
Reasoning models like DeepSeek-R1 don’t simply “think longer.” According to a new study, they internally simulate a kind of debate between different perspectives that question and correct one another.
Researchers from Google, the University of Chicago, and the Santa Fe Institute investigated why reasoning models such as DeepSeek-R1 and QwQ-32B perform significantly better on complex tasks than conventional language models. They found that these models generate a “society of thought” within their reasoning traces—multiple simulated voices with different personalities and areas of expertise that engage in discussion with one another.
Internal debates in reasoning models
An analysis of more than 8,000 reasoning problems revealed clear differences between reasoning models and standard instruction-tuned models. Compared with DeepSeek-V3, DeepSeek-R1 shows significantly more question-answer sequences and more frequent shifts in perspective. QwQ-32B also exhibits many more explicit conflicts between different viewpoints than the comparable Qwen-2.5-32B.
The researchers identified these patterns using an LLM-as-judge approach, in which Gemini 2.5 Pro classified the reasoning traces. Agreement with human evaluators was substantial.
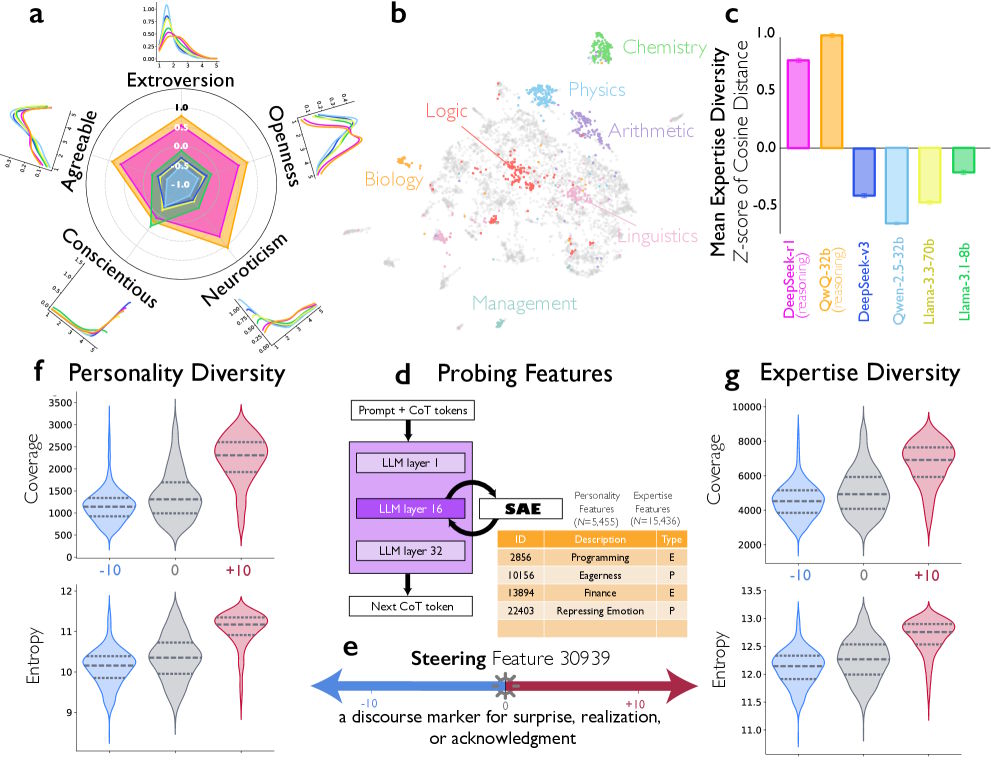
A fictional chat transcript illustrates the cognitive steps of an AI, complemented by network diagrams that depict different personality profiles of the simulated agents.
