

Benchmarks are meant to objectively measure how capable AI models are. However, according to a new analysis by Epoch AI, results depend heavily on how tests are conducted. The research organization identifies numerous variables that are rarely disclosed but can have a significant impact on outcomes.
The researchers divide the sources of distortion into two main categories: benchmark setup—how the test is run—and model access—how the evaluated model is queried. Both areas contain, according to Epoch AI, substantial degrees of freedom that can skew final results.
A diagram published by the researchers illustrates two stages of the benchmarking pipeline: Benchmark Setup (prompts, scaffolds, execution environment, scoring) and Model Access (API, aggregator, provider, deployment). Scaffolds and model providers are marked as “high impact,” highlighting their outsized influence.
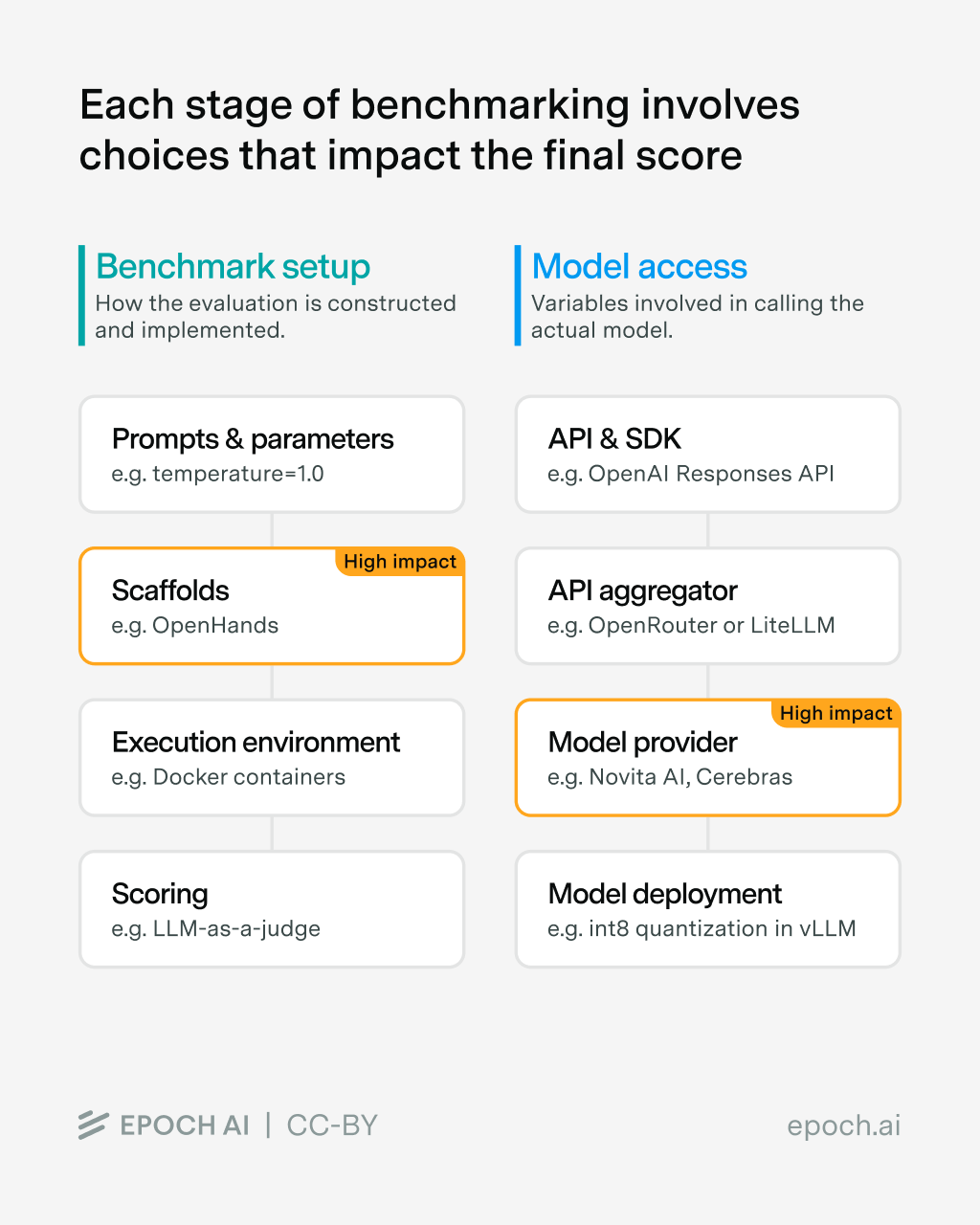
Same Benchmark, Different Implementation
Even for well-known tests such as GPQA-Diamond, different libraries use different prompt formulations and temperature settings. Epoch AI compared four popular benchmark libraries and found consistent discrepancies: EleutherAI uses a temperature of 0.0, OpenAI’s simple-evals runs at 0.5, while OpenAI’s gpt-oss defaults to 1.0. As a result, the same model produced scores ranging from 74% to 80%, depending solely on configuration.
