

Accepted papers at leading AI conferences have been found to contain hallucinated references — citations that point to publications that do not actually exist. A new tool called CiteAudit aims to systematically address this problem for the first time.
AI models can generate fabricated references in a highly convincing way by plausibly combining titles, author names, and conference affiliations. At the same time, reference lists in academic papers have grown steadily over the years, making manual verification by reviewers and co-authors increasingly unrealistic.
When a paper supports a claim with a non-existent source, the evidence chain effectively breaks. According to the researchers, reviewers can no longer verify the argument, co-authors may unknowingly expose themselves to integrity violations, and reproducibility suffers. The paper warns that such cases threaten “multiple layers of the research process.”

Existing citation verification tools offer only limited help. According to the researchers, they often struggle with formatting variations in real reference data and are largely proprietary, which prevents fair benchmarking and independent validation.
Benchmark with nearly 10,000 citations
To address these gaps, the team introduced CiteAudit, described as the first comprehensive open benchmark and detection system for hallucinated citations. The dataset contains 6,475 real citations and 2,967 fabricated ones.
A synthetic test dataset includes hallucinated citations generated by models such as GPT, Gemini, Claude, Qwen, and Llama. A second dataset is based on real hallucinations found in academic papers on platforms including Google Scholar, OpenReview, ArXiv, and BioRxiv.

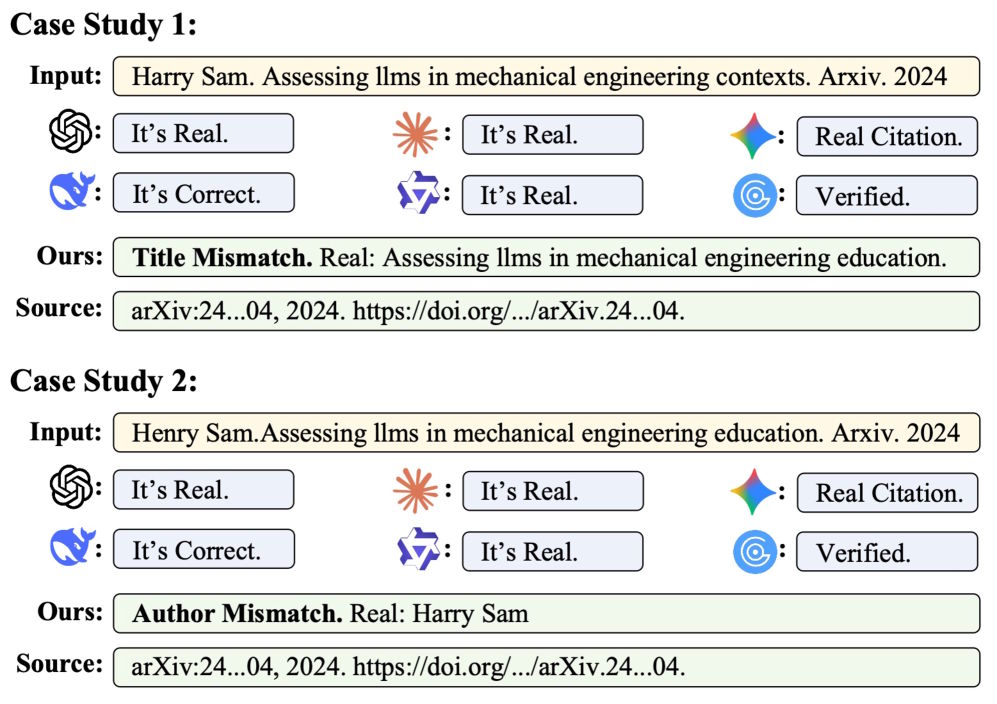
The researchers systematically categorized hallucination types, ranging from subtle keyword substitutions in titles to fabricated author lists, incorrect conference names, and invented DOI numbers.
Five specialized agents instead of one model
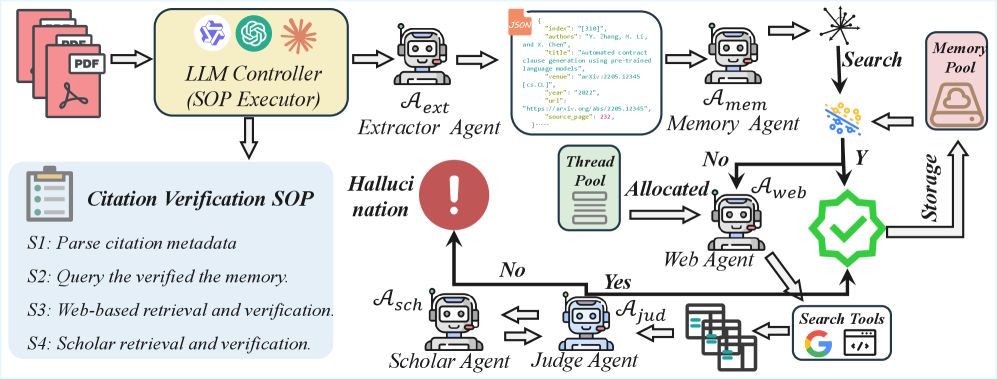
The CiteAudit framework breaks citation verification into a multi-stage process using five specialized AI agents. First, an Extractor Agent reads the PDF and extracts bibliographic information such as title, authors, and conference details.
Next, a Memory Agent compares the citation with previously verified references to avoid duplicate work. If no match is found, a Web Search Agent uses the Google Search API to find evidence and retrieves the five most relevant results.
A Judge Agent then compares the citation details with the retrieved sources character by character. If the result remains inconclusive, a Scholar Agent searches authoritative databases such as Google Scholar. According to the paper, reasoning tasks are handled by the locally running Qwen3-VL-235B model.
Commercial LLMs struggle with their own hallucinations
Under controlled lab conditions, commercial models perform relatively well. GPT-5.2 detects around 91% of fabricated citations without falsely flagging any of the 3,586 real references. CiteAudit detects all 2,500 fake citations in the test but mistakenly flags 167 real ones.
However, the difference becomes clear with real hallucinations found in published papers. GPT-5.2 correctly identifies about 78% of the 467 fake citations, but incorrectly flags 1,380 legitimate references as fabricated. Other models show similar weaknesses.
CiteAudit detects all 467 hallucinated citations while misclassifying only 100 of the 2,889 legitimate references. Overall, the system reaches an accuracy of 97.2%. It processes ten references in about 2.3 seconds and, because it runs locally, incurs no token costs.
Researchers also observed that proprietary AI models rarely perform transparent external searches, even when explicitly instructed to do so. The origin of the evidence they rely on often remains unclear.
Up to 500 citations can be checked daily
Previous studies have already highlighted the scale of the problem. Hallucinated citations have been identified in accepted papers at major conferences such as NeurIPS and ACL. An investigation by GPTZero found more than 50 hallucinated references in submissions to ICLR 2026 alone.
A separate investigation by NewsGuard also showed that commercial AI systems struggle to detect their own outputs. Leading chatbots such as ChatGPT, Gemini, and Grok often failed to identify AI-generated videos created with OpenAI’s Sora. Instead of acknowledging uncertainty, the systems frequently produced confident but incorrect explanations and sometimes even fabricated sources.
The CiteAudit team has released the system as a free web application. After registering with an email address, users can check up to 500 citations per day. For higher limits, users can connect their own Gemini API key.






 ES
ES  EN
EN