
Researchers from Tsinghua University and Microsoft have developed a method for training AI models for advanced programming tasks using exclusively synthetic data. Their 7-billion-parameter model, X-Coder, outperforms competitors twice its size on the LiveCodeBench benchmark.
The experiments demonstrate a clear relationship between dataset size and benchmark performance. With 32,000 synthetic programming tasks, the model achieves a pass rate of 43.7%. At 64,000 tasks, performance rises to 51.3%, at 128,000 tasks to 57.2%, and at 192,000 tasks it reaches 62.7%.
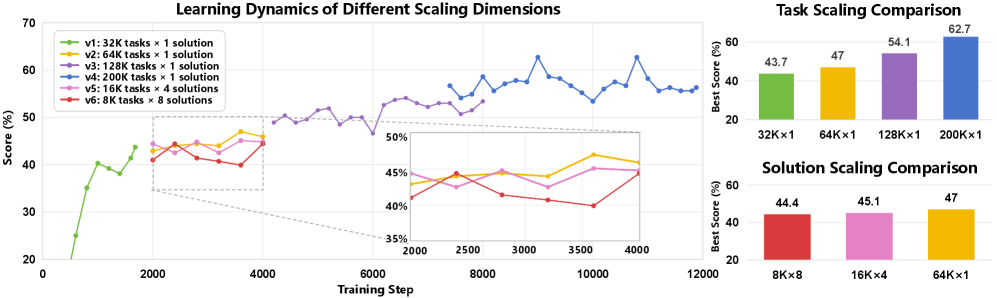
At equal computational budgets, task diversity proves more important than the number of solutions per task. A dataset with 64,000 distinct tasks and one solution each performs better than datasets containing 16,000 tasks with four solutions each or 8,000 tasks with eight solutions each.
Tasks built from modular components
Developing high-performance code models often fails due to limited training data. Existing collections of competitive programming tasks are heavily reused and no longer sufficient to drive further improvements. Previous synthetic approaches typically rewrite existing problems, limiting diversity.
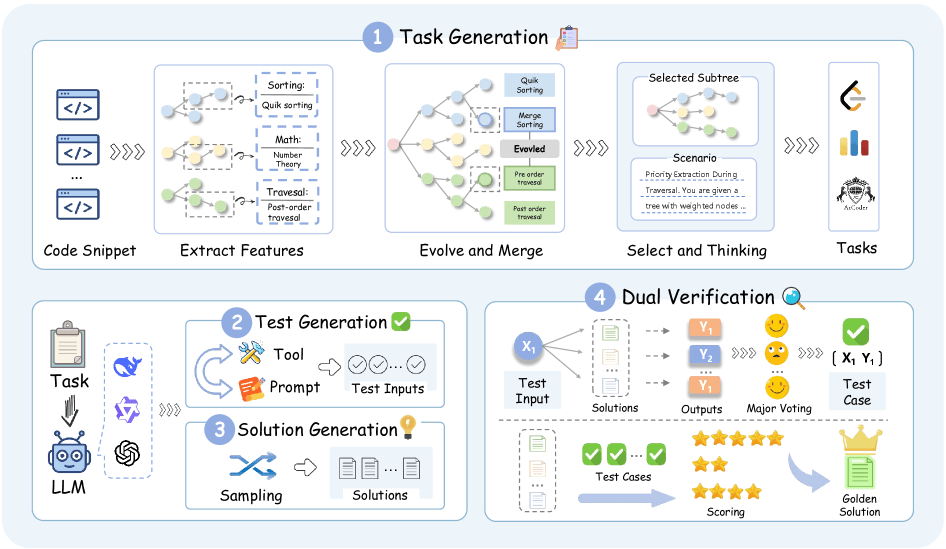
The new pipeline, called SynthSmith, generates tasks, solutions, and test cases entirely from scratch. The process begins by extracting algorithmic features — including algorithms, data structures, and optimization techniques — from 10,000 existing code samples. Through an evolutionary process, the system expands this feature pool from 27,400 to nearly 177,000 algorithmic components, which are then recombined into new programming tasks of varying styles.
Quality control occurs in two stages. First, majority voting across multiple candidate solutions determines the correct outputs. Then, the best solution is validated on a held-out test set to prevent overfitting.
7B model beats 14B competitors
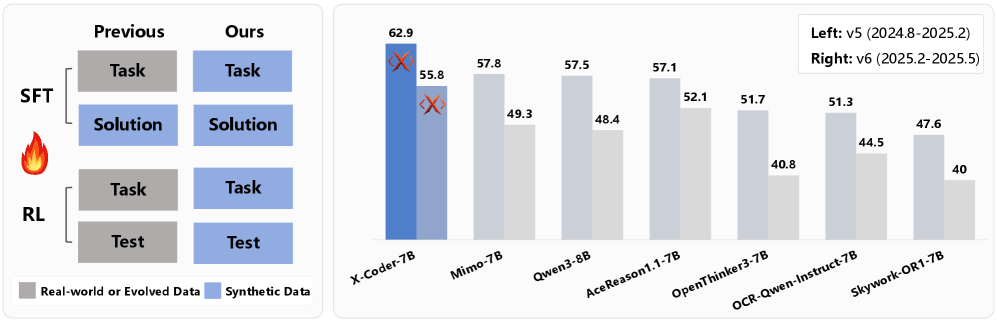
The X-Coder 7B model achieves an average pass rate of 62.9% on LiveCodeBench v5 and 55.8% on v6, outperforming larger models such as DeepCoder-14B-Preview and AReal-boba²-14B, both of which rely on stronger base models.
Compared with the largest publicly available dataset for code reasoning, SynthSmith delivers a 6.7-point improvement, attributed to more complex tasks that require longer reasoning chains. The average reasoning length reaches 17,700 tokens, compared with 8,000 tokens in the reference dataset.
An additional reinforcement-learning phase boosts performance by 4.6 percentage points. Training remains effective even with synthetic test cases containing around 5% error rate. According to the paper, training required 128 H20 GPUs for 220 hours during supervised fine-tuning and 32 H200 GPUs for seven days for reinforcement learning.
Reduced benchmark contamination
A key advantage of the synthetic approach appears in comparisons across benchmark versions. The reference model Qwen3-8B dropped from 88.1 to 57.5 between older and newer LiveCodeBench versions. In contrast, X-Coder declined from 78.2 to 62.9, a smaller drop of 17.2 points, suggesting reduced memorization of benchmark tasks.
Because X-Coder was trained exclusively on synthetic data, it could not have memorized earlier benchmarks. The researchers plan to release the model weights, and the data processing code is already available on GitHub.
Interest in synthetic training data continues to grow across the AI industry. Last year, startup Datology AI introduced BeyondWeb, a framework that rewrites web documents to generate denser training data, while Nvidia increasingly relies on synthetic data in robotics to offset the scarcity of real-world datasets — effectively turning a data problem into a compute problem.
Conclusion:
The results show that synthetic data can rival and even outperform traditional training approaches for advanced coding models. This opens the door to faster, cheaper, and more scalable AI development without dependence on massive real-world datasets. AI Wire Media will continue to track how synthetic training reshapes the future of AI research and deployment.






 ES
ES  EN
EN