

La empresa china de IA DeepSeek ha presentado un novedoso codificador de visión que reorganiza la información de las imágenes de forma semántica, en lugar de procesarla rígidamente de arriba a la izquierda hacia abajo a la derecha.
Los modelos convencionales de visión y lenguaje dividen las imágenes en pequeños fragmentos y los procesan en una secuencia fija, normalmente escaneando desde la esquina superior izquierda hasta la inferior derecha. Según los investigadores de DeepSeek, este enfoque contradice la forma en que los humanos perciben realmente las imágenes. La visión humana sigue patrones flexibles guiados por el contenido: al seguir una espiral, por ejemplo, el ojo no se mueve línea por línea, sino que sigue la forma.
Con DeepSeek OCR 2, la compañía introduce un nuevo enfoque. El denominado DeepEncoder V2 procesa primero los tokens visuales en función del contenido, reorganizándolos según relaciones semánticas antes de que un modelo de lenguaje interprete la información. La idea subyacente es que dos etapas de procesamiento secuenciales puedan permitir conjuntamente una comprensión más auténtica de las estructuras visuales bidimensionales.
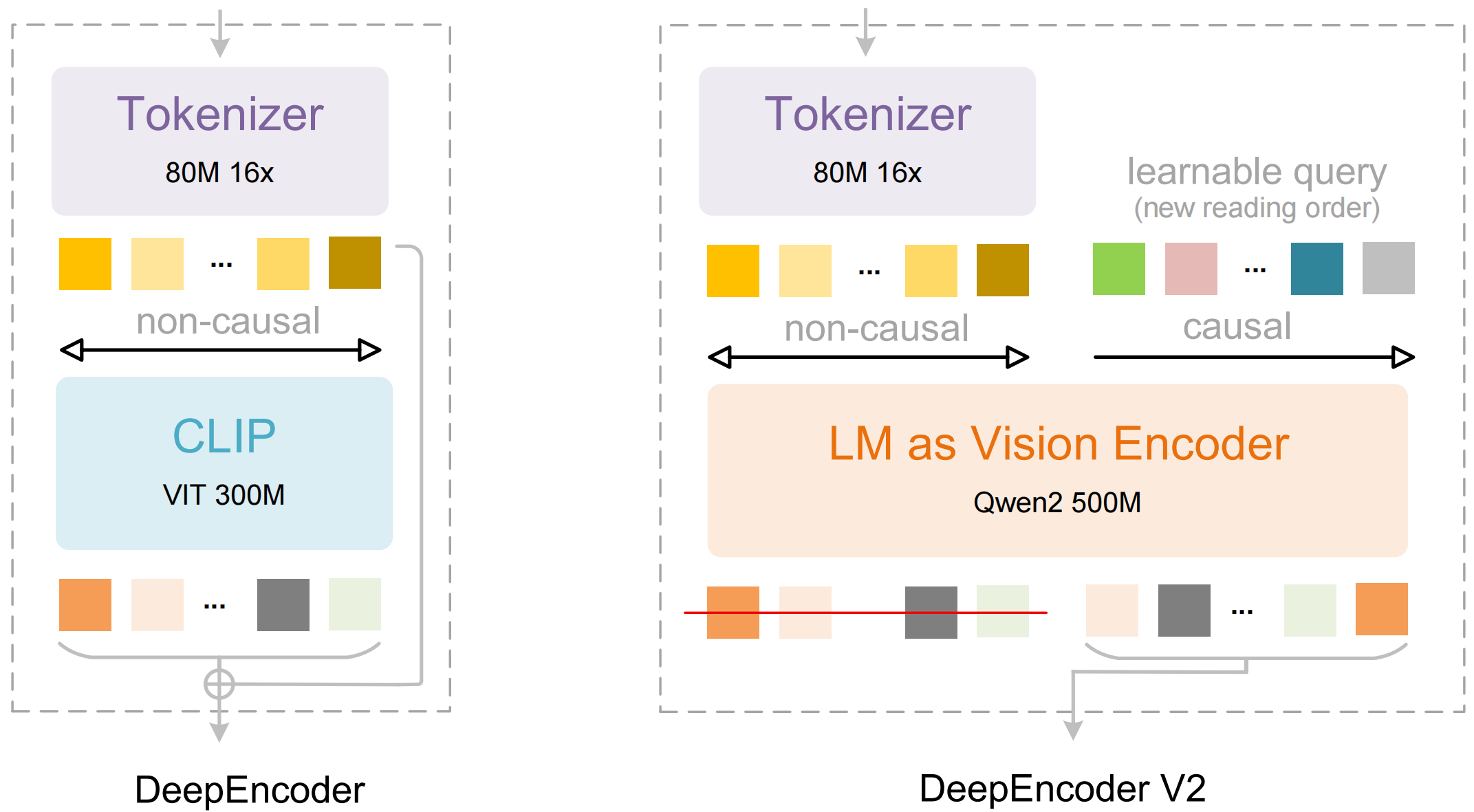
La arquitectura de modelos de lenguaje reemplaza al codificador de visión clásico
En el núcleo de DeepEncoder V2 se encuentra un alejamiento del componente CLIP tradicional. DeepSeek lo sustituye por una arquitectura compacta de modelo de lenguaje basada en Qwen2 0.5B de Alibaba. Para ello, los investigadores introducen los llamados Causal Flow Tokens, tokens de consulta entrenables que se añaden a los tokens visuales y pueden atender a toda la información de la imagen, así como a todas las consultas anteriores.
