

Un modelo fundacional de bioacústica de Google DeepMind, entrenado en gran parte con vocalizaciones de aves, supera a modelos entrenados específicamente en ballenas a la hora de clasificar sonidos de animales bajo el agua. La explicación de este fenómeno llega incluso al terreno de la biología evolutiva.
Dado que el contacto visual bajo el agua suele ser imposible, el comportamiento de ballenas y delfines se estudia con frecuencia a través de sus vocalizaciones. Sin embargo, desarrollar clasificadores de IA fiables para sonidos submarinos resulta complejo. La recopilación de datos requiere equipos especializados y costosos, y en algunos casos nuevos tipos de sonidos no se atribuyen a una especie concreta hasta décadas después de haber sido registrados por primera vez.
Un equipo de Google DeepMind y Google Research demuestra ahora en un artículo científico que un enfoque muy distinto puede funcionar. Su modelo fundacional de bioacústica, Perch 2.0, entrenado principalmente con sonidos de aves, supera de forma consistente a todos los modelos de comparación en la clasificación de cantos de ballenas, incluido un modelo de Google entrenado específicamente para ballenas.
Un modelo de aves reconoce ballenas
El modelo Perch 2.0, con 101,8 millones de parámetros, fue entrenado con más de 1,5 millones de grabaciones de sonidos animales que abarcan al menos 14.500 especies. La mayoría corresponden a aves, complementadas con insectos, mamíferos y anfibios. Las grabaciones submarinas están prácticamente ausentes en los datos de entrenamiento. Según el estudio, solo hay alrededor de una docena de grabaciones de ballenas, en su mayoría captadas desde la superficie con teléfonos móviles.
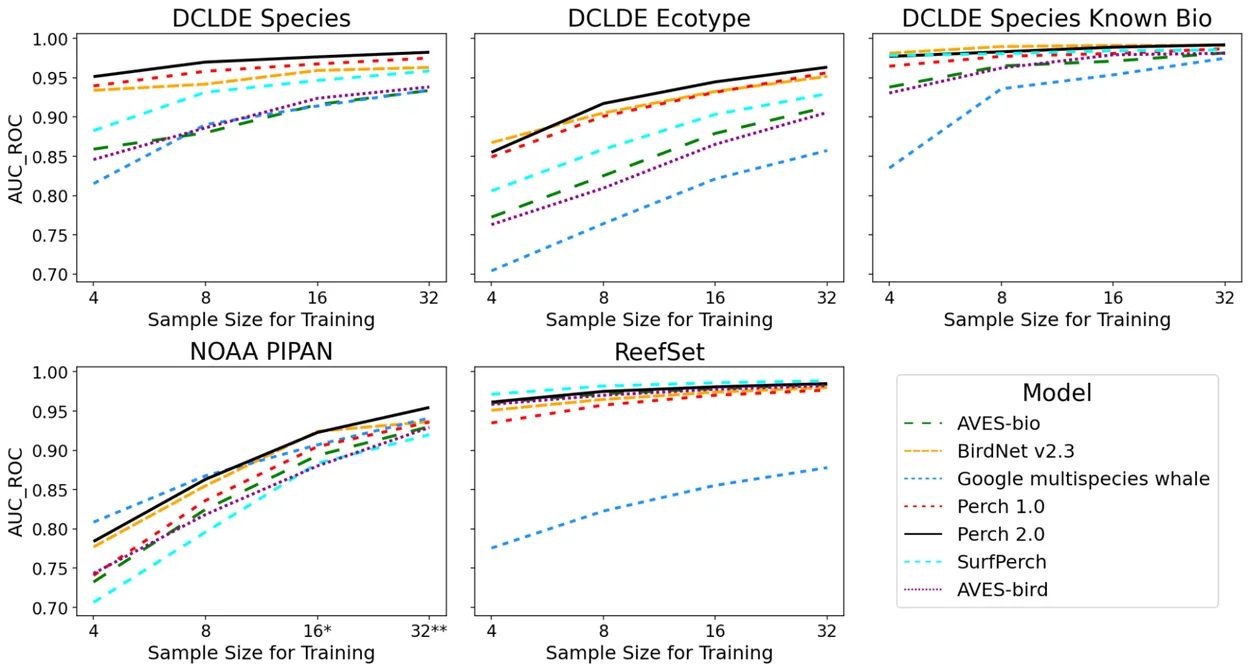
Para evaluar el rendimiento del modelo entrenado con aves bajo el agua, los investigadores lo probaron con tres conjuntos de datos marinos: uno que incluye distintas especies de ballenas barbadas del Pacífico (NOAA PIPAN), otro con sonidos de arrecifes como chasquidos y gruñidos (ReefSet) y un tercero con más de 200.000 vocalizaciones anotadas de orcas y ballenas jorobadas (DCLDE 2026).
El modelo genera para cada grabación una representación numérica compacta, conocida como embedding. A partir de estos embeddings, se entrena un clasificador sencillo con solo un pequeño número de ejemplos etiquetados para asignar los sonidos a las especies correctas.

