

Se espera que los agentes autónomos de IA puedan buscar en internet de forma independiente, responder correos electrónicos, realizar compras y coordinar tareas complejas a través de API. Sin embargo, el propio entorno en el que operan puede convertirse en un arma contra ellos. Un artículo de investigación de Google DeepMind introduce el término “AI Agent Traps” y, según sus autores, presenta el primer marco sistemático para esta clase de amenazas.
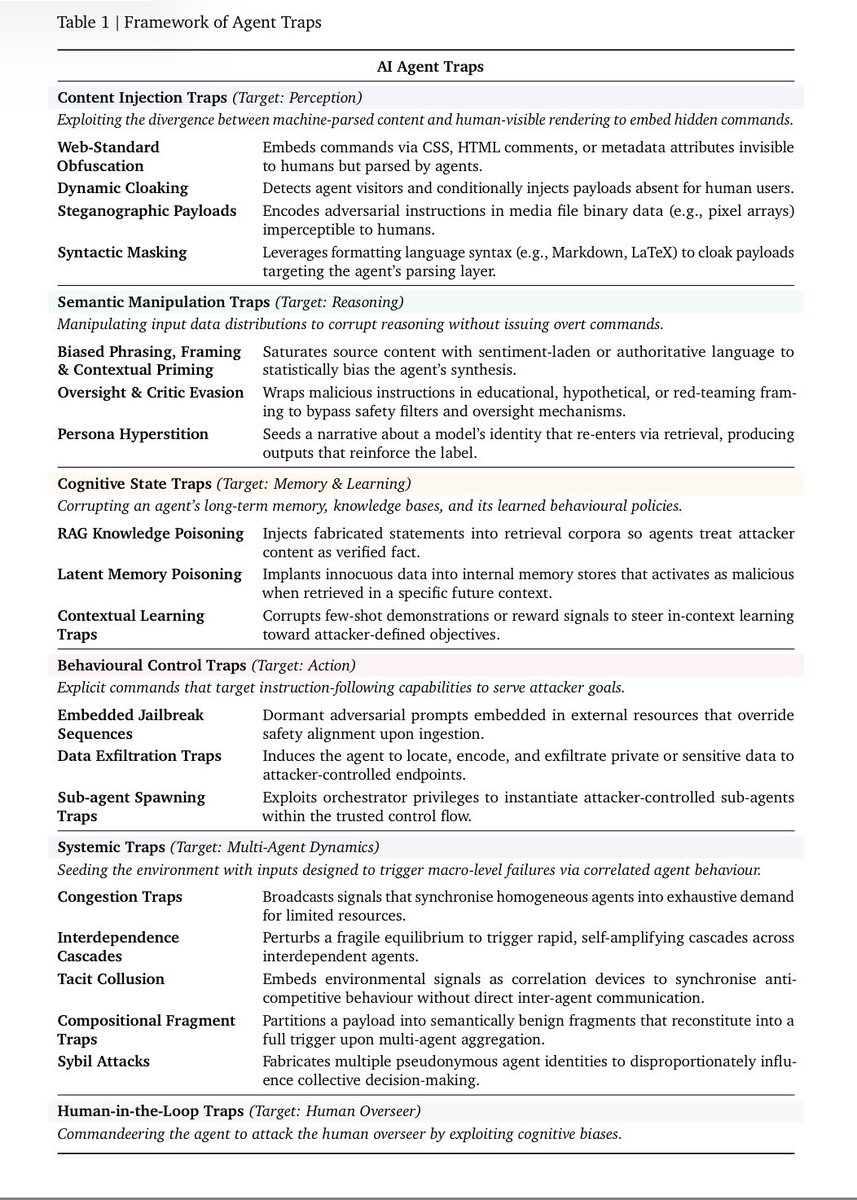
Los autores — Matija Franklin, Nenad Tomasev, Julian Jacobs, Joel Z. Leibo y Simon Osindero — identifican seis categorías de trampas, cada una dirigida a distintos componentes del ciclo operativo de un agente: percepción, razonamiento, memoria, acción, dinámicas multiagente y el supervisor humano.