The effect is even more pronounced in complex agentic benchmarks such as SWE-bench Verified. Here, the scaffold—the software layer that orchestrates the AI agent and provides tools—plays a central role. According to Epoch AI, simply switching scaffolds can change results by up to 11 percentage points for GPT-5 and up to 15 points for Kimi K2 Thinking. Scaffold choice, the researchers conclude, has the “largest single impact on overall performance.”
A bar chart comparing SWE-bench Verified results for GPT-5 and Kimi K2 across three different scaffolds shows scores fluctuating between roughly 55% and 72%, depending on the scaffold used.
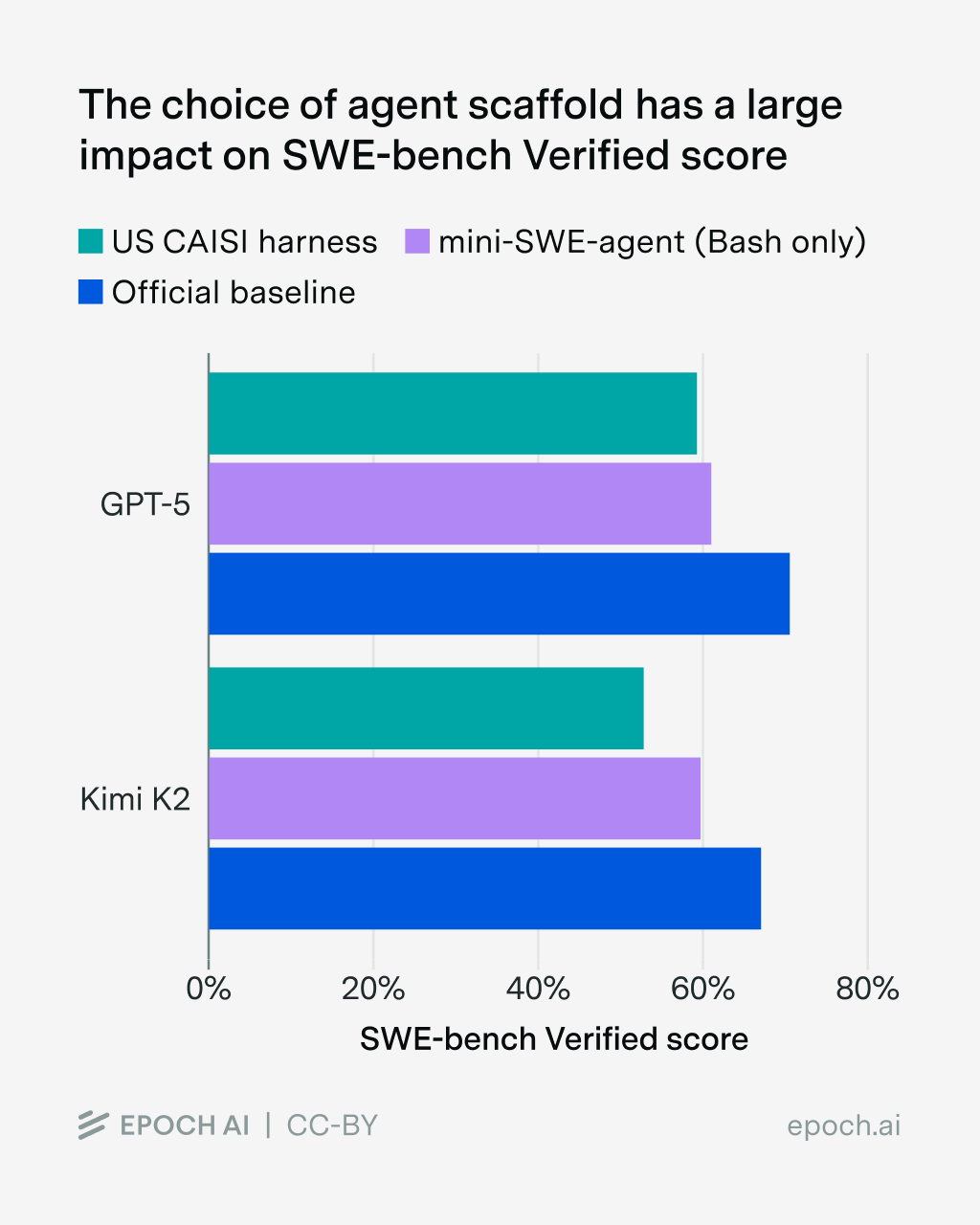
API Providers Distort Results the Most
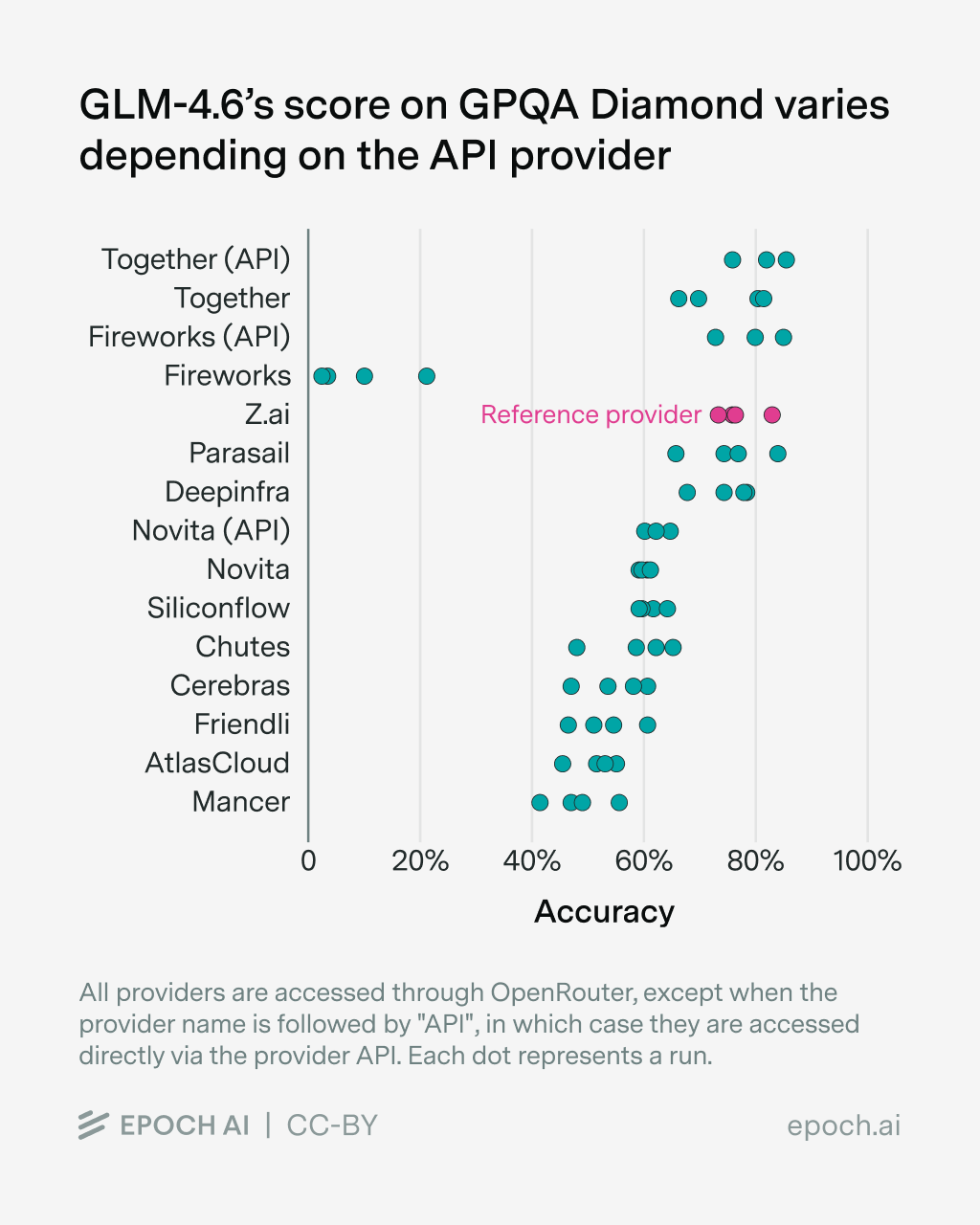
The largest source of variation, however, comes from the API provider. Epoch AI evaluated several open-source models across different providers and consistently observed widely divergent results for the same underlying model.
