

GLM-5 cuenta con un total de 744.000 millones de parámetros, de los cuales 40.000 millones están activos durante la inferencia. Su arquitectura Mixture-of-Experts es casi el doble de grande que la de su predecesor, GLM-4.5, que tenía 355.000 millones de parámetros. El conjunto de entrenamiento también se ha ampliado de forma significativa, pasando de 23 billones a 28,5 billones de tokens. Según Zhipu AI, el modelo integra DeepSeek Sparse Attention (DSA) para reducir los costes de despliegue sin sacrificar el rendimiento en contextos largos.
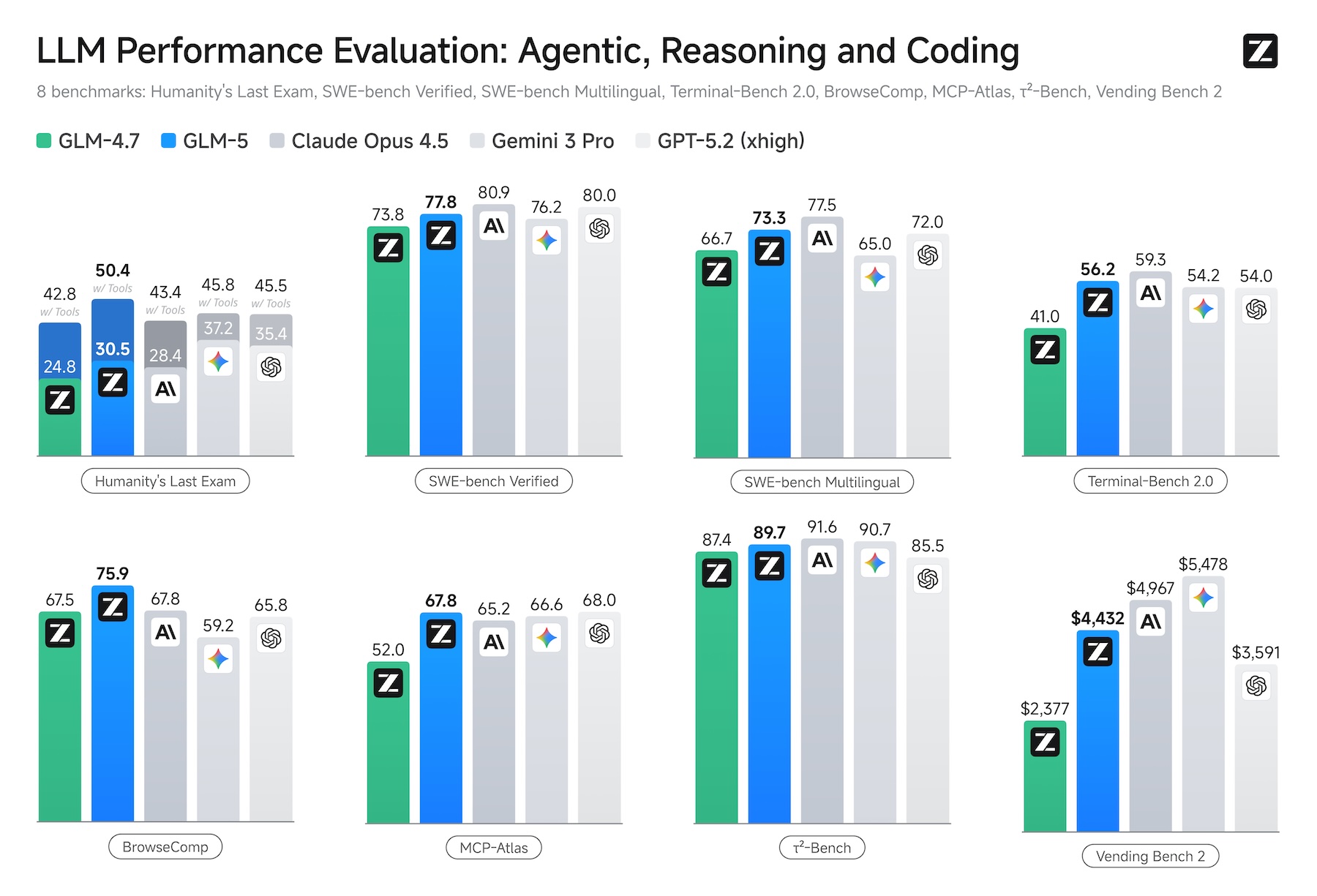
En las comparativas de benchmarks publicadas por la compañía, GLM-5 se sitúa junto a Claude Opus 4.5, Gemini 3 Pro y GPT-5.2 en ocho evaluaciones que abarcan razonamiento, programación y cargas de trabajo basadas en agentes, incluyendo Humanity’s Last Exam, SWE-bench Verified, BrowseComp y Vending Bench 2.