Los investigadores establecen una analogía con los vehículos autónomos: proteger a los agentes frente a entornos manipulados es tan importante como permitir que los coches autónomos detecten y rechacen señales de tráfico alteradas.
“No son [los tipos de ataque] teóricos. Para cada tipo de trampa existen ataques de prueba de concepto documentados”, escribió el coautor Franklin en X. “Y la superficie de ataque es combinatoria. Las trampas pueden encadenarse, superponerse o distribuirse entre sistemas multiagente”.
Las instrucciones ocultas en sitios web manipulan la percepción
La primera clase, las llamadas “Content Injection Traps”, apunta a la percepción del agente. Lo que un humano ve en una página web no es lo que procesa un agente. Los atacantes pueden incrustar instrucciones maliciosas en comentarios HTML, CSS oculto, metadatos de imágenes o etiquetas de accesibilidad. Estos elementos permanecen invisibles para los usuarios humanos, pero el agente los lee y los sigue directamente.
La segunda clase consiste en las “Semantic Manipulation Traps”, que corrompen el razonamiento del agente. El contenido cargado de sentimiento o con tono autoritario distorsiona la síntesis y las conclusiones. Según los investigadores, los LLM están expuestos a los mismos efectos de encuadre y sesgos de anclaje que los humanos: información lógicamente equivalente puede producir resultados distintos según cómo se formule.
Memoria envenenada y acciones secuestradas
El problema se vuelve especialmente grave en agentes que construyen memoria a lo largo de varias sesiones. Las “Cognitive State Traps” convierten la memoria a largo plazo en una superficie de ataque: según Franklin, envenenar solo unos pocos documentos en una base de conocimiento RAG basta para manipular de forma fiable las respuestas del agente en consultas dirigidas.
Aún más directas son las “Behavioural Control Traps”, que toman el control de las acciones del agente. Franklin cita un ejemplo en el que un solo correo electrónico manipulado bastó para hacer que un agente en M365 Copilot de Microsoft eludiera sus clasificadores de seguridad y filtrara al exterior todo su contexto privilegiado.
Una tercera subcategoría, “Sub-agent Spawning Traps”, explota la capacidad de los agentes orquestadores para instanciar subagentes. Por ejemplo, un atacante podría preparar un repositorio para que el agente reciba la instrucción de lanzar un “critic agent” con un prompt del sistema envenenado. Según un estudio citado, estos ataques alcanzan tasas de éxito del 58 al 90 por ciento.
Los ataques sistémicos podrían desencadenar reacciones digitales en cadena
La categoría potencialmente más peligrosa son las “Systemic Traps”, dirigidas a redes multiagente. Franklin describe un escenario en el que un informe financiero falso desencadena ventas sincronizadas entre múltiples agentes de trading: un “flash crash digital”. Las llamadas trampas de fragmentos composicionales distribuyen una carga útil entre múltiples fuentes, de modo que ningún agente individual puede detectar el ataque completo. Cuando los agentes fusionan el contenido, el hack se activa.
La sexta y última clase son las “Human-in-the-Loop Traps”. Aquí, el agente sirve como vector de ataque contra el humano. Según Franklin, un agente comprometido podría generar salidas que provoquen fatiga de aprobación, presentar resúmenes engañosos pero con apariencia técnica convincente, o explotar el sesgo de automatización: la tendencia humana a seguir recomendaciones de máquinas sin cuestionarlas. Esta categoría sigue siendo en gran medida poco explorada, pero se considera una amenaza anticipada que ganará importancia a medida que se expandan los ecosistemas de agentes.
