

AI search engines face a fundamental technical challenge: before a language model can generate an answer, it must first narrow billions of web pages down to a small set of relevant documents.
This initial filtering step is handled by so-called embedding models. They convert queries and documents into numerical vectors, making semantic similarity mathematically comparable. Which documents are passed on to downstream ranking models and language models depends directly on the quality of these embeddings.
Perplexity has now released two proprietary embedding models: pplx-embed-v1 and pplx-embed-context-v1. The first is designed for classic dense text retrieval, while the second embeds text passages in the context of their surrounding documents, which helps resolve ambiguous passages. Both models are available in 0.6-billion and 4-billion-parameter variants.

According to Perplexity, their models achieve MTEB benchmark scores comparable to Alibaba’s Qwen3 and Google’s Gemini embeddings, while storing significantly more pages per gigabyte thanks to aggressive quantization.
Bidirectional text understanding instead of one-way processing
Most leading embedding models are based on large language models that process text only in one direction—from left to right. Each word can “see” only preceding words, not those that follow. While this is suitable for text generation, it limits text understanding, since the meaning of a sentence often depends on full context.
Perplexity takes a different approach. Its models are built on Alibaba’s pretrained Qwen3 language models, which originally process text left-to-right. The researchers modify these models to read text bidirectionally.
They then apply a masked-token training procedure similar to Google’s BERT: words are randomly hidden within passages, and the model must infer the missing tokens using context from both directions. The researchers refer to this as diffusion pretraining.
Training was performed on roughly 250 billion tokens across 30 languages. Half of the data comes from English educational websites in the FineWebEdu dataset, while the other half covers 29 additional languages from FineWeb2. Ablation studies show the approach improved retrieval performance by about one percentage point.
Another practical difference: according to Perplexity, the pplx-embed models do not require task-specific prefixes prepended to inputs—a common requirement in competing models. Such prefixes can degrade search quality if they differ between indexing and query time.
Memory requirements reduced by up to 32×
Storing embedding vectors for billions of web pages quickly becomes expensive. Standard practice uses 32-bit floating-point values (FP32). Perplexity instead trains its models from the outset to operate with 8-bit integers (INT8), reducing memory usage by a factor of four without sacrificing performance.
In an even more compact binary variant using just one bit per value, memory usage drops by up to 32×. For the 4B model, the quality loss remains below 1.6 percentage points, as its larger embedding size (2,560 dimensions) preserves more information than the smaller model’s 1,024 dimensions.
Public benchmarks show parity—or leadership
On the MTEB multilingual retrieval benchmark (v2), pplx-embed-v1-4B achieves an nDCG@10 of 69.66%, matching Alibaba’s Qwen3-Embedding-4B (69.60%) and outperforming Google’s gemini-embedding-001 (67.71%) with far lower memory requirements.
For contextual retrieval, pplx-embed-context-v1-4B sets a new high score on the ConTEB benchmark with 81.96%, compared with 79.45% for Voyage’s voyage-context-3 and 72.40% for Anthropic’s contextual model.