Zhipu AI resume su ambición de forma clara: los modelos fundacionales están pasando del “chat” al “trabajo”. En lugar de limitarse al diálogo, GLM-5 está pensado para construir sistemas complejos y realizar planificación a largo plazo. Este enfoque refleja la dirección que siguen los principales laboratorios de IA occidentales. Los pesos del modelo se publican bajo la licencia MIT, una de las licencias de código abierto más permisivas.
Evaluación de agentes mediante un negocio de máquinas expendedoras simulado
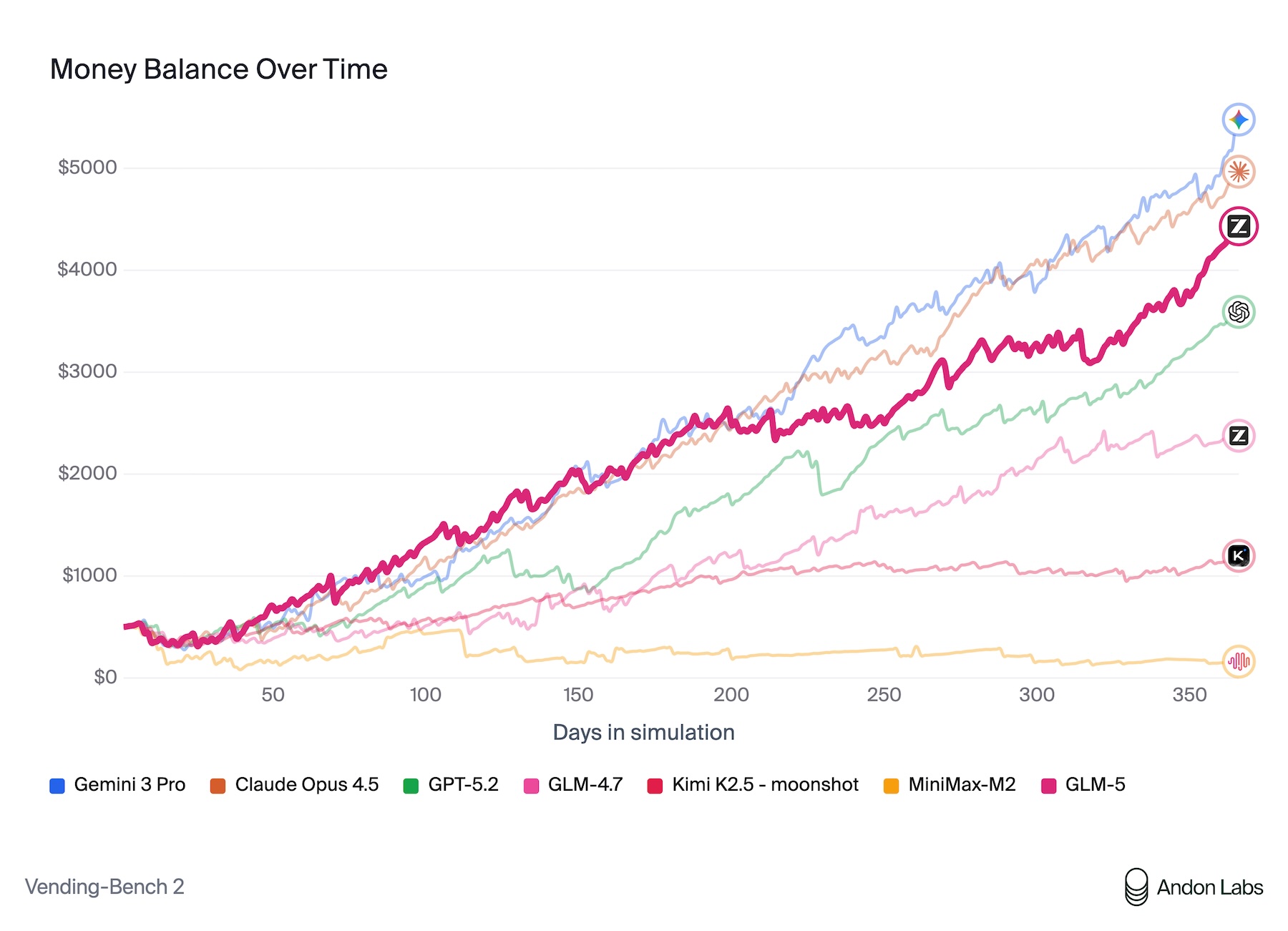
Según los propios benchmarks de Zhipu AI, GLM-5 ofrece los mejores resultados entre los modelos de código abierto en razonamiento, programación y tareas basadas en agentes. Una de las evaluaciones más ilustrativas es Vending Bench 2, en la que un modelo debe gestionar un negocio simulado de máquinas expendedoras durante un año completo.