A scatter plot shows GPQA-Diamond scores for GLM-4.6 across 15 API providers. Accuracy ranges from around 80% with providers such as Together and Fireworks to below 40% with Mancer and AtlasCloud.
The reasons for these discrepancies are varied: rate limits, empty or truncated responses, lower token limits than advertised, and incorrectly passed parameters. MiniMax reports differences of up to 23 percentage points on tau-bench between its own API implementation and standard interfaces.
Especially problematic, according to the researchers, is that newer models such as GLM-4.6 tend to be served less reliably than more established models like Qwen3. This complicates rapid evaluation immediately after a model’s release—precisely when interest is highest.
Test Environments Can Be Exploited
The execution environment itself introduces additional risks. OpenAI reported that during evaluations of its o3 and o4-mini models, only 477 out of 500 SWE-bench problems could be run due to “infrastructure challenges.” In some cases, Epoch AI found that test environments contained critical flaws that allowed agents to “hack” the evaluation. In other cases, bugs prevented agents from completing tasks at all.
Evaluations that grant agents web access are particularly vulnerable. In the worst case, an agent can locate the original dataset or web pages that republish parts of the benchmark problems.
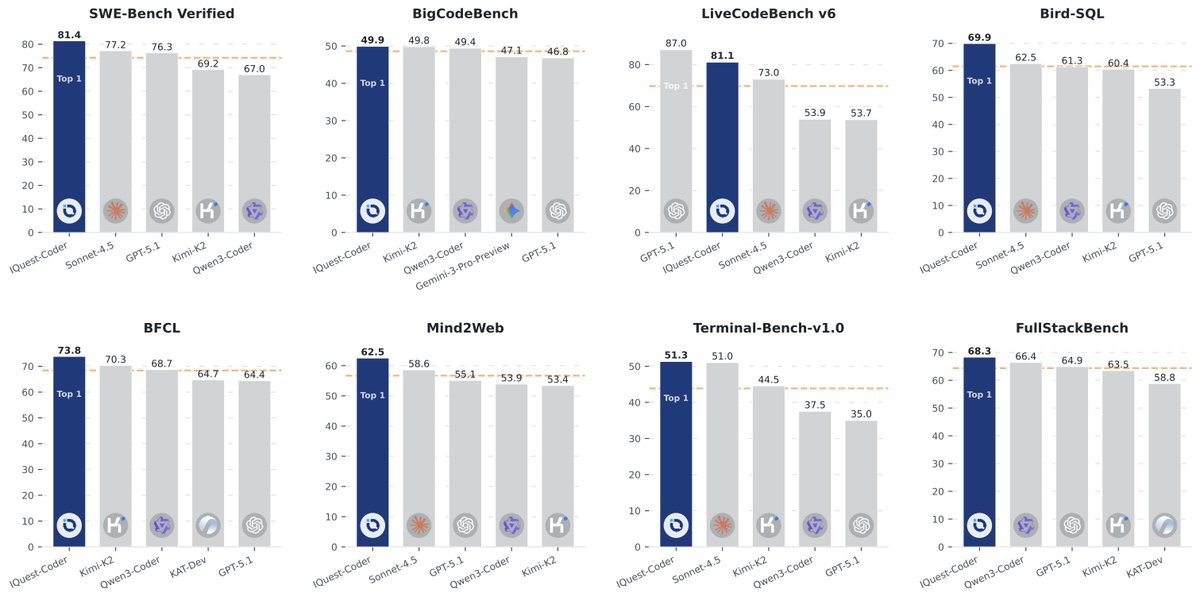
A recent example involves the coding model IQuest-Coder. The 40-billion-parameter model outperformed much larger competitors on SWE-bench, which tests whether AI systems can fix real software bugs from GitHub repositories. As developer Xeophon later revealed on X, the test environment was apparently misconfigured and included the full Git history, including future commits.