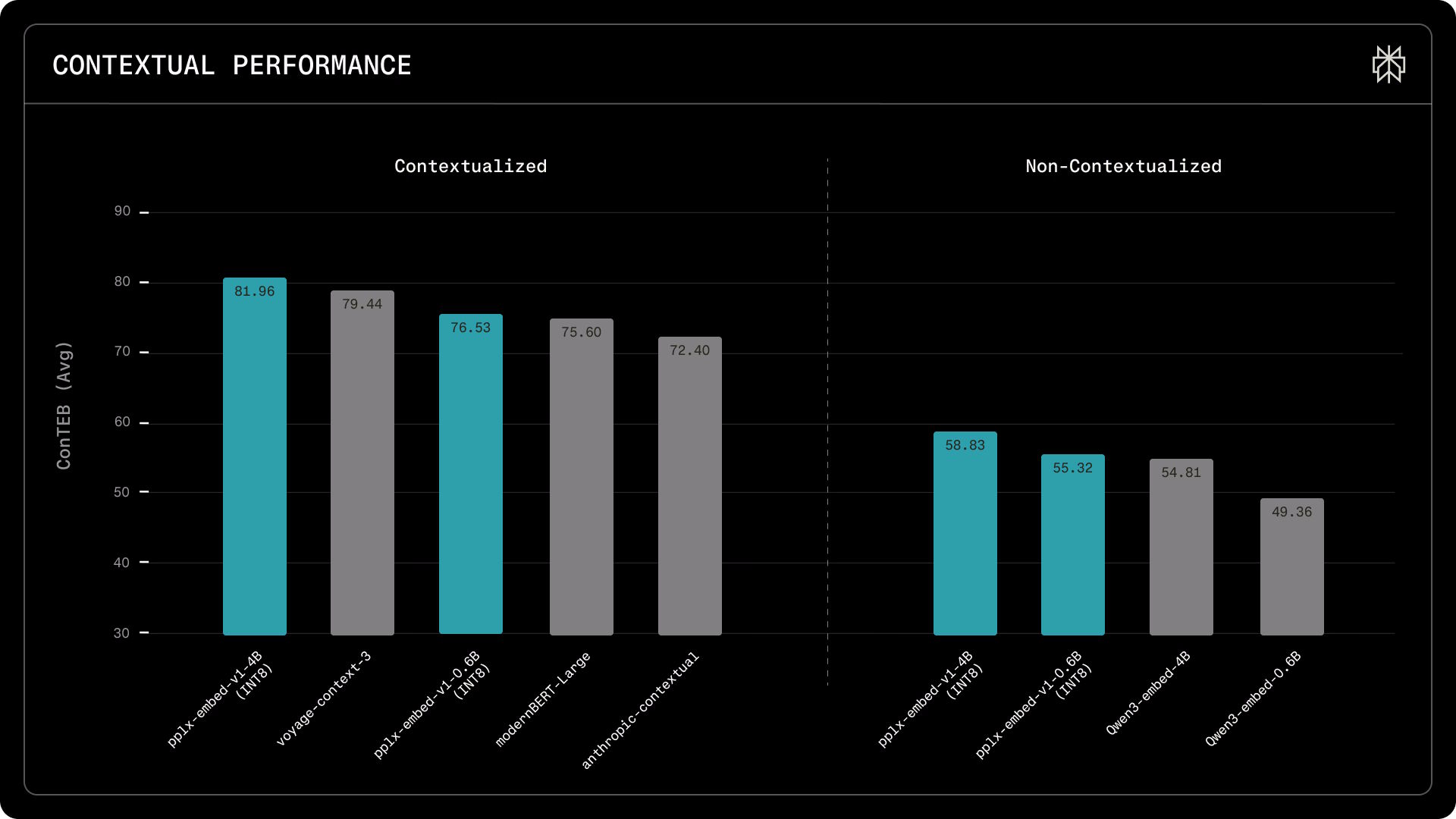
On the BERGEN benchmark, which evaluates end-to-end RAG performance from document retrieval to answer generation, the smaller pplx-embed-v1-0.6B outperforms the much larger Qwen3-Embedding-4B on three out of five tasks. This makes it a promising option for latency- and cost-sensitive applications.
Internal benchmarks show larger gaps
Perplexity argues that public benchmarks only partially reflect real-world web search, as they often lack noisy documents, unusual queries, and distribution shifts. To address this, the company developed two internal benchmarks using up to 115,000 real search queries against more than 30 million documents drawn from over one billion web pages.
On the PPLXQuery2Query benchmark, which measures whether models recognize semantically equivalent queries, pplx-embed-v1-4B achieves a Recall@10 of 73.5%, compared with 67.9% for Qwen3-Embedding-4B. The 0.6B model reaches 71.1%, significantly outperforming Qwen3-Embedding-0.6B (55.1%) and BGE-M3 (61.8%).
