

Meta FAIR and researchers from New York University have conducted a systematic study on how multimodal AI models can be trained from scratch. Their findings challenge several widely held assumptions in the field.
Large language models have defined the era of foundation models. However, in their paper “Beyond Language Modeling,” the researchers argue that text is ultimately a lossy compression of reality. Referencing Plato’s allegory of the cave, they suggest that language models have learned to describe the shadows on the wall without ever seeing the objects that cast them. In addition, high-quality text data is finite and may eventually become exhausted.

To address this limitation, the team trained a single model entirely from scratch. It combines standard next-token prediction for language with a diffusion method called Flow Matching for visual data. Training data included text, raw video, image-text pairs, and action-conditioned videos. A key methodological choice was to avoid building on an existing language model, preventing previously learned knowledge from biasing the results.
One visual encoder is enough for both understanding and generation
Previous approaches such as Janus or BAGEL use separate visual encoders for image understanding and image generation. According to the study, this separation may not be necessary.
A Representation Autoencoder (RAE) based on the SigLIP 2 image model outperformed traditional VAE encoders in both image generation and visual understanding, while maintaining language performance at the level of a pure text model.
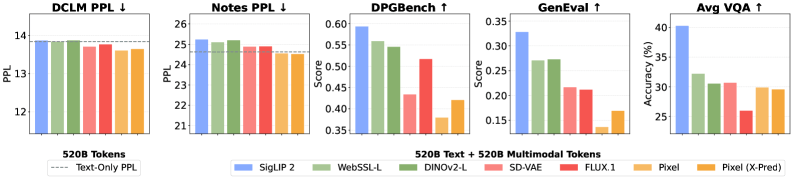
Instead of two separate processing paths, a single encoder can handle both tasks, simplifying the architecture significantly.
Another common assumption is that vision and language compete with each other inside a model. The study suggests otherwise. Training on raw video data without text annotations did not harm language performance. In fact, on a validation dataset, the model trained on text and video slightly outperformed the text-only baseline.
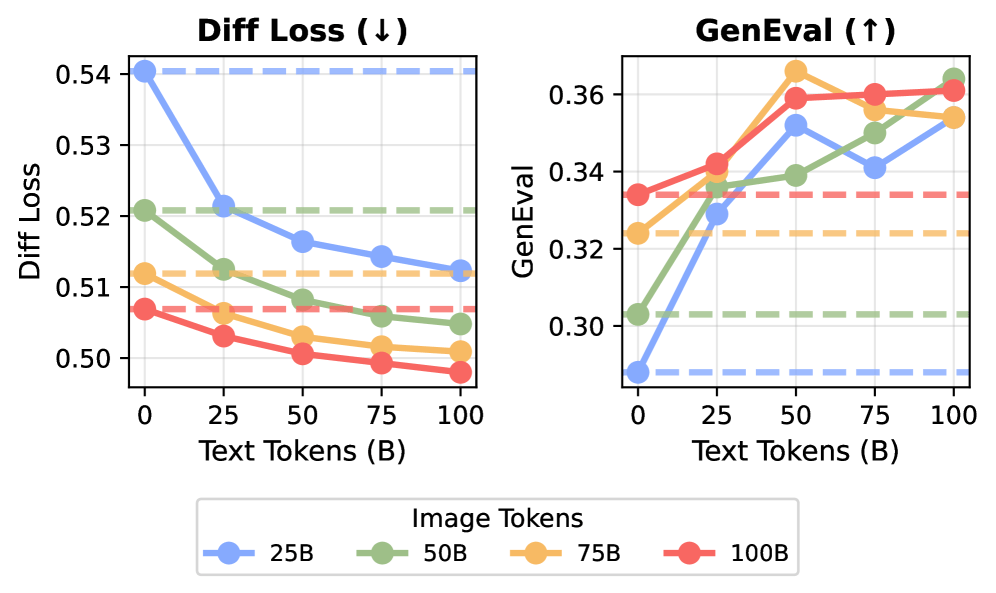
An interesting synergy effect also appeared. When 20 billion VQA tokens (visual question answering data) were combined with 80 billion tokens from video, image-text pairs (MetaCLIP), or text, the resulting model outperformed another model trained on 100 billion VQA tokens alone.
World modeling emerges naturally
The researchers also tested whether the model could predict future visual states. Given a current image and a navigation instruction, the model had to predict the next visual frame. Actions were encoded directly as text, meaning no architectural changes were required.
The results suggest that world-modeling abilities emerge primarily from general multimodal training, rather than from specific navigation datasets. With just one percent of task-specific data, the model achieved competitive performance.