La IA especializada en ballenas rinde peor
Los investigadores compararon Perch 2.0 con otros seis modelos, incluido el Multispecies Whale Model (GMWM) de Google, entrenado específicamente con ballenas. El rendimiento se midió mediante la métrica AUC-ROC, donde 1,0 representa una discriminación perfecta.
Perch 2.0 se sitúa como el mejor o segundo mejor modelo en casi todas las tareas. Al distinguir distintas subpoblaciones de orcas a partir de sus vocalizaciones, alcanza un AUC-ROC de 0,945, frente a 0,821 del modelo específico para ballenas. En la clasificación general de sonidos submarinos, Perch 2.0 logra 0,977, mientras que el GMWM obtiene 0,914, utilizando en ambos casos solo 16 ejemplos de entrenamiento por categoría.
La diferencia es aún más marcada cuando el GMWM se utiliza directamente como clasificador en lugar de para aprendizaje por transferencia: su rendimiento cae a 0,612. Los investigadores sugieren que el modelo podría haberse sobreajustado a micrófonos específicos u otras características de sus datos de entrenamiento. En conjunto, la especialización en un dominio estrecho parece reducir la capacidad de generalización.
La “lección del bittern” en bioacústica
Los autores proponen tres explicaciones para esta sorprendente transferencia entre dominios.
En primer lugar, se aplican las leyes de escalado neuronal: los modelos más grandes, entrenados con mayores volúmenes de datos, generalizan mejor, incluso en tareas fuera de su dominio original.
En segundo lugar, introducen la llamada “lección del bittern”, un juego de palabras entre la especie de ave “bittern” y la conocida “Bitter Lesson”. La clasificación de aves es especialmente exigente porque las diferencias entre especies suelen ser extremadamente sutiles. Solo en Norteamérica existen 14 especies de palomas con arrullos ligeramente distintos. Un modelo capaz de distinguir de forma fiable estas diferencias finas aprende características acústicas que se transfieren bien a tareas completamente distintas.
En tercer lugar, existe una explicación evolutiva. Aves y mamíferos marinos desarrollaron de manera independiente mecanismos similares de producción de sonido, conocidos como el mecanismo mioelástico-aerodinámico. Esta base física compartida podría explicar por qué las características acústicas se transfieren con tanta eficacia entre estos grupos animales.
Clasificadores rápidos para nuevos descubrimientos
La relevancia práctica reside en lo que los investigadores denominan “modelado ágil”. Los datos acústicos pasivos pueden integrarse en una base de datos vectorial, y los clasificadores lineales entrenados sobre embeddings precomputados pueden crearse en cuestión de horas. Esto es especialmente importante en la bioacústica marina, donde se descubren nuevos tipos de sonidos de forma constante. Por ejemplo, el misterioso sonido conocido como “biotwang” solo fue atribuido posteriormente a las ballenas de Bryde.
Google ha publicado un tutorial completo de extremo a extremo en Google Colab y ha puesto las herramientas a disposición del público en GitHub.



 ES
ES  EN
EN