

Codex-Spark es el primer resultado de la alianza con Cerebras anunciada en enero. El modelo se ejecuta sobre el Wafer Scale Engine 3 de Cerebras, un acelerador de IA diseñado para inferencia ultrarrápida.
La vista previa de investigación está disponible inicialmente para usuarios de ChatGPT Pro a través de la aplicación Codex, la interfaz de línea de comandos (CLI) y la extensión para VS Code. OpenAI planea ampliar el acceso de forma gradual en las próximas semanas. Debido al uso de hardware especializado, se aplican límites de uso específicos que pueden ajustarse en periodos de alta demanda.
Mientras que los modelos “frontier” de mayor tamaño de OpenAI están pensados para trabajar de forma autónoma durante minutos u horas en tareas de programación cada vez más complejas, Codex-Spark adopta un enfoque distinto. Según OpenAI, está optimizado para flujos de trabajo interactivos en los que la baja latencia es tan importante como la inteligencia. Los desarrolladores pueden interrumpir, redirigir y ver resultados del modelo en tiempo real.
Codex-Spark es deliberadamente conservador en su comportamiento: por defecto realiza cambios mínimos y precisos, y no ejecuta pruebas automáticas salvo que se le indique explícitamente. El modelo admite una ventana de contexto de 128k y procesa únicamente texto.
Más rápido, pero menos preciso que el modelo de mayor tamaño
En los benchmarks SWE-Bench Pro y Terminal-Bench 2.0, que evalúan capacidades de ingeniería de software basadas en agentes, Codex-Spark ofrece resultados sólidos utilizando solo una fracción del tiempo requerido por GPT-5.3-Codex. En SWE-Bench Pro, Codex-Spark alcanza una precisión comparable con una duración estimada de las tareas de entre dos y tres minutos, frente a los aproximadamente 15 a 17 minutos que necesita GPT-5.3-Codex.
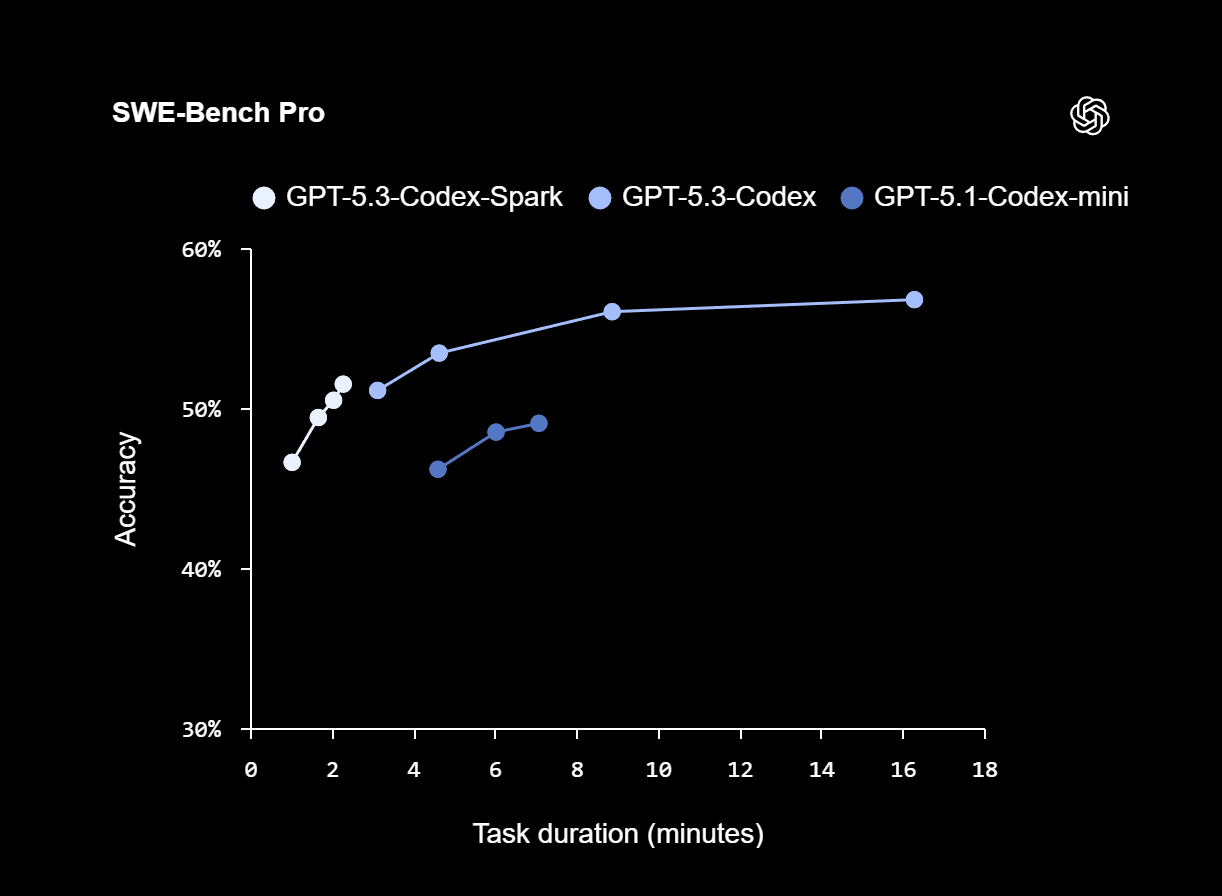
En Terminal-Bench 2.0, Codex-Spark logra una precisión del 58,4%. El modelo más grande GPT-5.3-Codex alcanza el 77,3%, mientras que el más antiguo GPT-5.1-Codex-mini se sitúa en el 46,1%. Así, los modelos más pequeños sacrifican parte de la precisión a cambio de una velocidad significativamente mayor.
Convergencia entre modos en tiempo real y razonamiento
Según OpenAI, Codex-Spark es el primer modelo de una futura familia de modelos “ultrarrápidos”. Está previsto que se añadan nuevas capacidades, incluidas variantes de mayor tamaño, ventanas de contexto más largas y entradas multimodales.
A largo plazo, OpenAI planea ofrecer dos modos de funcionamiento complementarios para Codex: uno centrado en el razonamiento a largo plazo y la ejecución autónoma, y otro orientado a la colaboración en tiempo real. Con el tiempo, ambos modos deberían converger, permitiendo que Codex mantenga a los usuarios en un bucle interactivo rápido mientras delega tareas más largas a subagentes en segundo plano o distribuye el trabajo entre varios modelos en paralelo.

 ES
ES  EN
EN