The system could even respond to natural language commands such as “Get out of the shadow!” and generate appropriate image sequences, despite never having encountered such instructions during training.
Mixture-of-Experts learns specialization automatically
The study also explored Mixture-of-Experts (MoE) architectures. In this approach, each input token is routed only to a subset of specialized network modules rather than activating the entire model. This reduces computational cost while increasing total model capacity.
In a model with 13.5 billion parameters, of which only 1.5 billion are active per token, the MoE architecture outperformed both dense models and manually designed separation strategies.
Interestingly, the model developed specialization on its own. It assigned significantly more experts to language than to vision. Early layers were dominated by text specialists, while deeper layers increasingly contained visual and multimodal experts.
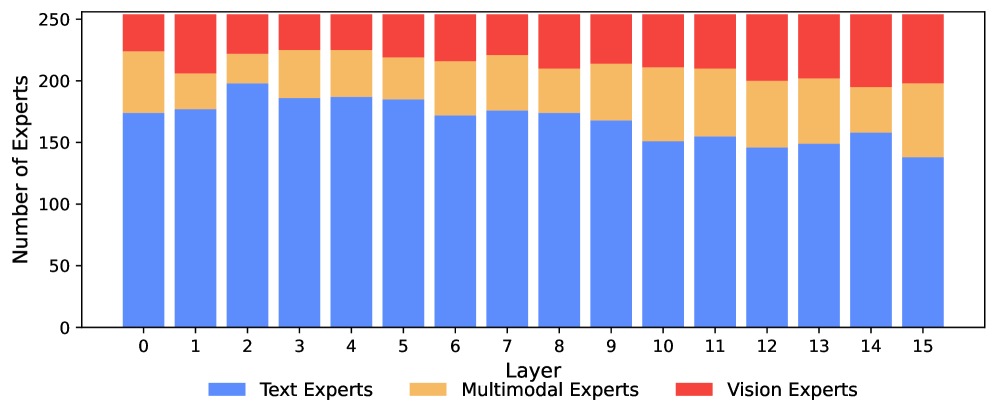
Another notable finding is that image understanding and image generation activated the same experts, with correlations of at least 0.90 across all layers. The researchers interpret this as evidence supporting Rich Sutton’s “Bitter Lesson” — that learning from large datasets often outperforms carefully engineered solutions.
Vision requires far more data than language
Training AI models always involves a trade-off between model size and the amount of training data. The well-known Chinchilla scaling laws suggest that for language models, both should grow at roughly the same rate.
However, when applying scaling laws to a combined vision-language model, the researchers discovered a major asymmetry. For language, the traditional balance still holds. For vision, the optimal strategy shifts heavily toward more data rather than a larger model.
As models scale up, the difference becomes dramatic. Starting from a base model with 1 billion parameters, the study estimates that the relative demand for vision data compared with language data increases 14-fold at 100 billion parameters and 51-fold at 1 trillion parameters.
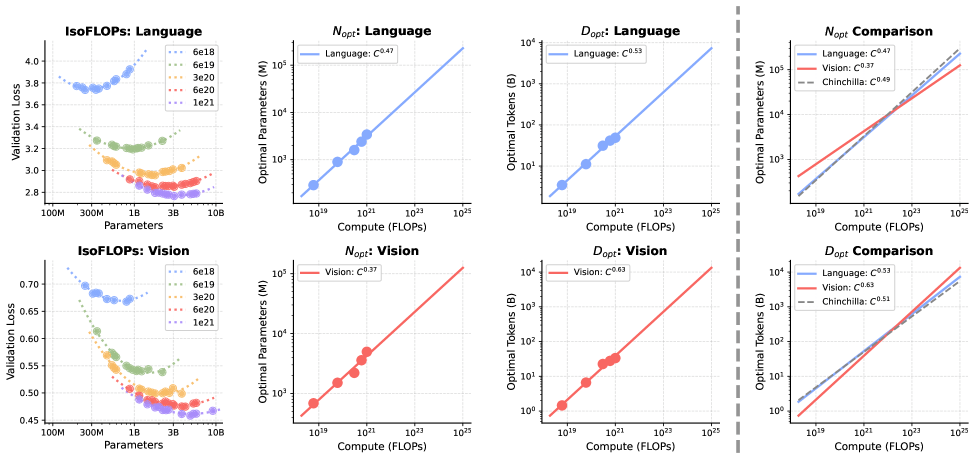
This imbalance is difficult to resolve in traditional dense models, where every parameter is active during each computation step.
However, the Mixture-of-Experts architecture helps mitigate the issue. Because only a fraction of experts are activated per token, the model can have a very large total parameter count without proportional increases in computational cost. This allows language to benefit from high parameter capacity while vision benefits from large datasets. According to the study, MoE reduces the scaling asymmetry between the two modalities by roughly half.
The researchers emphasize that their work focuses on pretraining only. Finetuning and reinforcement learning were not examined in detail. Nevertheless, the findings suggest that the boundary between multimodal models and world models may increasingly blur.
Massive volumes of unlabeled video data remain largely unused today. The study indicates that these datasets could be incorporated into AI training without harming language performance, potentially opening the door to more powerful multimodal systems in the future.






 ES
ES  EN
EN