

GLM-5 features a total of 744 billion parameters, with 40 billion active at inference time. Its Mixture-of-Experts architecture is nearly twice the size of its predecessor, GLM-4.5, which had 355 billion parameters. The training corpus has also expanded significantly, growing from 23 trillion to 28.5 trillion tokens. According to Zhipu AI, the model integrates DeepSeek Sparse Attention (DSA) to reduce deployment costs without sacrificing performance on long-context tasks.
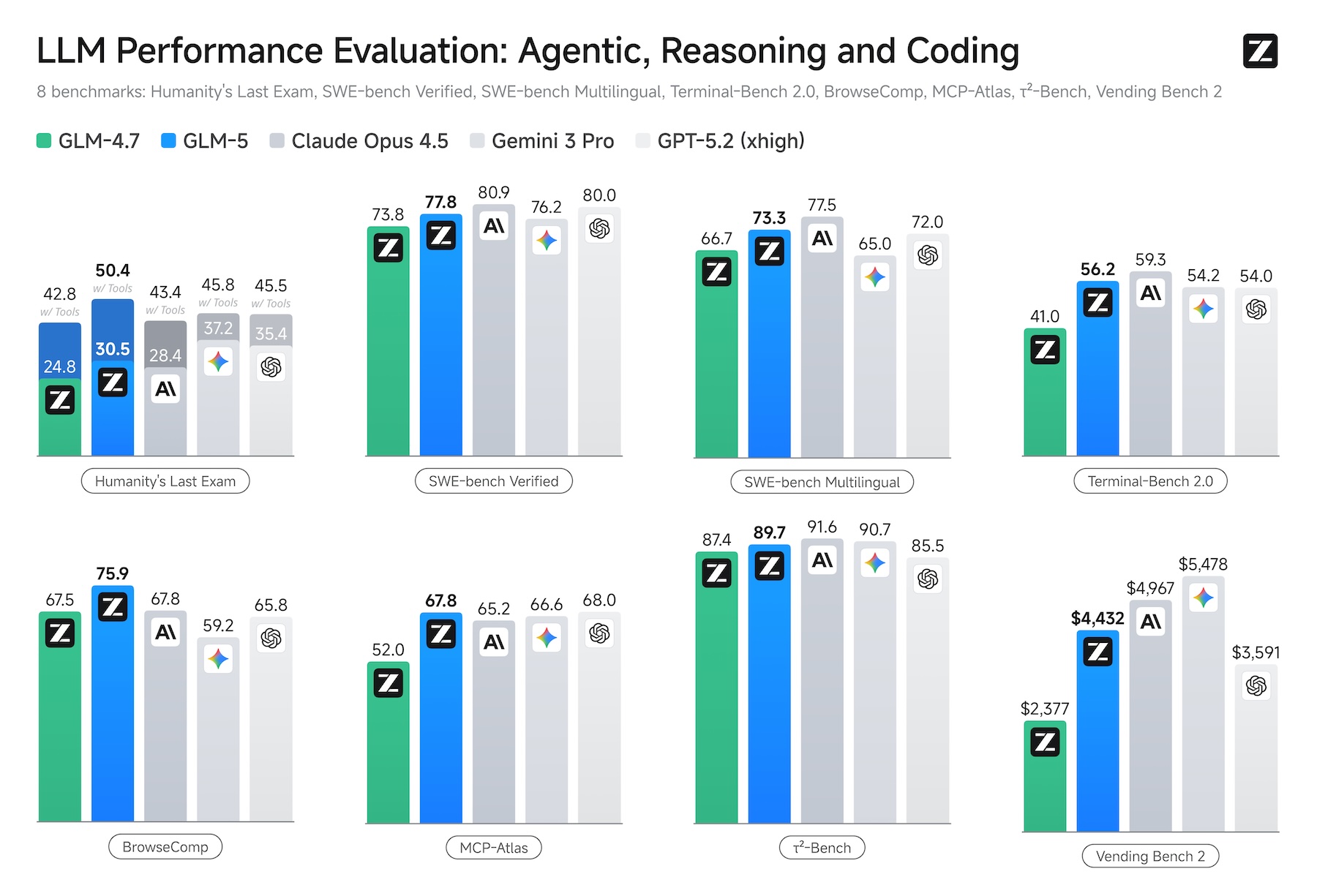
In benchmark comparisons published by the company, GLM-5 is positioned alongside Claude Opus 4.5, Gemini 3 Pro, and GPT-5.2 across eight evaluations covering reasoning, coding, and agent-based workloads, including Humanity’s Last Exam, SWE-bench Verified, BrowseComp, and Vending Bench 2.