Este mecanismo da lugar a una canalización de dos etapas. Primero, el codificador reorganiza la información visual según criterios semánticos. Luego, un decodificador LLM posterior razona sobre la secuencia ya ordenada. De forma crucial, solo los Causal Flow Tokens reorganizados se transfieren al decodificador, no los tokens visuales originales.
Menos tokens, mayor rendimiento
Dependiendo de la imagen, DeepSeek OCR 2 opera con entre 256 y 1.120 tokens visuales, mientras que modelos comparables suelen requerir más de 6.000 o incluso 7.000 tokens. En OmniDocBench v1.5, un benchmark de comprensión documental que abarca 1.355 páginas en nueve categorías, el modelo alcanza una puntuación global del 91,09%, según los investigadores.
Esto supone una mejora de 3,73 puntos porcentuales respecto a la versión anterior de DeepSeek OCR. Las mejoras son especialmente notables en la identificación correcta del orden de lectura. En tareas de análisis de documentos, DeepSeek OCR 2 también supera a Gemini 3 Pro con un presupuesto de tokens similar.
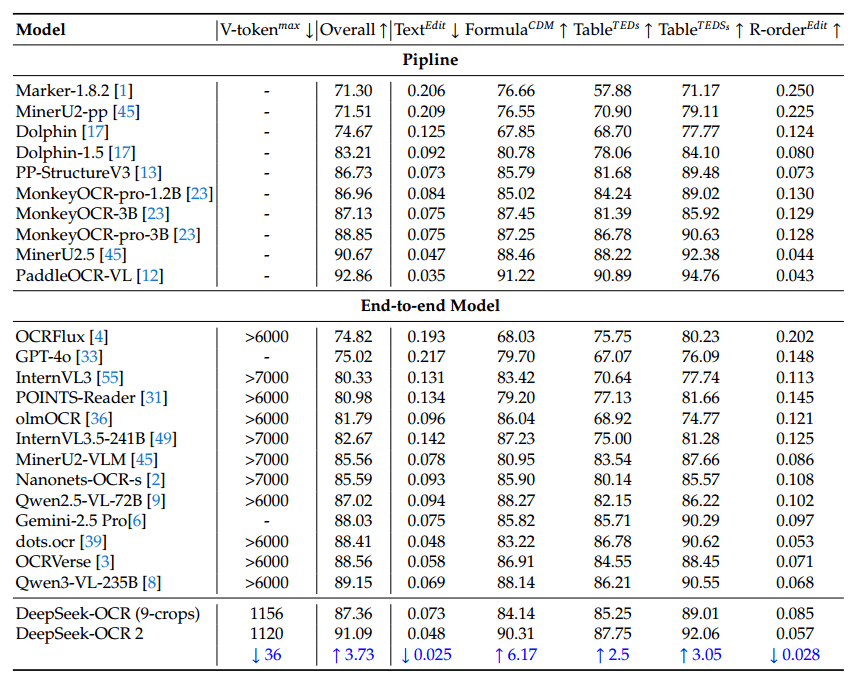
En el uso práctico, también mejoraron las tasas de repetición —la frecuencia con la que el modelo cae en bucles de texto redundantes—. Cuando se utiliza como servicio OCR para los modelos de lenguaje de DeepSeek, la tasa de repetición se redujo de 6,25% a 4,17%. En el procesamiento por lotes de PDF para datos de entrenamiento, descendió de 3,69% a 2,88%. No obstante, el artículo señala debilidades en ciertos tipos de documentos. Los periódicos, por ejemplo, muestran un rendimiento inferior al del modelo anterior.
Los investigadores atribuyen esto a dos factores: el límite inferior de tokens puede resultar restrictivo para páginas de periódicos con mucho texto y los datos de entrenamiento incluían solo 250.000 páginas de periódicos, lo que podría ser insuficiente para esa categoría.
Hacia una arquitectura multimodal unificada
Los investigadores de DeepSeek consideran DeepEncoder V2 como un paso hacia un marco de procesamiento multimodal unificado. En el futuro, la arquitectura del codificador podría manejar texto, voz e imágenes dentro de la misma estructura subyacente, adaptando únicamente los tokens de consulta para cada modalidad. A largo plazo, este enfoque podría permitir una comprensión más auténtica del contenido bidimensional.



 ES
ES  EN
EN