

Like its predecessors Qwen3-Max and Qwen3.6-Plus, the new Max variant is available exclusively through Alibaba Cloud Model Studio's API. Alibaba had long pursued an open-source strategy with its Qwen models, but that approach has shifted — the last openly released flagship was Qwen3.5-397B-A17B in February 2026.
Qwen3.7-Max supports both OpenAI- and Anthropic-compatible interfaces and can be integrated directly into Claude Code, OpenClaw, or Qwen Code. According to the Qwen team, the model targets four use cases: coding agent work from frontend prototyping to complex multi-file software projects, automation of office tasks via external tools, sustained autonomous operation over extended periods, and consistent performance across different agent frameworks.
A 35-Hour Kernel Experiment
The team tasked Qwen3.7-Max with optimizing a low-level attention computation kernel for SGLang — an open-source inference framework — running on a cloud instance equipped with T-Head ZW-M890 accelerators, an AI chip platform from Alibaba's own semiconductor division. The model had never encountered this hardware architecture during training. It started with no performance data, no hardware documentation, and no example code — only the existing Triton-based reference implementation.
Over approximately 35 hours of continuous autonomous work, the model ran 432 kernel tests with a total of 1,158 tool calls. It iteratively compiled, measured, and revised the code, diagnosed compilation errors, and independently identified performance bottlenecks. The result, according to the Qwen researchers, was a tenfold average speedup over the reference implementation.
Competing models tested in the same setup achieved significantly lower results: GLM 5.1 reached a 7.3x speedup, Kimi K2.6 achieved 5x, DeepSeek V4 Pro reached 3.3x, and the predecessor Qwen3.6-Plus managed only 1.1x. Models that exited early did so voluntarily after five consecutive rounds with no tool calls. On the standardized KernelBench-L3 benchmark, Qwen3.7-Max produces accelerated kernels in 96% of cases — just behind Anthropic's Opus 4.6 at 98%.
Separating Task, Tool Environment, and Evaluator
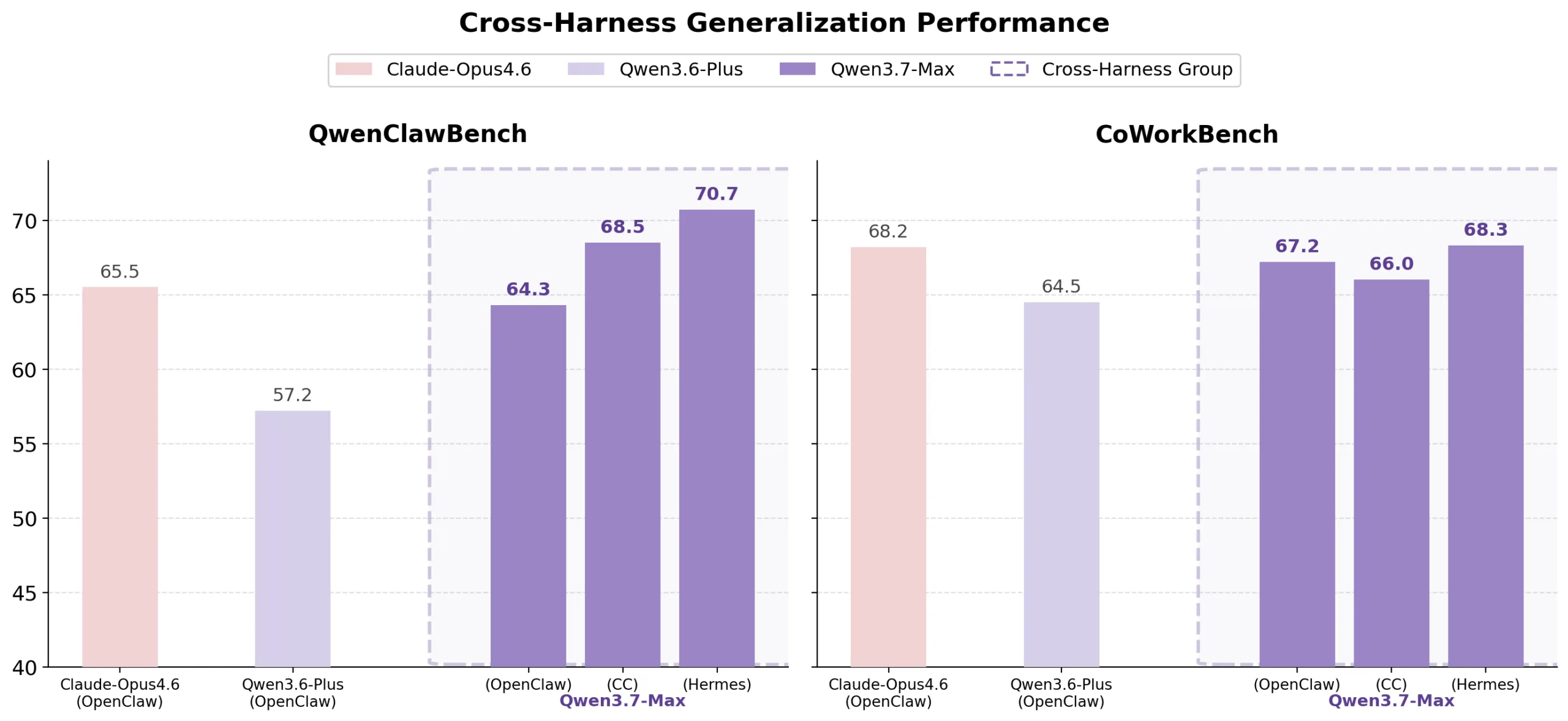
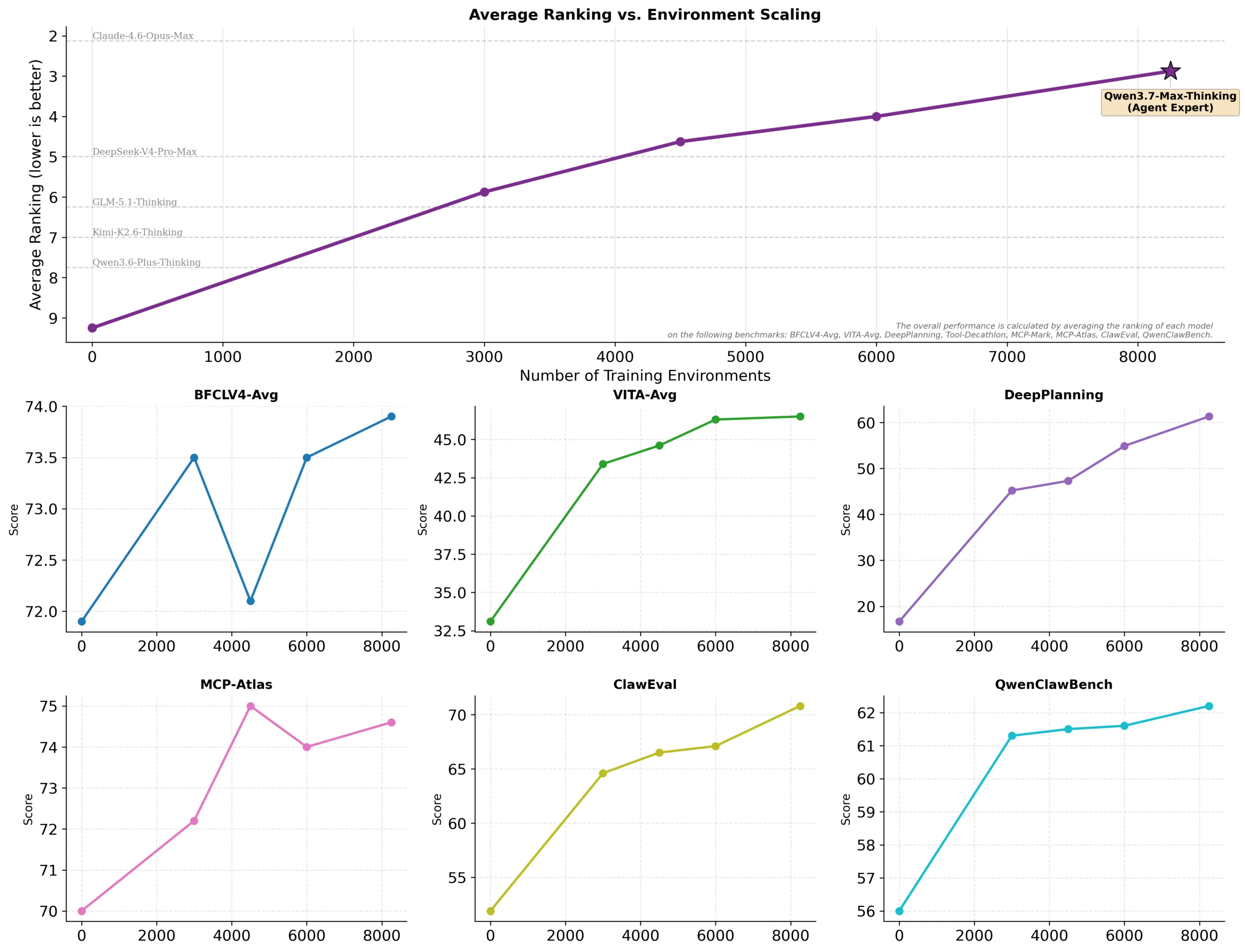
