

Traditional AI models process images in a single pass. If they miss a detail, they can only guess. Google DeepMind aims to change this with Agentic Vision. The model can iteratively zoom, crop, and manipulate images by generating and executing Python code.
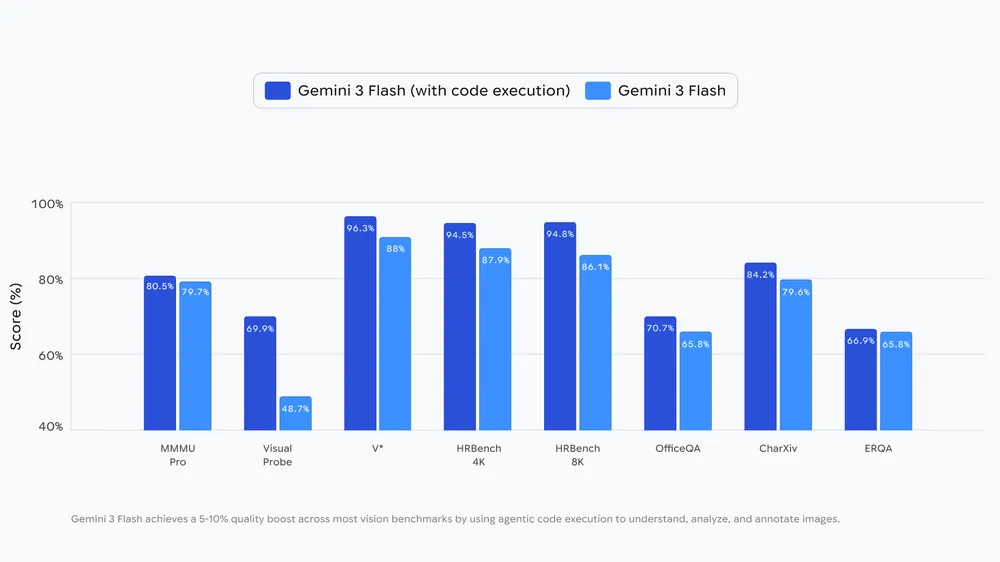
The system operates through a so-called Think–Act–Observe loop. First, the model analyzes the request and the image and formulates a plan. It then generates and runs Python code — for example, to crop, rotate, or annotate images. The output is added to the context window, allowing the model to inspect the new data before producing a response. Google reports that code execution improves performance by 5–10% across multiple vision benchmarks.
This idea is not entirely new: OpenAI previously introduced similar capabilities with its o3 model.
Construction blueprint startup reports improvements
As a real-world example, Google cites PlanCheckSolver.com, a platform that checks architectural blueprints for regulatory compliance. The startup reports a 5% accuracy improvement by allowing Gemini 3 Flash to iteratively inspect high-resolution plans. The model crops areas such as roof edges or building sections and analyzes them individually.
For image annotation, the model can also draw bounding boxes and labels directly onto images. Google demonstrates this with a finger-counting example: the model marks each finger with a box and number to prevent counting errors.
For visual mathematics, the model can parse tables and perform calculations inside a Python environment rather than hallucinating. The result can be output as a chart.
Many functions still require explicit instructions
Google acknowledges that these capabilities do not yet operate fully automatically. While the model can implicitly zoom in on small details, other functions — such as rotating images or performing visual math — still require explicit prompt instructions. The company plans to eliminate these limitations in future updates.
Additionally, Agentic Vision is currently available only for the Flash model. Expansion to other model sizes is planned, along with additional tools such as web search and reverse image search.
Agentic Vision is available via the Gemini API in Google AI Studio and Vertex AI. Rollout in the Gemini app has begun — users can enable it by selecting “Thinking” in the model dropdown. A demo app and developer documentation are also available.
Conclusion:
Agentic Vision represents a major step toward more autonomous and precise visual reasoning in AI systems, enabling models to actively explore images instead of relying on a single static pass.

 ES
ES  EN
EN