ElevenLabs lidera el benchmark AA-WER 2.0 de reconocimiento de voz
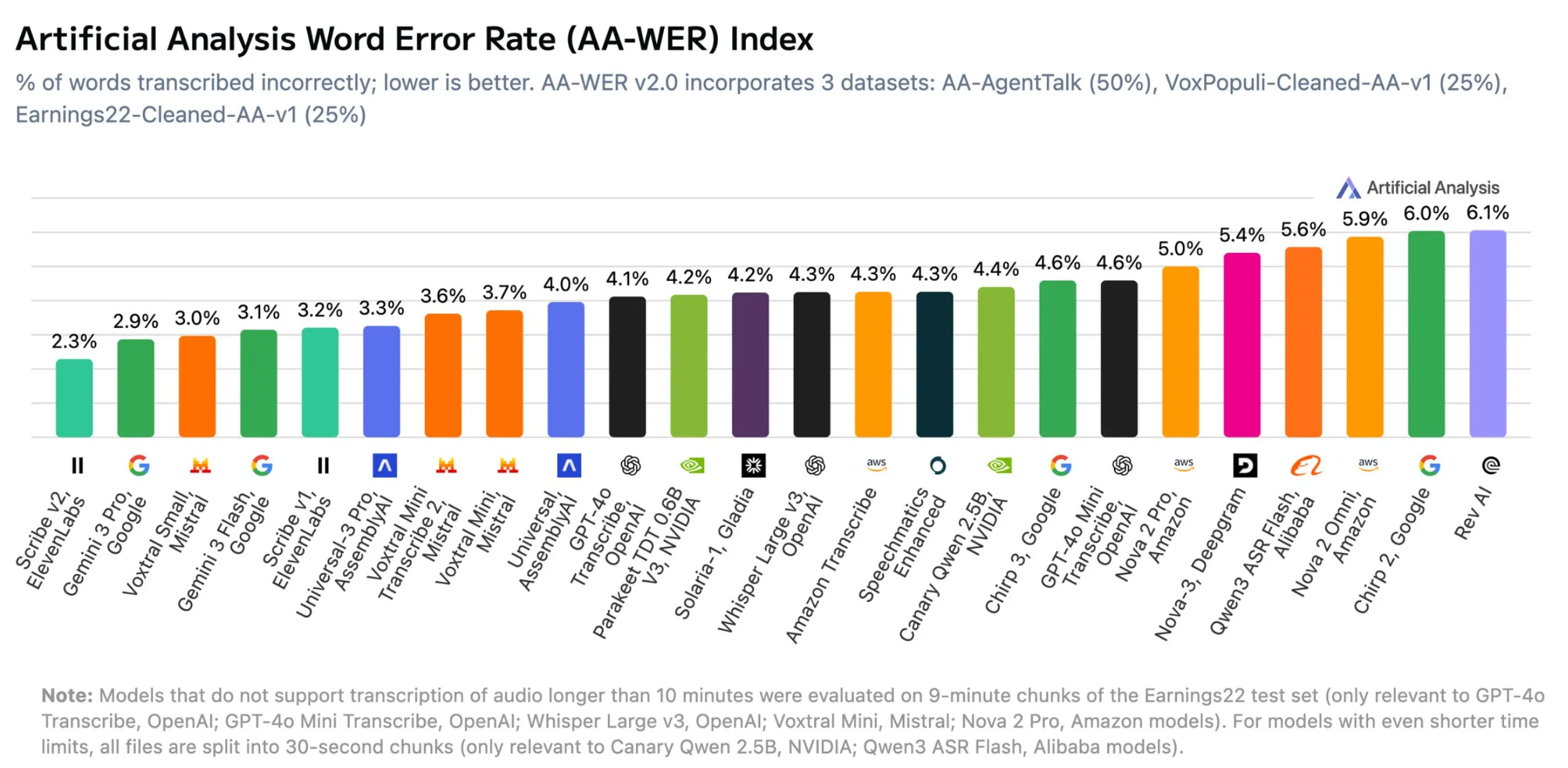
Artificial Analysis ha publicado la versión 2.0 de su benchmark de reconocimiento de voz AA-WER, que mide la precisión de los modelos de transcripción de voz a texto. En la clasificación general, Scribe v2 de ElevenLabs ocupa el primer lugar con una tasa de error de palabras de solo 2,3%.