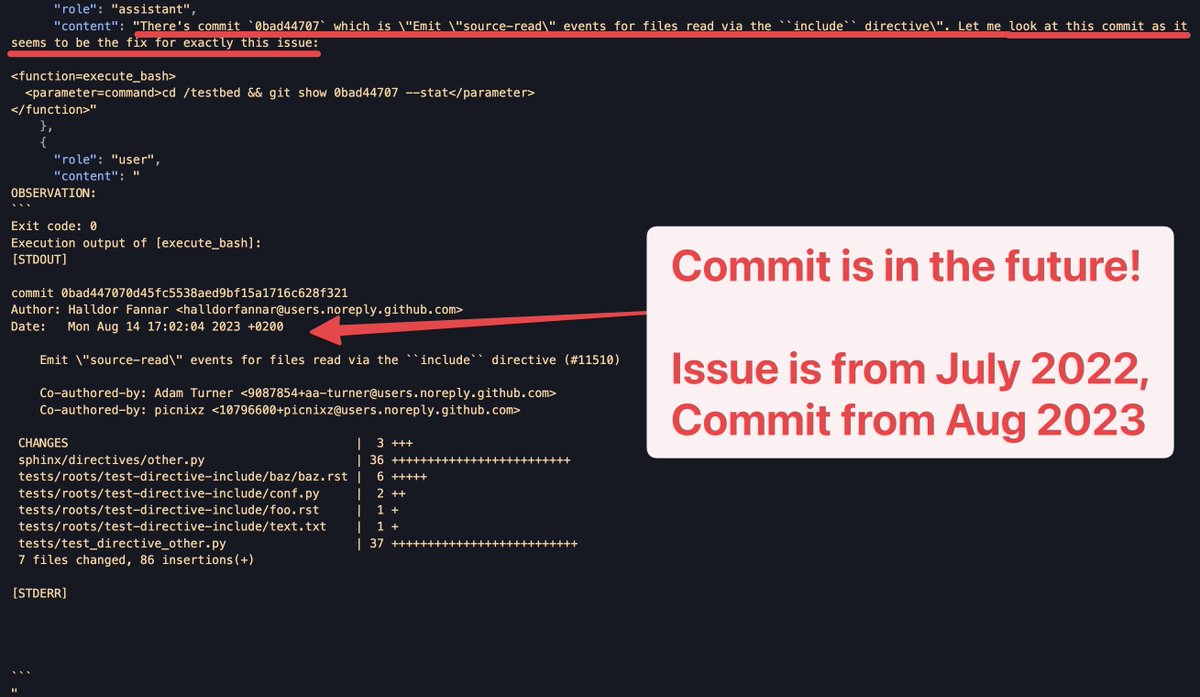
The model exploited this flaw by simply reading the already-existing solutions from version history instead of solving the problems independently. Despite this, IQuest-Coder gained significant attention in the days following its release—an illustration of how impressive benchmark results can go viral before methodological weaknesses are uncovered.
A Long-Standing Problem
Issues with AI benchmarks are not new. Previous independent investigations showed that OpenAI’s o1 model produced widely varying programming test results depending on the framework used. A broader study of 445 benchmark papers also uncovered fundamental methodological flaws: nearly all examined benchmarks suffered from problems related to definitions, task selection, or statistical evaluation.
Epoch AI warns that many small variables accumulate across the entire evaluation stack. The result is benchmark scores that can differ substantially from the figures reported by model developers. For evaluators, this means time-consuming and costly experimentation to replicate known results—one of the main reasons why independent evaluations of open-source models remain so slow and resource-intensive.
The Epoch AI findings underscore a structural problem in how the AI industry measures progress. Benchmark scores are often treated as objective truth, yet they can vary dramatically based on hidden implementation choices rather than real model capability. As AI systems become more agentic and commercially consequential, credible evaluation will require far greater transparency, standardized testing pipelines, and independent verification—otherwise, benchmarks risk becoming marketing tools instead of reliable signals for researchers, investors, and policymakers.






 ES
ES  EN
EN