

The Chinese AI company DeepSeek has unveiled a novel vision encoder that semantically reorders image information instead of processing it rigidly from top left to bottom right.
Conventional vision-language models break images into small patches and process them in a fixed sequence, typically scanning from the upper-left corner to the lower-right. According to DeepSeek’s researchers, this approach contradicts how humans actually perceive images. Human vision follows flexible, content-driven patterns: when tracing a spiral, for example, the eye does not move line by line but follows the shape itself.
With DeepSeek OCR 2, the company introduces a new approach. The so-called DeepEncoder V2 processes visual tokens based on content first, reordering them by semantic relationships before a language model interprets the information. The underlying idea is that two sequential processing stages can jointly enable a more genuine understanding of two-dimensional visual structures.
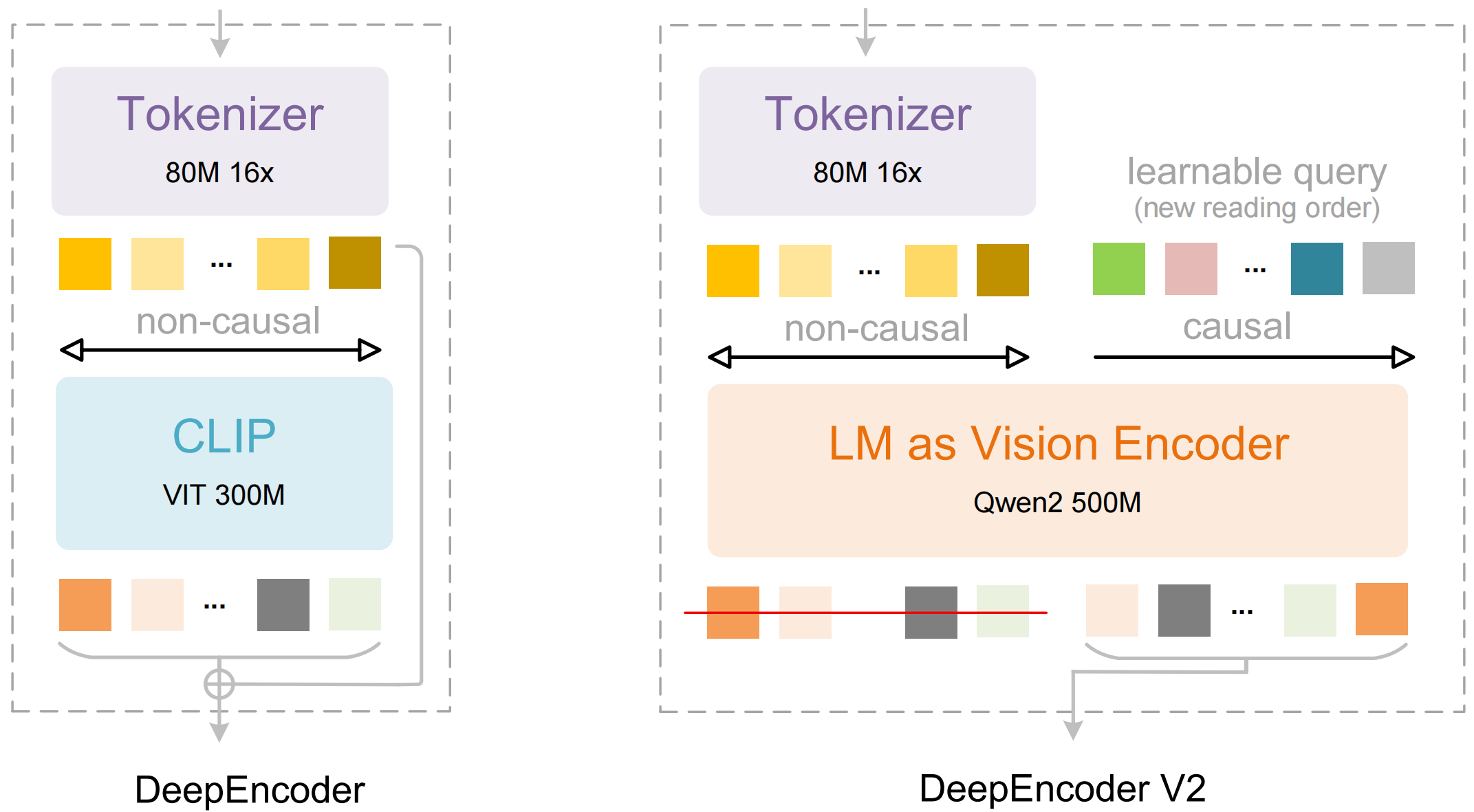
Language-model architecture replaces the classic vision encoder
At the core of DeepEncoder V2 is a departure from the traditional CLIP component. DeepSeek replaces it with a compact language-model architecture based on Alibaba’s Qwen2 0.5B. To enable this, the researchers introduce so-called Causal Flow Tokens—learnable query tokens that are appended to the visual tokens and can attend to all image information as well as all previous queries.
