

Los modelos de IA tradicionales procesan una imagen en un solo paso: si pasan por alto un detalle, solo les queda “adivinar”. Deepmind quiere cambiar eso con Agentic Vision: el modelo puede hacer zoom, recortar y manipular imágenes paso a paso generando y ejecutando código Python.
El sistema sigue un bucle Think–Act–Observe. Primero analiza la pregunta y la imagen y formula un plan. Luego genera y ejecuta código (por ejemplo, para recortar, rotar o anotar). El resultado se añade al contexto para que el modelo inspeccione los nuevos datos antes de responder. Google afirma que esta ejecución de código mejora los resultados entre un 5% y un 10% en distintos benchmarks de visión.
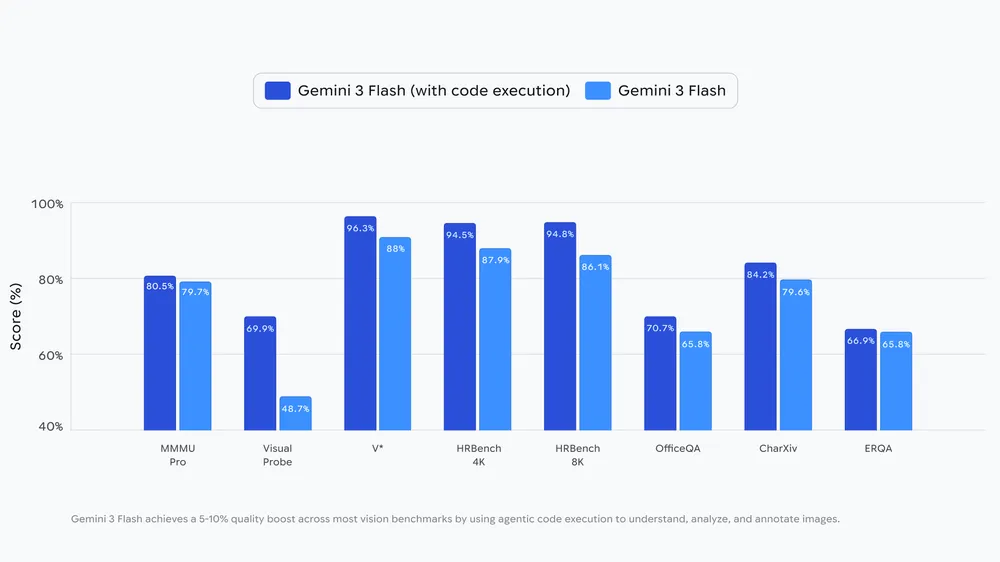
La idea, sin embargo, no es totalmente nueva: OpenAI ya introdujo capacidades similares con el modelo o3.
Un ejemplo práctico: revisión de planos
Como caso de uso, Google menciona PlanCheckSolver.com, una plataforma que revisa planos de construcción para comprobar cumplimiento normativo. El startup asegura haber mejorado su precisión en torno a un 5% dejando que Gemini 3 Flash inspeccione planos de alta resolución de forma iterativa: el modelo recorta zonas concretas (como bordes de tejados o secciones del edificio) y las analiza por separado.
En anotación de imágenes, el modelo también puede dibujar cajas delimitadoras (bounding boxes) y etiquetas. Google muestra como ejemplo el conteo de dedos: marca cada dedo con una caja y un número para evitar errores de conteo.
Para matemática visual, el modelo podría parsear tablas y ejecutar cálculos en un entorno Python en lugar de alucinar, y luego devolver el resultado como gráfico.
Aún requiere indicaciones explícitas
Google admite que estas funciones todavía no se activan siempre de forma automática. Aunque el zoom sobre detalles pequeños ya puede ocurrir de manera implícita, otras funciones —como rotar imágenes o matemática visual— suelen necesitar instrucciones explícitas en el prompt. La empresa dice que planea resolver estas limitaciones en futuras actualizaciones.
Por ahora, Agentic Vision está disponible solo para el modelo Flash. Google planea extenderlo a otros tamaños de modelo y añadir más herramientas, como búsqueda web y búsqueda inversa de imágenes.
Agentic Vision está disponible a través de la Gemini API en Google AI Studio y Vertex AI. En la app de Gemini, el despliegue ya ha comenzado: los usuarios pueden seleccionar “Thinking” en el menú de modelos. También hay una app de demostración y documentación para desarrolladores.

 ES
ES  EN
EN