Zhipu AI frames its ambition succinctly: foundation models are moving from “chat” to “work.” Rather than merely engaging in dialogue, GLM-5 is intended to build complex systems and perform long-term planning. This positioning mirrors the direction taken by leading Western AI labs. The model weights are released under the MIT license, one of the most permissive open-source licenses available.
Agent evaluation through a simulated vending business
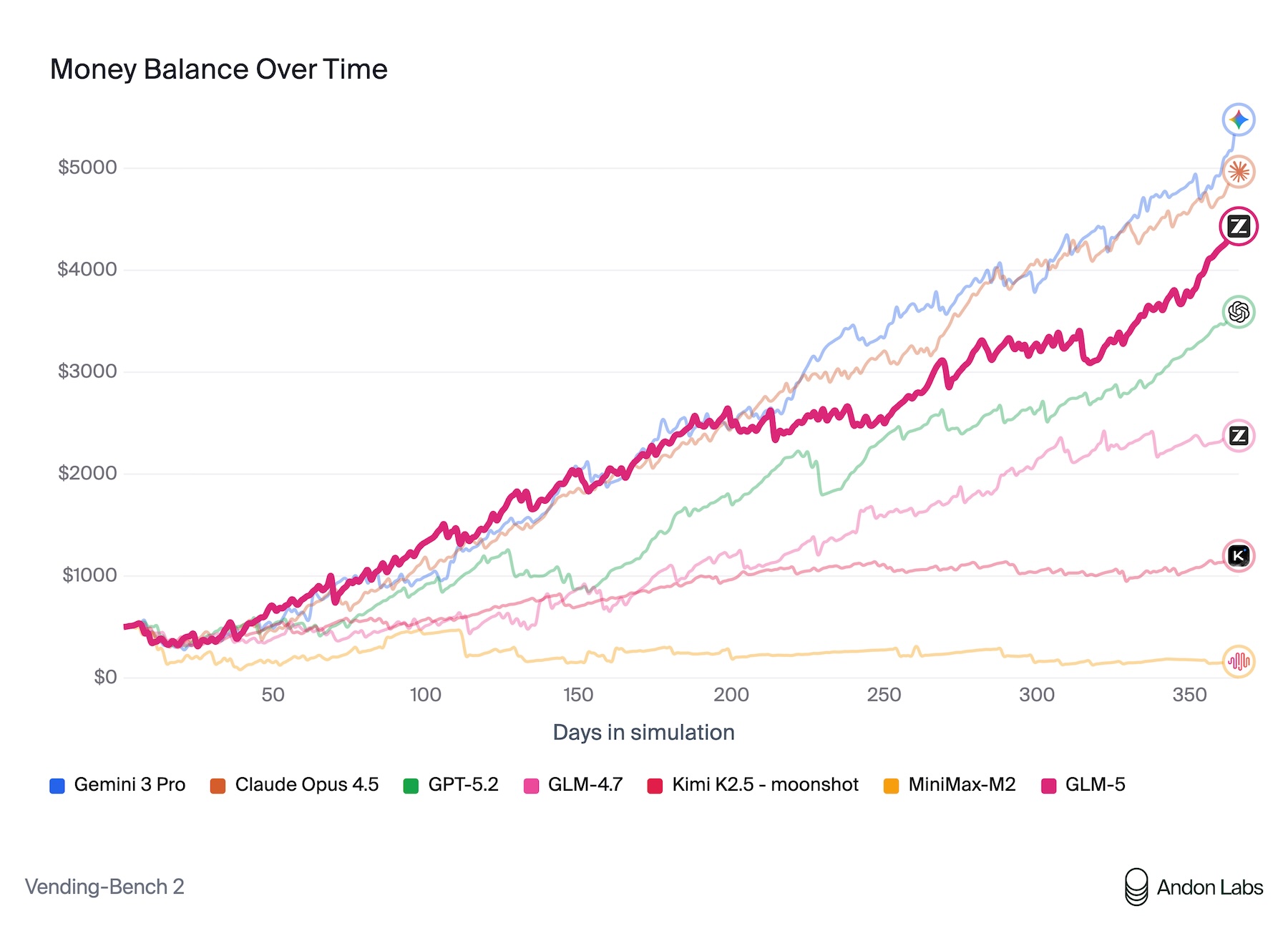
According to Zhipu AI’s own benchmarks, GLM-5 delivers the strongest results among open-source models in reasoning, coding, and agent-based tasks. One of the most illustrative evaluations is Vending Bench 2, where a model must operate a simulated vending machine business over an entire year.
In this test, GLM-5 achieved a final balance of $4,432, approaching the performance of Claude Opus 4.5 at $4,967. The benchmark was conducted by Andon Labs, which also participated in Anthropic’s real-world kiosk experiment, Project Vend, where Claude Sonnet 3.7 managed an actual self-service store and failed to operate it profitably.
On SWE-bench Verified, which evaluates software engineering tasks, GLM-5 reached 77.8%, outperforming DeepSeek-V3.2 and Kimi K2.5, though it still trails Claude Opus 4.5 at 80.9%. In BrowseComp, a benchmark focused on agent-based web search and context management, GLM-5 reportedly surpasses all tested proprietary models, though independent evaluations have not yet been published.
A Stanford analysis previously suggested that Chinese AI models lag behind their U.S. counterparts by an average of seven months. GLM-5 arrives roughly three months after the latest flagship models from Anthropic, Google, and OpenAI, significantly narrowing that gap.
From dialogue to documents
