




Best Overall
- Best-in-class reasoning and writing
- Strong ecosystem and integrations
- Advanced multimodal capabilities

Suno has introduced its new AI music model v5.5 along with features designed to showcase musical individuality


 By Daniel Mercer
By Daniel Mercer OpenAI is advising users to stop writing excessively long prompts for GPT-5.6 Sol, saying that shorter and more focused instructions can improve accuracy, reduce token usage and lower operating costs.
 By Daniel Mercer
By Daniel Mercer OpenAI has officially unveiled its new generation of AI models, GPT-5.6, alongside the ChatGPT Work task assistant, marking the next stage of the artificial intelligence race. The GPT-5.6 family consists of three versions: Sol, the premium model; Terra, the balanced option; and Luna, the lower-cost version, each targeting a different customer segment.
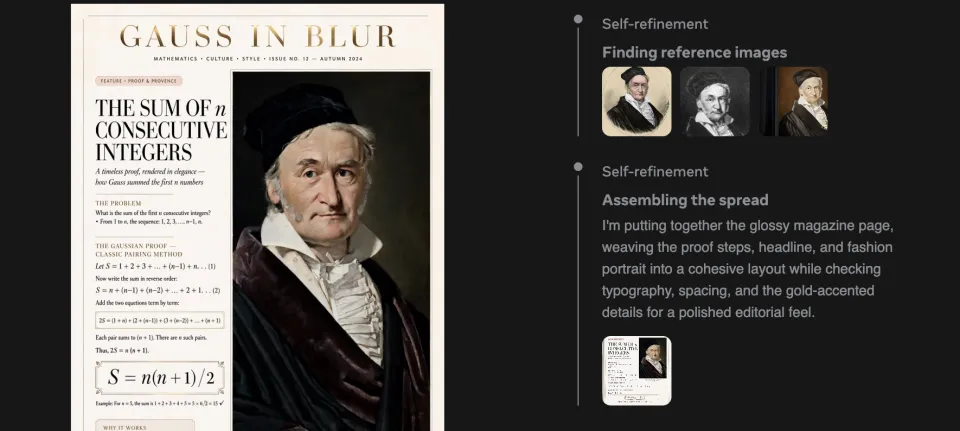 By Daniel Mercer
By Daniel Mercer Meta Superintelligence Labs has launched the Muse Image image-generation model and also previewed Muse Video. Muse Image has already been integrated into Meta’s AI apps, the web and several regional social media platforms, while Muse Video will soon be made available to content creators.

 By Chris Borden
By Chris Borden OpenAI is reportedly set to officially release GPT-5.6 Sol this week while expanding its trial program globally.
 By Daniel Mercer
By Daniel Mercer The artificial intelligence race is heating up, and Google is reportedly preparing to unveil a new “strategic card.” According to information shared on X by the account @HarshithLucky3, Google is expected to officially introduce the Gemini 3.5 Pro model on July 17.
 By Chris Borden
By Chris Borden Shortly after officially changing its name, Elon Musk’s SpaceXAI has officially unveiled Grok 4.5. The model is being positioned as a new “workhorse,” with Musk promising performance comparable to powerful Opus-class models but at a significantly lower cost for users.
 By Chris Borden
By Chris Borden Meta has released an artificial intelligence (AI) model called Muse Spark, marking its “first step” toward a comprehensive overhaul in this field.
 By Daniel Mercer
By Daniel Mercer Chinese startup Zhipu AI has released its flagship language model GLM-5.2 for long agentic tasks and programming. The open-source solution has a 1 million-token context window, an MIT license, and support for local deployment.

 By Alex Rowland
By Alex Rowland On June 9, Anthropic released two versions from the same Claude model family. The company describes Fable 5 as a Mythos-class solution that is safe for general use. Claude Mythos 5 is a “private” base model with reduced restrictions in selected areas.

 ES
ES  EN
EN