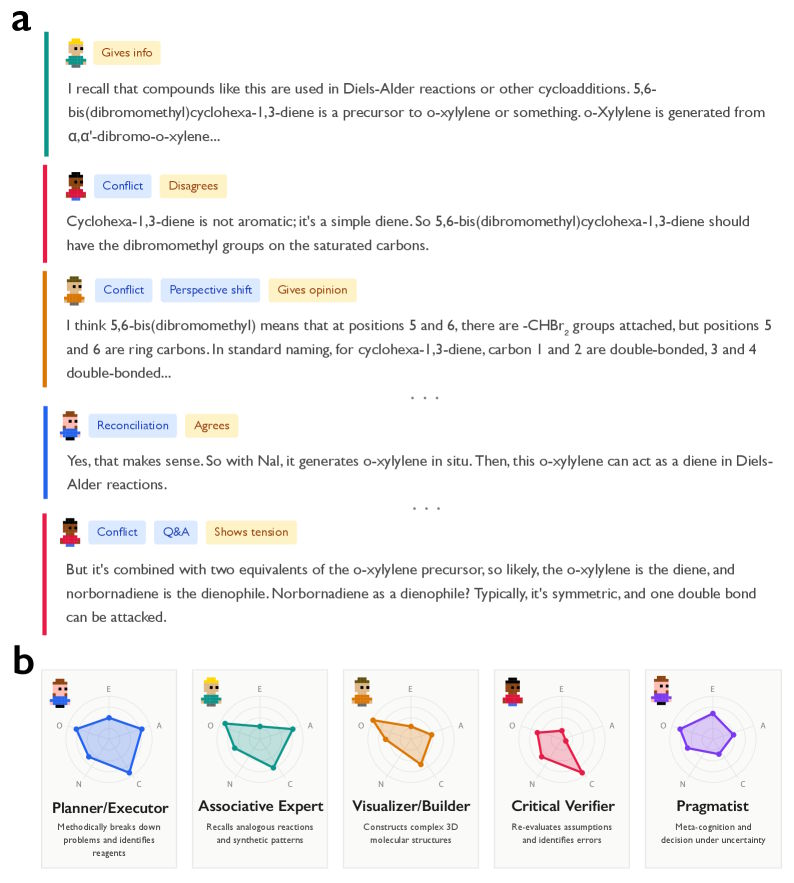
One example from the study highlights the difference: In a complex chemistry problem involving a multi-step Diels–Alder synthesis, DeepSeek-R1 showed perspective shifts and internal conflicts. The model wrote, for instance, “But here, it’s cyclohexa-1,3-diene, not benzene,” questioning its own assumptions. DeepSeek-V3, by contrast, produced a linear chain of opinions without self-correction and arrived at an incorrect result.
Different personalities in the reasoning process
The researchers went a step further and characterized the implicit perspectives within the reasoning traces. DeepSeek-R1 and QwQ-32B exhibited significantly greater personality diversity than instruction-tuned models, measured across all five Big Five dimensions: extraversion, agreeableness, conscientiousness, neuroticism, and openness.
Six diagrams analyzing AI reasoning show radar charts of roles and behavior as well as graphs of problem complexity.
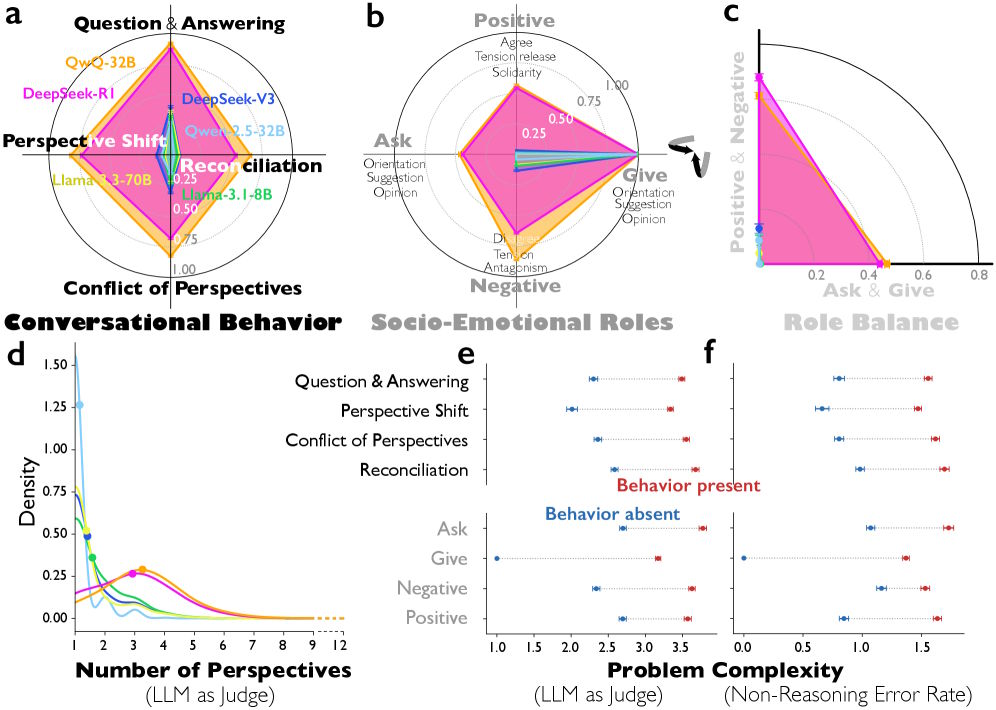
Interestingly, diversity in conscientiousness was lower: all simulated voices appeared disciplined and diligent. According to the authors, this aligns with findings from team research, which suggest that variability in socially oriented traits like extraversion and neuroticism improves team performance, whereas variability in task-oriented traits like conscientiousness can be detrimental.
In a creative writing task, the LLM-as-judge identified seven distinct perspectives in DeepSeek-R1’s reasoning trace, including a “creative idea generator” with high openness and a “semantic fidelity checker” with low agreeableness that raised objections such as: “But that adds ‘deep-seated,’ which wasn’t in the original.