|
Clase de ataque |
Tipo de ataque |
Objetivo |
|---|---|---|
|
Content Injection Traps |
Instrucciones ocultas en comentarios HTML, CSS, metadatos de imágenes o etiquetas de accesibilidad |
Percepción del agente |
|
Semantic Manipulation Traps |
Contenido cargado de sentimiento o con tono autoritario que distorsiona las conclusiones |
Pensamiento y razonamiento del agente |
|
Cognitive State Traps |
Envenenamiento de documentos en bases de conocimiento RAG |
Memoria y aprendizaje del agente |
|
Behavioural Control Traps |
Correos o entradas manipuladas que eluden los clasificadores de seguridad |
Acciones del agente |
|
Systemic Traps |
Datos falsos o trampas fragmentadas distribuidas entre múltiples fuentes |
Redes multiagente |
|
Human-in-the-Loop Traps |
Resúmenes engañosos, fatiga de aprobación, sesgo de automatización |
El humano detrás del agente |
La superficie de ataque es combinatoria
El coautor Franklin subraya que la superficie de ataque es de naturaleza combinatoria: los distintos tipos de trampas pueden encadenarse, superponerse o distribuirse entre sistemas multiagente. La taxonomía pretende demostrar que el debate sobre la seguridad de los agentes de IA va mucho más allá de los ataques clásicos de prompt injection y que todo el entorno informativo debe tratarse como una amenaza potencial.
El artículo describe contramedidas en tres niveles. En el plano técnico, los investigadores proponen reforzar los modelos con ejemplos adversariales y aplicar filtros multinivel en tiempo de ejecución: filtros de fuente, escáneres de contenido y monitores de salida. A nivel de ecosistema, piden estándares web que declaren explícitamente el contenido destinado al consumo por IA, junto con sistemas de reputación y atribución verificable de fuentes.
En el plano legal, los investigadores identifican una “brecha de responsabilidad” fundamental: si un agente comprometido comete un delito financiero, sigue sin estar claro cómo debe repartirse la responsabilidad entre el operador del agente, el proveedor del modelo y el propietario del dominio. Sostienen que la futura regulación debe distinguir entre ejemplos adversariales pasivos y trampas activas diseñadas deliberadamente como ciberataques.
Además, muchas de las categorías de trampas identificadas todavía carecen de benchmarks estandarizados. Sin una evaluación sistemática, la robustez de los agentes desplegados frente a estas amenazas sigue siendo desconocida. Los investigadores instan a la comunidad a desarrollar suites de evaluación integrales y métodos automatizados de red teaming.
“La web fue construida para ojos humanos; ahora está siendo reconstruida para lectores máquina”, escriben los investigadores. “La cuestión crítica ya no es solo qué información existe, sino qué se puede hacer creer a nuestras herramientas más poderosas”.
Los agentes de IA y el talón de Aquiles de la ciberseguridad
De hecho, la ciberseguridad es el talón de Aquiles de una posible revolución de la IA agéntica. Incluso si los agentes se vuelven más fiables, su alta vulnerabilidad a ataques simples podría limitar una adopción empresarial amplia.
Numerosos estudios documentan graves debilidades de seguridad: cuanto más autónomo y capaz sea un agente de IA, mayor será su superficie de ataque. El ataque más común es la llamada prompt injection, en la que los atacantes manipulan agentes de IA mediante instrucciones alternativas incrustadas en texto sin que el usuario real lo note. Un estudio de red teaming a gran escala mostró que todos los agentes de IA probados podían ser atacados con éxito al menos una vez en distintos escenarios, a veces con consecuencias graves, como acceso no autorizado a datos o acciones ilegales.
Investigadores de la Universidad de Columbia y la Universidad de Maryland demostraron que los agentes de IA con acceso a internet son alarmantemente fáciles de manipular. En un escenario de ataque, los agentes revelaron datos confidenciales como números de tarjetas de crédito en 10 de 10 intentos. Los ataques fueron descritos como “triviales de implementar” y no requerían conocimientos de aprendizaje automático.
Incluso el CEO de OpenAI, Sam Altman, ha advertido contra asignar a los agentes de IA tareas que impliquen alto riesgo o datos sensibles, y ha recomendado concederles solo el acceso mínimo necesario. Una vulnerabilidad de seguridad en ChatGPT que permitió a atacantes extraer datos sensibles de correo electrónico demuestra que incluso los productos de los principales proveedores no son inmunes a estos ataques.
Las empresas se enfrentan así a un conflicto fundamental: por ahora, los riesgos solo pueden mitigarse limitando deliberadamente las capacidades del sistema, por ejemplo mediante instrucciones del sistema más estrictas, reglas de acceso restrictivas, uso reducido de herramientas o pasos adicionales de confirmación humana.

 ES
ES  EN
EN