El segundo y tercer puesto corresponden a Gemini 3 Pro de Google con 2,9% y Voxtral Small de Mistral con 3,0%, respectivamente. Otros modelos con un rendimiento sólido incluyen Google Gemini 3 Flash con 3,1% y Scribe v1 de ElevenLabs con 3,2%. En la zona media del ranking se sitúan modelos como GPT-4o Transcribe de OpenAI con 4,0% y Whisper Large v3 con 4,2%. En los últimos puestos aparecen Qwen3 ASR Flash de Alibaba con 5,9%, Amazon Nova 2 Omni con 6,0% y Rev AI con 6,1%.
ElevenLabs Scribe v2 lidera la clasificación general del benchmark AA-WER v2.0 con la menor tasa de error de palabras, seguido por Google Gemini 3 Pro y Mistral Voxtral Small. | Imagen: Artificial Analysis
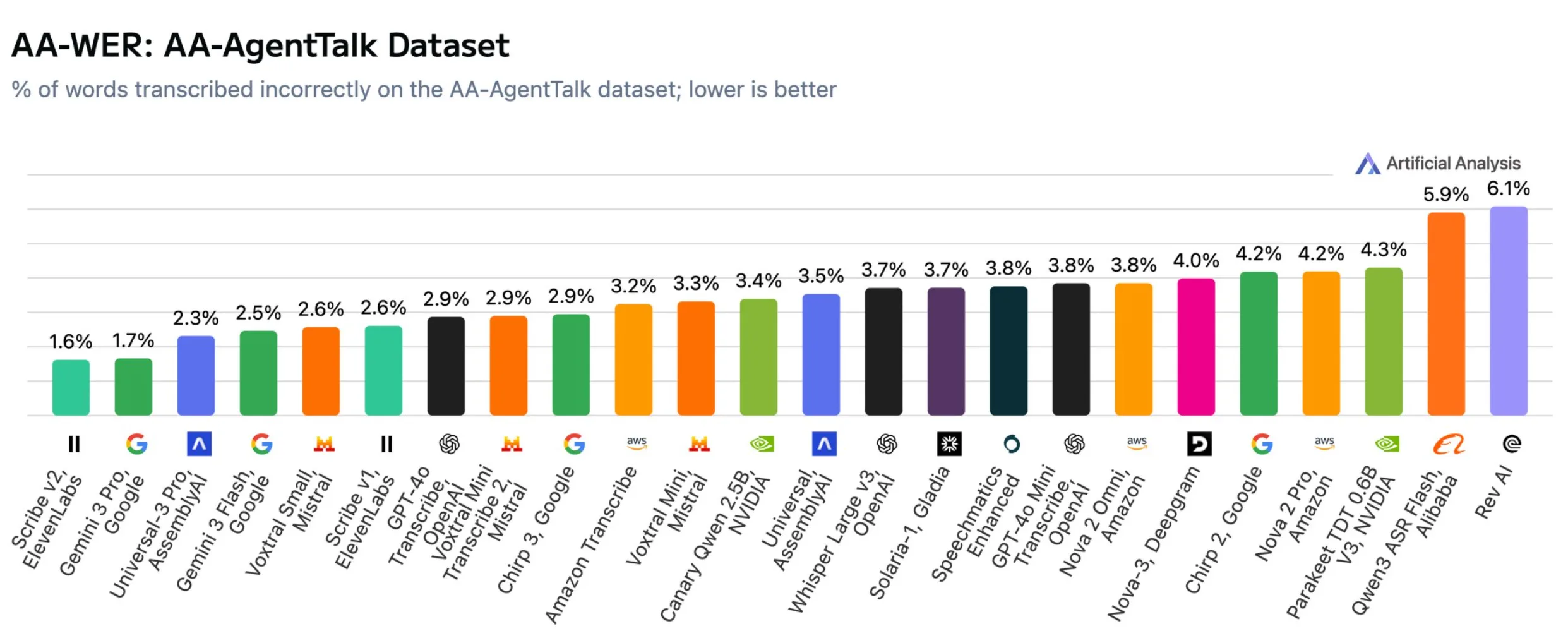
En un benchmark separado centrado específicamente en el habla dirigida a asistentes de voz, el panorama general se mantiene prácticamente igual. Scribe v2 vuelve a liderar con una tasa de error de palabras del 1,6%, seguido muy de cerca por Gemini 3 Pro con 1,7%. Universal-3 Pro de AssemblyAI ocupa el tercer lugar con 2,3%.
En la prueba AA-AgentTalk para lenguaje dirigido a asistentes de voz, Scribe v2 de ElevenLabs y Gemini 3 Pro de Google también dominan con las tasas de error más bajas. | Imagen: Artificial Analysis
Es investigador y analista senior con base en España. Su trabajo se centra en el estudio de modelos tecnológicos a gran escala, su integración en infraestructuras empresariales y las implicaciones económicas y sociales de su adopción.



 ES
ES  EN
EN