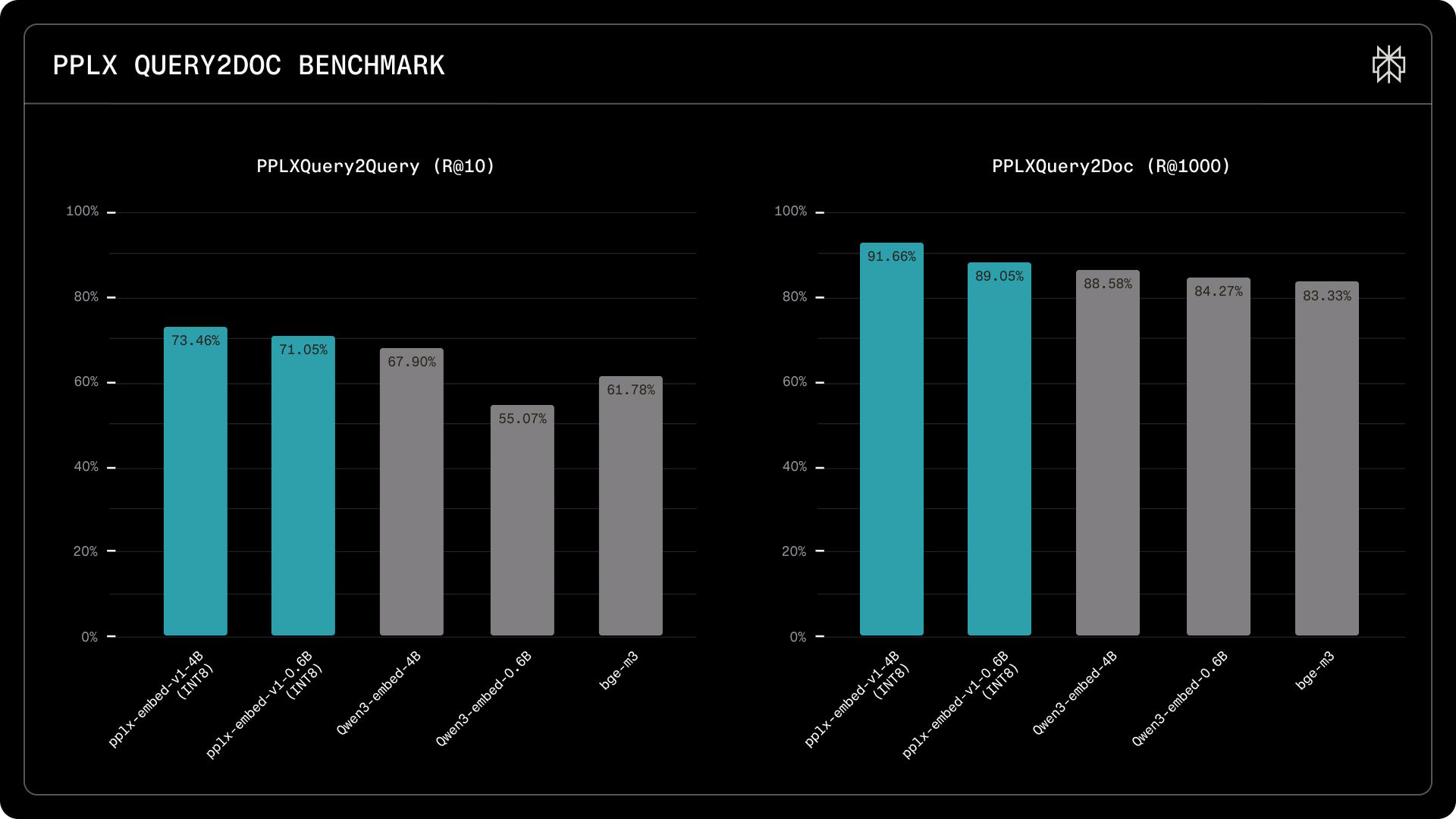
On the PPLXQuery2Doc benchmark, which evaluates document retrieval across a 30-million-page corpus, the 4B model retrieves 91.7% of relevant documents within the top 1,000 results, versus 88.6% for Qwen3.
According to Perplexity, the primary objective of embedding models as a first-stage filter is to surface as many relevant documents as possible—anything missed at this stage cannot be recovered by downstream ranking models.
All four models are available on Hugging Face under the MIT license and can be used via the Perplexity API as well as common inference frameworks such as Transformers, SentenceTransformers, and ONNX. The company has also released a technical report detailing its full evaluation results.

 ES
ES  EN
EN