En esta prueba, GLM-5 alcanzó un saldo final de 4.432 dólares, acercándose al rendimiento de Claude Opus 4.5, que obtuvo 4.967 dólares. El benchmark fue realizado por Andon Labs, que también participó en el experimento real de Anthropic, Project Vend, donde Claude Sonnet 3.7 gestionó una tienda de autoservicio y no logró operar de forma rentable.
En SWE-bench Verified, que evalúa tareas de ingeniería de software, GLM-5 alcanzó un 77,8%, superando a DeepSeek-V3.2 y Kimi K2.5, aunque todavía se sitúa ligeramente por detrás de Claude Opus 4.5, con un 80,9%. En BrowseComp, un benchmark centrado en la búsqueda web basada en agentes y la gestión del contexto, GLM-5 supera, según Zhipu AI, a todos los modelos propietarios evaluados, aunque aún no existen validaciones independientes.
Un análisis previo de Stanford sugería que los modelos chinos de IA se retrasaban una media de siete meses respecto a sus homólogos estadounidenses. GLM-5 llega aproximadamente tres meses después de los últimos modelos insignia de Anthropic, Google y OpenAI, reduciendo de forma notable esa brecha.
Del diálogo a los documentos
Según Zhipu AI, GLM-5 puede convertir directamente texto y otras fuentes en archivos finales .docx, .pdf y .xlsx. Su aplicación oficial, Z.ai, incluye un modo Agent con herramientas integradas para la creación de documentos, como propuestas de patrocinio o informes financieros.
El modelo también es compatible con OpenClaw, un marco joven y controvertido para flujos de trabajo entre aplicaciones y dispositivos, así como con agentes de programación consolidados como Claude Code, OpenCode y Roo Code.
GLM-5 se ejecuta en GPUs de Nvidia y también es compatible con chips de fabricantes chinos como Huawei Ascend, Moore Threads y Cambricon. Zhipu AI afirma que las optimizaciones del kernel y la cuantización del modelo permiten un “rendimiento razonable”. Esta flexibilidad de hardware es especialmente relevante para el mercado chino, donde las restricciones de exportación de EE. UU. limitan el acceso a hardware de Nvidia.
Para despliegues locales, GLM-5 es compatible con los frameworks de inferencia vLLM y SGLang, con guías de configuración disponibles en el repositorio de GitHub de Z.ai.
Junto al modelo, Zhipu AI ha publicado slime, un framework de aprendizaje por refuerzo utilizado para entrenar GLM-5. Slime aborda la ineficiencia del aprendizaje por refuerzo en grandes modelos de lenguaje mediante una arquitectura asíncrona que conecta el framework de entrenamiento Megatron con el motor de inferencia SGLang. Además de los modelos de Zhipu, slime es compatible con Qwen3, DeepSeek V3 y Llama 3.
Continúa la carrera entre los laboratorios chinos de IA
Hace poco, Zhipu AI presentó GLM-4.7 con la función “Preserved Thinking”, que conserva cadenas de razonamiento a lo largo de conversaciones extensas. GLM-5 mejora la puntuación de su predecesor en SWE-bench del 73,8% al 77,8%.
Al mismo tiempo, el competidor chino Moonshot AI lanzó Kimi K2.5, un modelo capaz de coordinar hasta 100 subagentes en paralelo mediante los llamados “agent swarms”, logrando resultados destacados en benchmarks basados en agentes. Ambos modelos utilizan arquitecturas Mixture-of-Experts y apuntan al mismo mercado: agentes de IA autónomos con capacidad de planificación a largo plazo.

 ES
ES  EN
EN