

Mientras que los humanos perciben de forma natural el mundo en tres dimensiones y comprenden cómo los objetos se mueven a través del espacio y el tiempo, esta capacidad ha sido hasta ahora un importante cuello de botella computacional para los sistemas de IA, según Google DeepMind.
El nuevo modelo, D4RT (Dynamic 4D Reconstruction and Tracking), pretende resolver este problema mediante una arquitectura innovadora que combina la estimación de profundidad, la correspondencia espacio-temporal y los parámetros de la cámara en un único sistema unificado.
Dos pasos en lugar de múltiples modelos
Los enfoques tradicionales de la reconstrucción 4D suelen basarse en varios modelos especializados que se encargan de tareas separadas como la estimación de profundidad, la segmentación del movimiento y la estimación de la pose de la cámara. Estos sistemas fragmentados requieren complejos procesos de optimización para garantizar la coherencia geométrica.
D4RT adopta un enfoque diferente basado en el Scene Representation Transformer. Un potente codificador procesa toda la secuencia de vídeo de una sola vez, comprimiéndola en una representación global de la escena. A continuación, un decodificador ligero consulta esta representación únicamente para los puntos específicos que se necesitan.
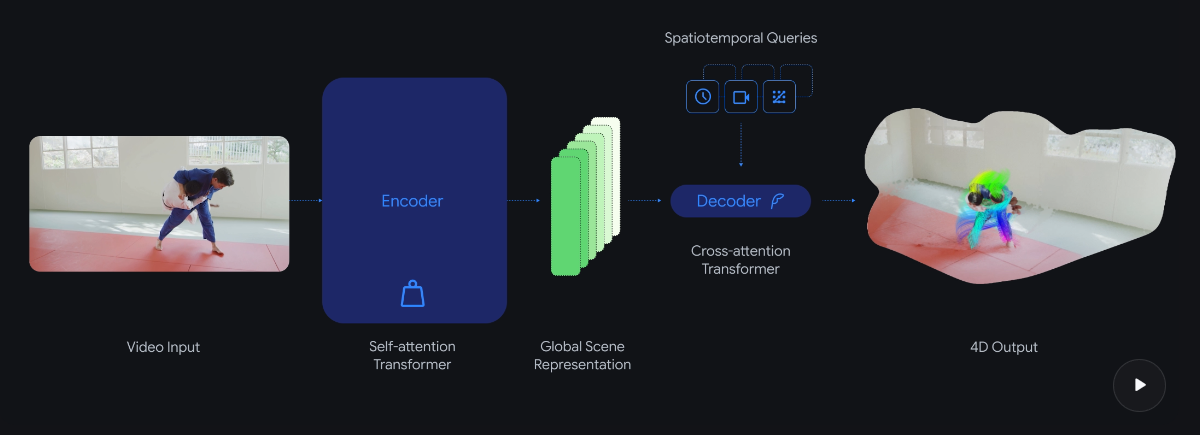
La idea central es responder a una pregunta clave: ¿dónde se encuentra un píxel determinado del vídeo en el espacio 3D en cualquier momento, desde un punto de vista de cámara elegido? Dado que cada consulta se procesa de forma independiente, puede paralelizarse de manera eficiente en el hardware moderno de IA.
A diferencia de los modelos competidores que requieren decodificadores separados para distintas tareas, D4RT utiliza un único decodificador para el seguimiento de puntos, las nubes de puntos, los mapas de profundidad y los parámetros de la cámara. El modelo incluso puede predecir la posición de objetos que no son visibles en otros fotogramas del vídeo. Funciona tanto en entornos estáticos como en escenas dinámicas con objetos en movimiento.
Entre 18 y 300 veces más rápido que los métodos existentes
Según los investigadores, las mejoras en eficiencia son sustanciales. D4RT opera entre 18 y 300 veces más rápido que los métodos comparables. Un vídeo de un minuto puede procesarse en aproximadamente cinco segundos en un solo chip TPU, mientras que los métodos anteriores podían tardar hasta diez minutos.
En los benchmarks compartidos por Google DeepMind, D4RT supera a las técnicas existentes en estimación de profundidad, reconstrucción de nubes de puntos, estimación de la pose de la cámara y seguimiento de puntos 3D. En la estimación de la pose de la cámara, alcanza más de 200 fotogramas por segundo, nueve veces más rápido que VGGT y cien veces más rápido que MegaSaM, además de ofrecer una mayor precisión.
La robótica y la realidad aumentada como primeras aplicaciones
A corto plazo, Google DeepMind considera que esta tecnología podría proporcionar a los robots una mejor percepción espacial y permitir que las aplicaciones de realidad aumentada integren objetos virtuales de forma más realista en entornos del mundo real. La eficiencia del modelo también acerca la posibilidad de su implementación directamente en los dispositivos.
A largo plazo, los investigadores ven este enfoque como un paso hacia modelos del mundo más avanzados, que consideran un hito crítico en el camino hacia la inteligencia artificial general (AGI). En estos modelos, los agentes de IA aprenderían de la experiencia, en lugar de limitarse a reproducir el conocimiento adquirido durante el entrenamiento.

 ES
ES  EN
EN