

“Gemma 4 are our most intelligent open models to date. They deliver an unprecedented level of intelligence per parameter,” the company said.

Since the launch of the first generation, developers have downloaded Gemma more than 400 million times, creating over 100,000 model variants within the Gemmaverse ecosystem. The latest version is built on the same research and technologies as the Gemini 3 chatbot.
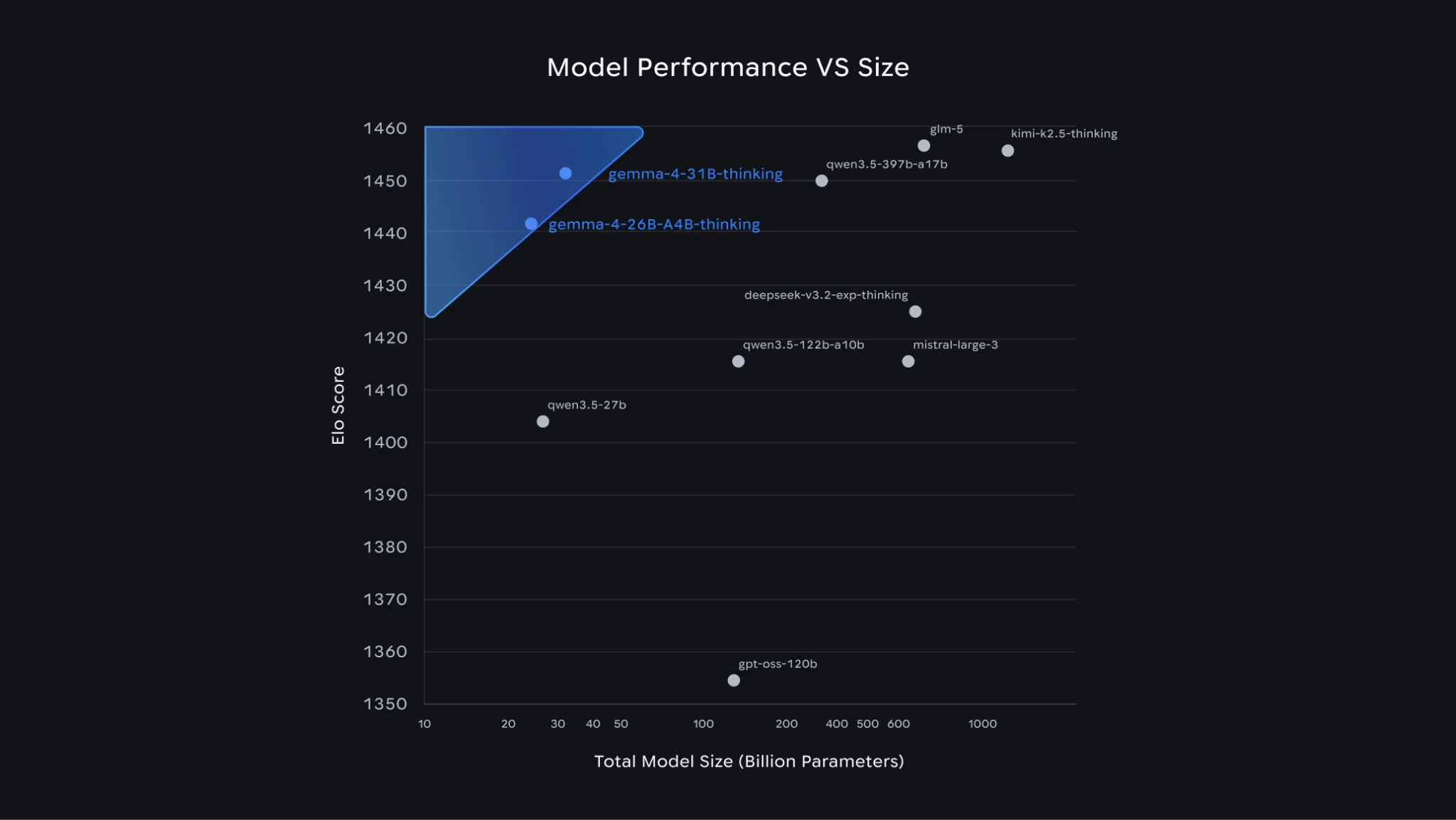
Different sizes
The Gemma 4 family includes four variants: Effective 2B (E2B), Effective 4B (E4B), 26B Mixture of Experts (MoE), and 31B Dense.
The compact E2B and E4B models, with 2.3 billion and 4.5 billion active parameters, focus on multimodality, low latency, and seamless integration. They can run on smartphones or standard laptops.
The larger 26B MoE and flagship 31B models (with 26 billion and 31 billion parameters) require high-end GPU accelerators such as the Nvidia H100 with 80 GB of memory. These versions are optimized for researchers and developers.
The larger models show strong benchmark performance. In the global ranking of open text models Arena AI, the flagship 31B ranks third, while the 26B model takes sixth place. According to Google, the new lineup outperforms competing models that are up to 20 times larger.
Key capabilities
One of the main advantages of Gemma 4 is its advanced reasoning ability. The models can build complex logic chains and plan multi-step tasks. They show significant progress in math benchmarks and follow instructions with high precision.
Other features include:
-
Agent workflows: built-in support for function calling, structured JSON outputs, and system instructions enables the creation of autonomous assistants that interact with tools and APIs;
-
Code generation: Gemma 4 supports high-quality code generation in offline mode, effectively turning a workstation into a local AI assistant;
-
Vision and audio: all models can process video and images at variable resolutions, recognize text, and analyze diagrams. E2B and E4B also support speech recognition and understanding;
-
Extended context window: compact models support up to 128,000 tokens, while larger versions handle up to 256,000 tokens, enabling full repository or large document processing in a single query;
-
Multilingual support: the model family supports more than 140 languages.
Gemma 4 is already available in Google AI Studio and the Google AI Edge Gallery. Integration is also supported by popular third-party tools and frameworks, including Hugging Face, vLLM, llama.cpp, MLX, Ollama, NVIDIA NIM, and LM Studio.
The models can be fine-tuned via Google Colab, Vertex AI, or local GPUs. For production use, deployment is available on Google Cloud, including Cloud Run, GKE, and Sovereign Cloud.

 ES
ES  EN
EN