According to Zhipu AI, GLM-5 can directly transform text and other inputs into finished .docx, .pdf, and .xlsx files. Its official application, Z.ai, includes an Agent Mode with built-in tools for document generation, such as sponsorship proposals and financial reports.
The model also supports OpenClaw, a young and controversial framework for cross-application and cross-device workflows, as well as established coding agents such as Claude Code, OpenCode, and Roo Code.
GLM-5 runs on Nvidia GPUs and is also compatible with chips from Chinese manufacturers including Huawei Ascend, Moore Threads, and Cambricon. Zhipu AI says kernel optimizations and model quantization enable “reasonable throughput.” This hardware flexibility is particularly important for the Chinese market, where U.S. export restrictions limit access to Nvidia hardware.
For local deployment, GLM-5 supports the inference frameworks vLLM and SGLang, with setup guides provided via Z.ai’s GitHub repository.
Alongside the model, Zhipu AI has released slime, a reinforcement learning framework used to train GLM-5. Slime addresses the inefficiency of applying reinforcement learning to large language models by using an asynchronous architecture that links the Megatron training framework with the SGLang inference engine. In addition to Zhipu models, slime supports Qwen3, DeepSeek V3, and Llama 3.
The race among Chinese AI labs continues
Only recently, Zhipu AI introduced GLM-4.7 with a “Preserved Thinking” feature that retains reasoning chains across long conversations. GLM-5 improves its predecessor’s SWE-bench score from 73.8% to 77.8%.
At the same time, Chinese rival Moonshot AI has released Kimi K2.5, a model capable of coordinating up to 100 parallel sub-agents via so-called “agent swarms,” achieving strong results in agent-based benchmarks. Both models rely on Mixture-of-Experts architectures and target the same market: autonomous AI agents capable of long-term planning

 ES
ES  EN
EN