

While humans naturally perceive the world in three dimensions and understand how objects move through space and time, this ability has so far been a major computational bottleneck for AI systems, according to Google DeepMind.
The new model, D4RT (Dynamic 4D Reconstruction and Tracking), aims to solve this problem using a novel architecture that combines depth estimation, spatiotemporal correspondence, and camera parameters into a single unified system.
Two steps instead of many models
Traditional approaches to 4D reconstruction often rely on multiple specialized models handling separate tasks such as depth estimation, motion segmentation, and camera pose estimation. These fragmented systems require complex optimization steps to ensure geometric consistency.
D4RT takes a different approach based on the Scene Representation Transformer. A powerful encoder processes the entire video sequence at once, compressing it into a global scene representation. A lightweight decoder then queries this representation only for the specific points needed.
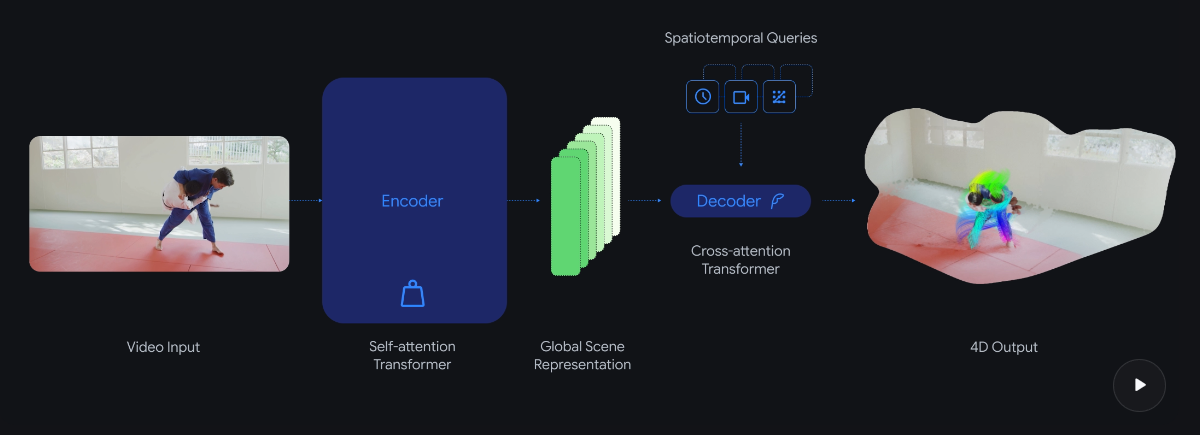
The core idea is to answer a key question: where is a given pixel from the video located in 3D space at any moment, from a chosen camera viewpoint? Since each query is processed independently, it can be efficiently parallelized on modern AI hardware.
Unlike competing models that require separate decoders for different tasks, D4RT uses a single decoder for point tracking, point clouds, depth maps, and camera parameters. The model can even predict the positions of objects that are not visible in other video frames. It works for both static environments and dynamic scenes with moving objects.
18 to 300 times faster than existing methods
According to the researchers, the efficiency gains are substantial. D4RT operates 18 to 300 times faster than comparable methods. A one-minute video can be processed in about five seconds on a single TPU chip, whereas previous methods could take up to ten minutes.
In benchmarks shared by Google DeepMind, D4RT outperforms existing techniques in depth estimation, point cloud reconstruction, camera pose estimation, and 3D point tracking. For camera pose estimation, it reaches over 200 frames per second, nine times faster than VGGT and one hundred times faster than MegaSaM, while also delivering higher accuracy.
Robotics and augmented reality as first applications
In the short term, Google DeepMind believes the technology could give robots better spatial awareness and enable augmented reality applications to place virtual objects more realistically into real-world environments. The model’s efficiency also brings on-device deployment within reach.
In the long term, the researchers see this approach as a step toward more advanced world models, which they consider a critical milestone on the path to artificial general intelligence (AGI). In such models, AI agents would learn from experience, rather than simply reproducing knowledge learned during training.
Conclusion
D4RT represents a major step forward in how AI systems understand and reconstruct the dynamic world. Its speed and accuracy could unlock new possibilities in robotics, augmented reality, and real-time perception. In the long term, this approach may become a foundation for building more capable and adaptive AI systems.

 ES
ES  EN
EN