

Codex-Spark is the first outcome of the partnership with Cerebras announced in January. The model runs on Cerebras’ Wafer Scale Engine 3, an AI accelerator designed for ultra-fast inference.
The research preview is initially available to ChatGPT Pro users via the Codex app, the CLI, and the VS Code extension. OpenAI plans to gradually expand access over the coming weeks. Because the model relies on specialized hardware, separate rate limits apply and may be adjusted during periods of high demand.
While OpenAI’s larger frontier models are designed to work autonomously for minutes or even hours on increasingly complex programming tasks, Codex-Spark follows a different approach. According to OpenAI, it is optimized for interactive workflows where low latency is just as important as intelligence. Developers can interrupt, redirect, and see results from the model in real time.
Codex-Spark is intentionally conservative in its behavior: by default, it makes minimal, targeted changes and does not run automated tests unless explicitly instructed to do so. The model supports a 128k context window and processes text only.
Faster, but less precise than the larger model
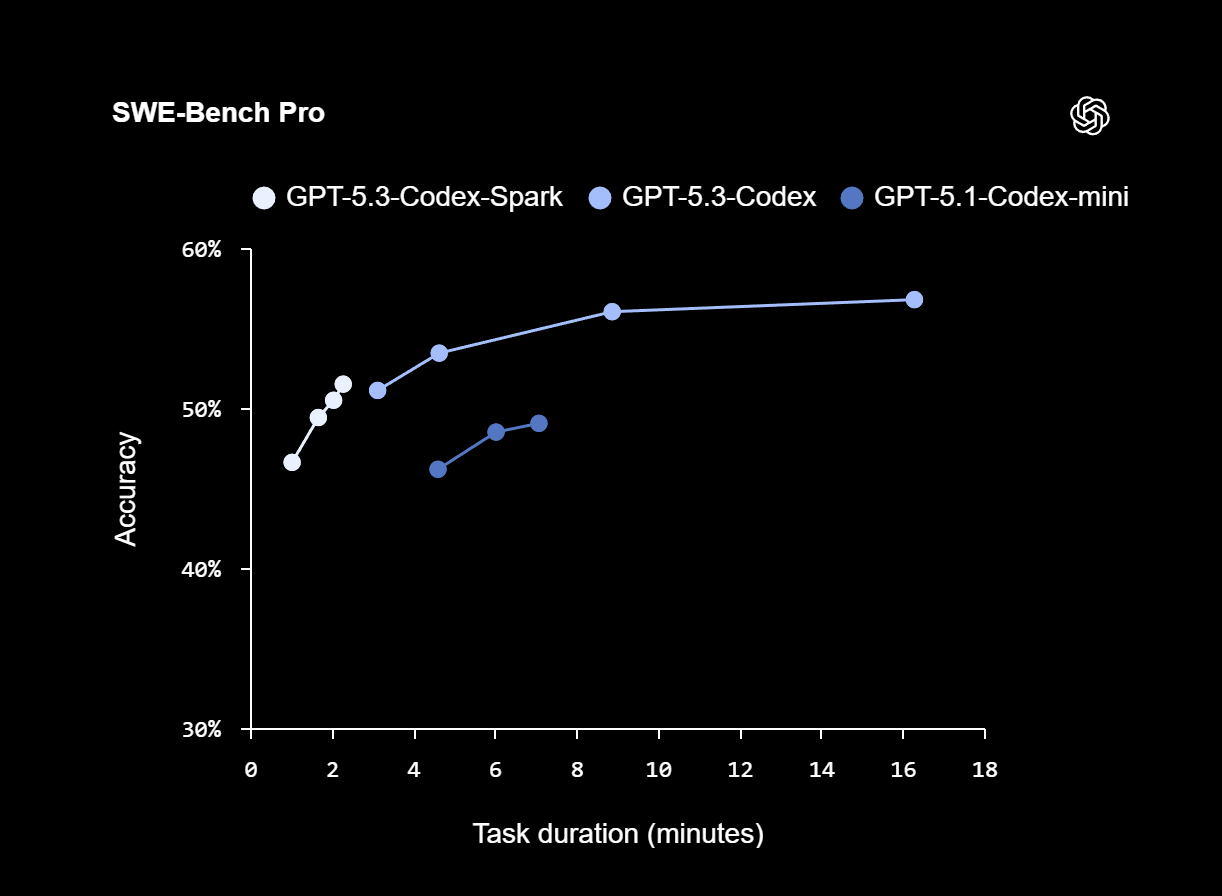
On the SWE-Bench Pro and Terminal-Bench 2.0 benchmarks, which evaluate agent-based software engineering capabilities, Codex-Spark delivers strong results while requiring only a fraction of the time needed by GPT-5.3-Codex. On SWE-Bench Pro, Codex-Spark achieves comparable accuracy with an estimated task duration of around two to three minutes, compared with roughly 15 to 17 minutes for GPT-5.3-Codex.
On Terminal-Bench 2.0, Codex-Spark reaches an accuracy of 58.4%. The larger GPT-5.3-Codex scores 77.3%, while the older GPT-5.1-Codex-mini comes in at 46.1%. The smaller models therefore trade some precision for significantly higher speed.
Real-time and reasoning modes are set to converge
According to OpenAI, Codex-Spark is the first model in a planned family of “ultra-fast” models. Additional capabilities, including larger variants, longer context windows, and multimodal inputs, are expected to follow.
In the long term, OpenAI plans to support two complementary operating modes for Codex: one focused on long-term reasoning and autonomous execution, and another centered on real-time collaboration. These modes are expected to merge over time, allowing Codex to keep users in a fast interactive loop while delegating longer tasks to background sub-agents or distributing work across multiple models in parallel.

 ES
ES  EN
EN