 incluso ha resuelto de forma autónoma problemas de Erdős, mientras que en otros casos ha actuado como un asistente matemático avanzado.
Conclusión
El nuevo récord de GPT-5.2 Pro confirma que los modelos de razonamiento avanzado están entrando en una fase cualitativamente distinta, donde la IA comienza a competir con expertos humanos en matemáticas de alto nivel. Si esta tendencia se mantiene, los próximos años podrían redefinir por completo la investigación científica, la educación y el desarrollo tecnológico impulsado por inteligencia artificial.

 ES
ES  EN
EN