
Investigadores de la Universidad de Tsinghua y Microsoft han desarrollado un método para entrenar modelos de IA en tareas avanzadas de programación utilizando exclusivamente datos sintéticos. Su modelo de 7.000 millones de parámetros, X-Coder, supera a competidores del doble de tamaño en el benchmark LiveCodeBench.
Los experimentos demuestran una clara relación entre el tamaño del conjunto de datos y el rendimiento en los benchmarks. Con 32.000 tareas sintéticas de programación, el modelo alcanza una tasa de acierto del 43,7%. Con 64.000 tareas, el rendimiento sube al 51,3%, con 128.000 tareas al 57,2%, y con 192.000 tareas llega al 62,7%.
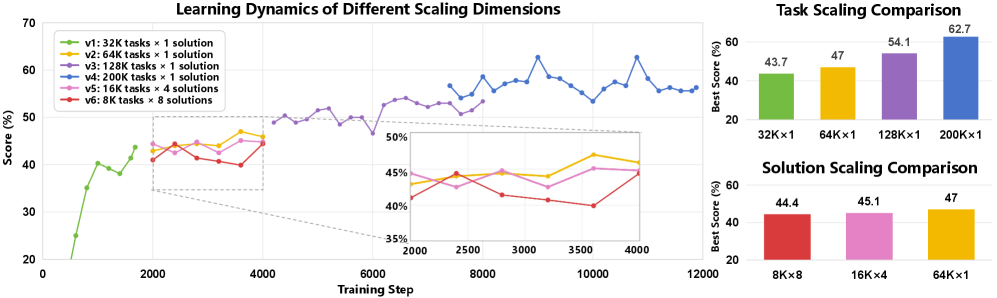
Con el mismo presupuesto computacional, la diversidad de las tareas resulta más importante que el número de soluciones por tarea. Un conjunto de datos con 64.000 tareas distintas y una solución por cada una obtiene mejores resultados que conjuntos con 16.000 tareas y cuatro soluciones o 8.000 tareas con ocho soluciones.
Tareas construidas a partir de componentes modulares
El desarrollo de modelos de código de alto rendimiento suele verse limitado por la escasez de datos de entrenamiento. Las colecciones existentes de tareas de programación competitiva se reutilizan en exceso y ya no son suficientes para impulsar nuevas mejoras. Los enfoques sintéticos anteriores solían reescribir problemas existentes, lo que restringía su diversidad.
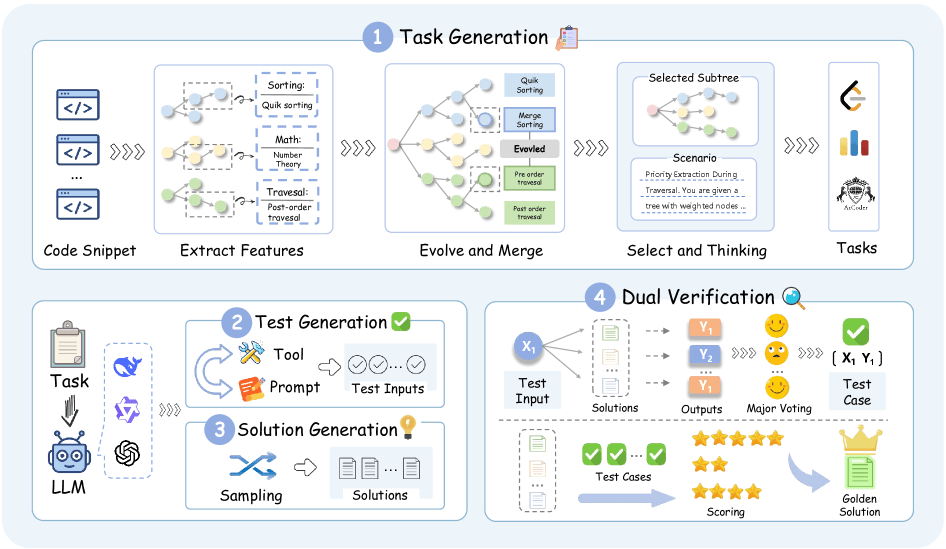
La nueva canalización, denominada SynthSmith, genera tareas, soluciones y casos de prueba completamente desde cero. El proceso comienza con la extracción de características algorítmicas —incluidos algoritmos, estructuras de datos y técnicas de optimización— a partir de 10.000 ejemplos de código existentes. Mediante un proceso evolutivo, el sistema amplía este conjunto de características de 27.400 a casi 177.000 componentes algorítmicos, que luego se recombinan para crear nuevas tareas de programación en distintos estilos.