This mechanism results in a two-stage pipeline. First, the encoder reorganizes visual information according to semantic criteria. Then, a downstream LLM decoder reasons over the already sorted sequence. Crucially, only the reordered Causal Flow Tokens are passed to the decoder, not the original visual tokens.
Fewer tokens, stronger performance
Depending on the image, DeepSeek OCR 2 operates with 256 to 1,120 visual tokens, whereas comparable models often require more than 6,000 or even 7,000 tokens. On OmniDocBench v1.5—a document understanding benchmark covering 1,355 pages across nine categories—the model achieves an overall score of 91.09%, according to the researchers.
This represents an improvement of 3.73 percentage points over the previous DeepSeek OCR version. Gains are particularly pronounced in correctly identifying reading order. In document parsing tasks, DeepSeek OCR 2 also outperforms Gemini 3 Pro while operating under a similar token budget.
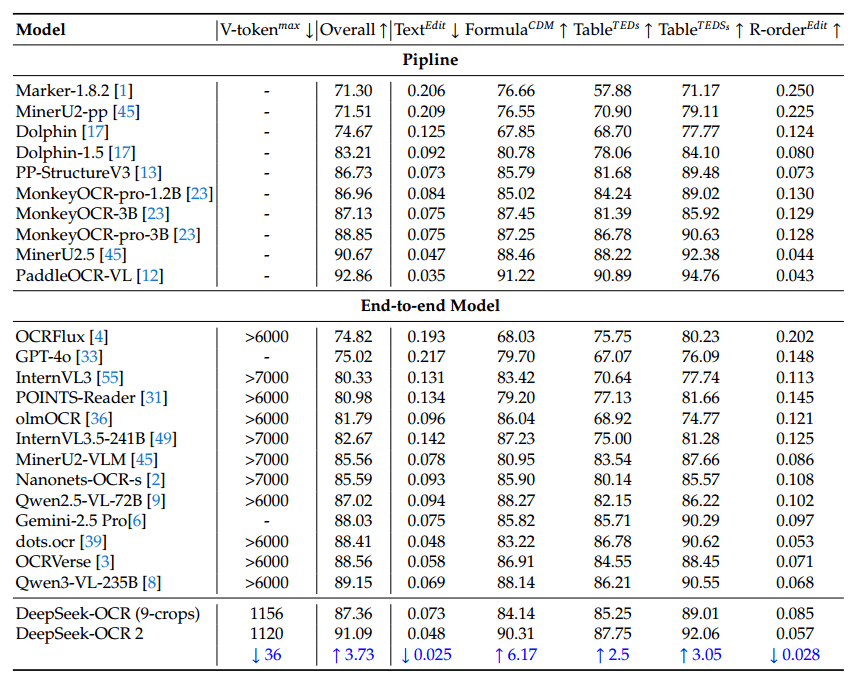
In practical use, repetition rates—how often the model falls into redundant text loops—have also improved. When used as an OCR service for DeepSeek’s language models, the repetition rate dropped from 6.25% to 4.17%. In batch PDF processing for training data, it fell from 3.69% to 2.88%. However, the paper notes weaknesses with certain document types. Newspapers, for example, perform worse than with the previous model.
The researchers attribute this to two factors: the lower token ceiling can be limiting for text-heavy newspaper pages, and the training data included only 250,000 newspaper pages, which may be insufficient for that category.
Toward a unified multimodal architecture
DeepSeek’s researchers see DeepEncoder V2 as a step toward a unified multimodal processing framework. In the future, the encoder architecture could potentially handle text, speech, and images within the same underlying structure, adapting only the query tokens for each modality. Over the long term, the approach could enable a more genuine understanding of two-dimensional content






 ES
ES  EN
EN