Feature steering doubles accuracy
To test whether these conversational patterns actually cause better reasoning, the researchers used a technique from mechanistic interpretability that reveals which internal features a model activates.
They identified a feature in DeepSeek-R1-Llama-8B associated with typical conversational signals—such as surprise, realization, or confirmation—common during speaker changes.
Five diagrams show how activating human conversational features improves an AI’s logical reasoning.
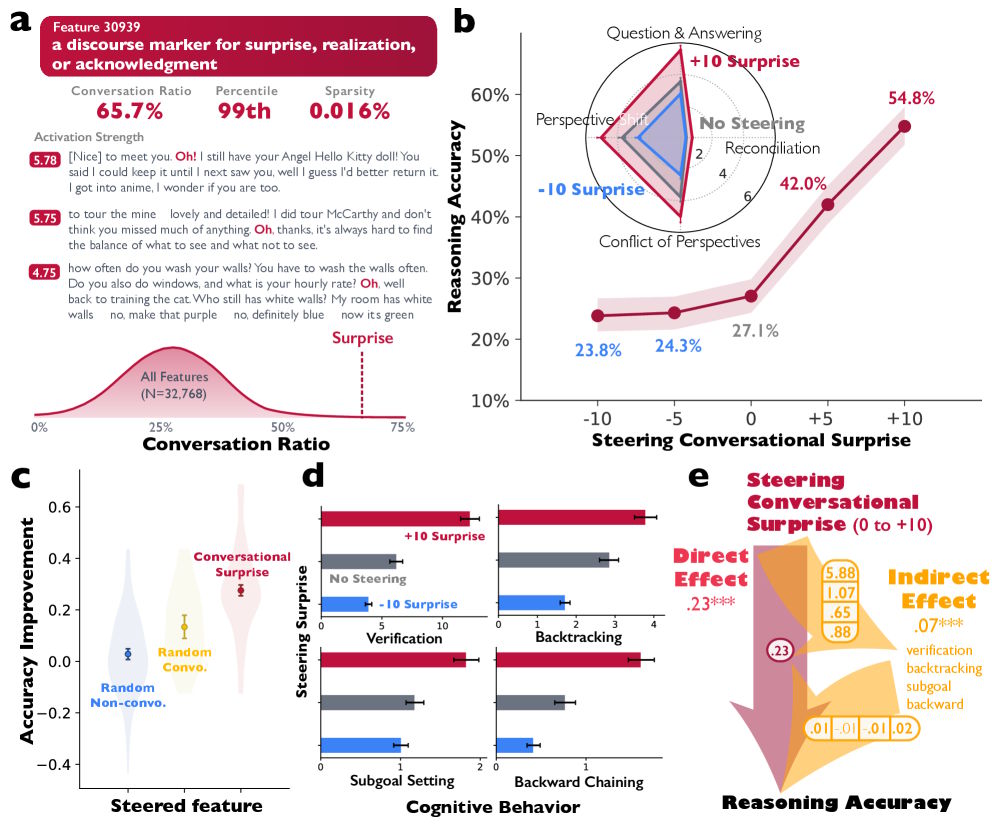
When the researchers artificially amplified this feature during text generation, accuracy on a math task doubled from 27.1% to 54.8%. At the same time, the models behaved more dialogically: they checked intermediate results more often and corrected errors on their own.
Social reasoning emerges spontaneously through reinforcement learning
The team also conducted controlled reinforcement-learning experiments. Base models spontaneously developed conversational behaviors when rewarded for accuracy—without any explicit training for dialog structures.
The effect was even stronger in models previously trained on dialog-like reasoning traces: they reached high accuracy faster than models trained on linear, monologic traces. For example, Qwen-2.5-3B models trained with dialog-style reasoning reached about 38% accuracy after 40 training steps, while monolog-trained models stagnated at 28%.
These dialog-like reasoning structures also transferred to other tasks. Models trained on simulated debates for math problems learned faster even when identifying political misinformation.
Parallels to collective intelligence
The authors draw parallels to research on collective intelligence in human groups. Mercier and Sperber’s “Enigma of Reason” theory argues that human reasoning evolved primarily as a social process. Bakhtin’s concept of the “dialogical self” similarly describes thinking as an internalized conversation among different perspectives.
The study suggests that reasoning models form a computational analogue of this collective intelligence: diversity improves problem-solving, provided it is systematically structured.
The researchers emphasize that they do not claim reasoning traces literally represent a discourse among simulated human groups or a mind simulating multi-agent interaction. However, the similarities to findings on effective human teams suggest that principles of successful group work may offer valuable guidance for developing reasoning in language models.
In summer 2025, Apple researchers raised fundamental doubts about the “thinking” capabilities of reasoning models. Their study showed that models like DeepSeek-R1 fail as problem complexity increases—and paradoxically think less. The Apple team interpreted this as a fundamental scaling limit.






 ES
ES  EN
EN