El control de calidad se realiza en dos etapas. Primero, una votación por mayoría entre múltiples soluciones candidatas determina los resultados correctos. Luego, la mejor solución se valida en un conjunto de prueba independiente para evitar el sobreajuste.
El modelo 7B supera a competidores de 14B
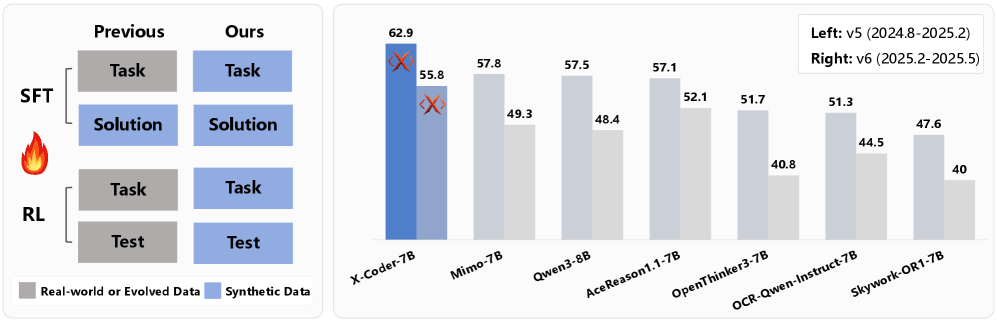
El modelo X-Coder 7B alcanza una tasa media de acierto del 62,9% en LiveCodeBench v5 y del 55,8% en v6, superando a modelos más grandes como DeepCoder-14B-Preview y AReal-boba²-14B, ambos basados en modelos base más potentes.
En comparación con el mayor conjunto de datos público para razonamiento en código, SynthSmith ofrece una mejora de 6,7 puntos, atribuida a tareas más complejas que requieren cadenas de razonamiento más largas. La longitud media del razonamiento alcanza los 17.700 tokens, frente a los 8.000 tokens del conjunto de referencia.
Una fase adicional de aprendizaje por refuerzo incrementa el rendimiento en 4,6 puntos porcentuales. El entrenamiento sigue siendo eficaz incluso con casos de prueba sintéticos que presentan una tasa de error cercana al 5%. Según el artículo, el entrenamiento requirió 128 GPUs H20 durante 220 horas para el ajuste supervisado y 32 GPUs H200 durante siete días para el aprendizaje por refuerzo.
Menor contaminación de los benchmarks
Una ventaja clave del enfoque sintético se observa al comparar distintas versiones de los benchmarks. El modelo de referencia Qwen3-8B cayó de 88,1 a 57,5 entre versiones antiguas y nuevas de LiveCodeBench. En cambio, X-Coder descendió de 78,2 a 62,9, una caída menor de 17,2 puntos, lo que sugiere una menor memorización de las tareas.
Dado que X-Coder se entrenó exclusivamente con datos sintéticos, no pudo memorizar benchmarks anteriores. Los investigadores planean publicar los pesos del modelo, y el código de procesamiento de datos ya está disponible en GitHub.
El interés por los datos sintéticos sigue creciendo en la industria de la IA. El año pasado, la startup Datology AI presentó BeyondWeb, un marco que reescribe documentos web para generar datos de entrenamiento más densos, mientras que Nvidia recurre cada vez más a datos sintéticos en robótica para compensar la escasez de datos reales, convirtiendo así un problema de datos en un problema de cómputo.
Conclusión:
Los resultados demuestran que los datos sintéticos pueden igualar e incluso superar los enfoques tradicionales de entrenamiento para modelos avanzados de programación. Esto abre la puerta a un desarrollo de IA más rápido, económico y escalable, sin depender de enormes conjuntos de datos reales. En AI Wire Media seguiremos de cerca cómo el entrenamiento sintético está transformando el futuro de la investigación y la implementación de la inteligencia artificial.



 ES
ES  EN
EN