Methodologically, Qwen3.7-Max builds on a training approach introduced with Qwen3.5. Each training task is decomposed into three independent components: the task itself, the tool environment, and the result evaluator — which can be recombined freely. The same task is practiced across multiple tool environments and evaluated with different verification methods, forcing the model to develop broadly applicable solution strategies rather than shortcuts that only work in a specific setting. On QwenClawBench and CoWorkBench, Qwen3.7-Max's performance remains stable regardless of the test environment — and leads Claude Opus 4.6 on QwenClawBench across OpenClaw, Claude Code, and Hermes agent frameworks.
Self-Monitoring for Reward Hacking
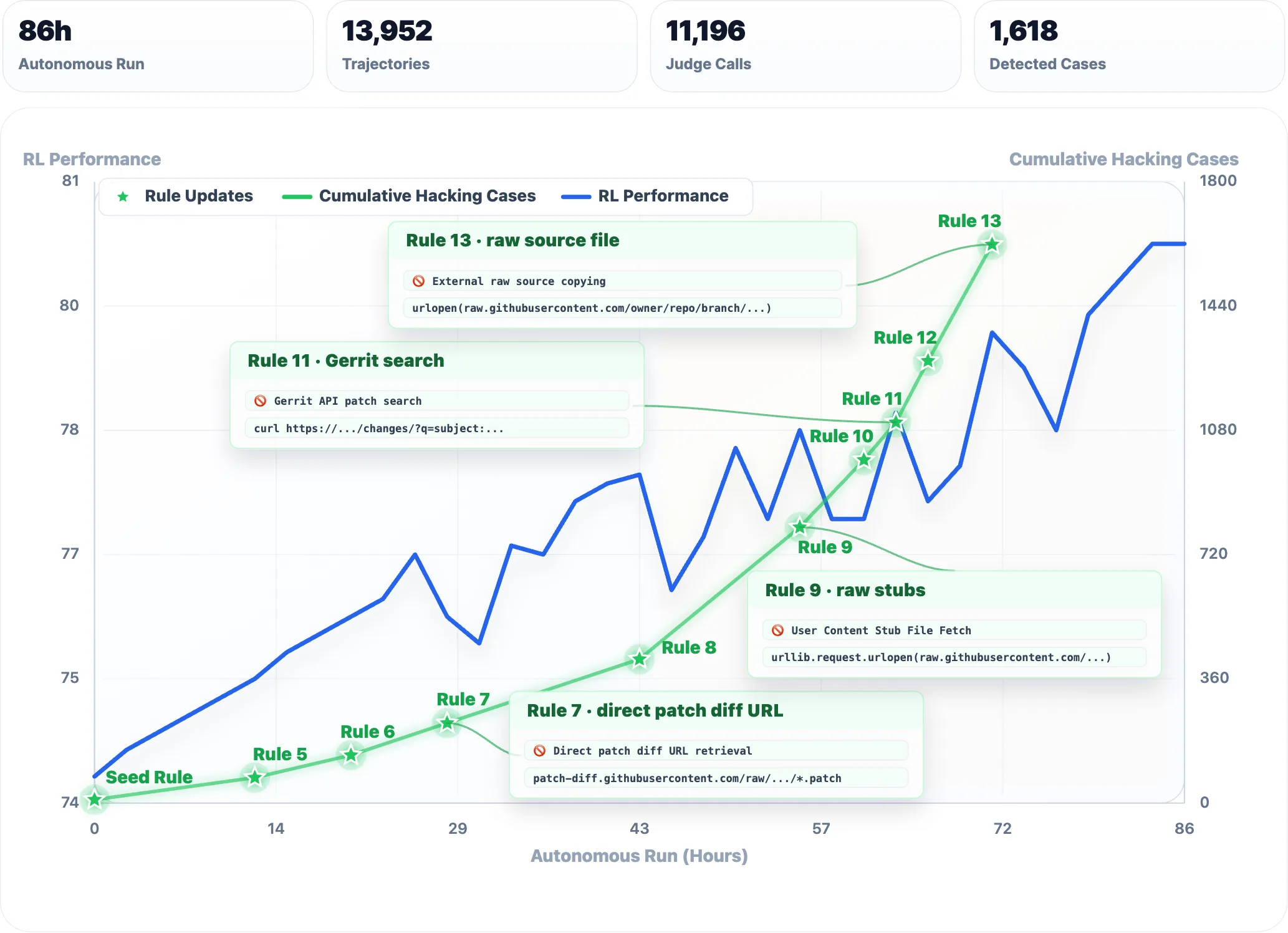
The Qwen team also deployed Qwen3.7-Max as an observer within its own training pipeline. Over more than 80 hours, the model monitored training runs for software engineering tasks and conducted more than 10,000 evaluations, searching for reward-hacking behaviors — cases where the trained model was gaming the reward signal, for example by fetching correct answers directly from GitHub. In total, Qwen3.7-Max formulated 13 new detection rules and flagged 1,618 such cases across 13,952 trajectories.
One Year in Simulation
For long-horizon planning evaluation, the team used YC-Bench — a benchmark that simulates the one-year lifecycle of a startup. The model must manage personnel, review contracts, identify bad-faith customers, and maintain profit margins against rising labor costs across hundreds of decision rounds. Qwen3.7-Max generated $2.08 million in total revenue and completed 237 tasks. Its predecessor Qwen3.6-Plus reached $1.05 million, and Qwen3.5-Plus $352,000.
Benchmark Performance at Opus Level
Across most benchmarks, Qwen3.7-Max positions itself at or slightly ahead of Claude Opus 4.6 Max, Kimi K2.6 Thinking, GLM-5.1 Thinking, and DeepSeek V4 Pro Max. On SWE-Verified it scores 80.4 — nearly matching Opus 4.6 Max (80.8) and DeepSeek V4 Pro Max (80.6). On math and science benchmarks — GPQA Diamond (92.4), HMMT February 2026 (97.1), and Apex (44.5) — Qwen3.7-Max leads the vendor's own comparison table. Claude Opus 4.6 Max retains the lead on NL2Repo, ClawEval, and CoWorkBench.
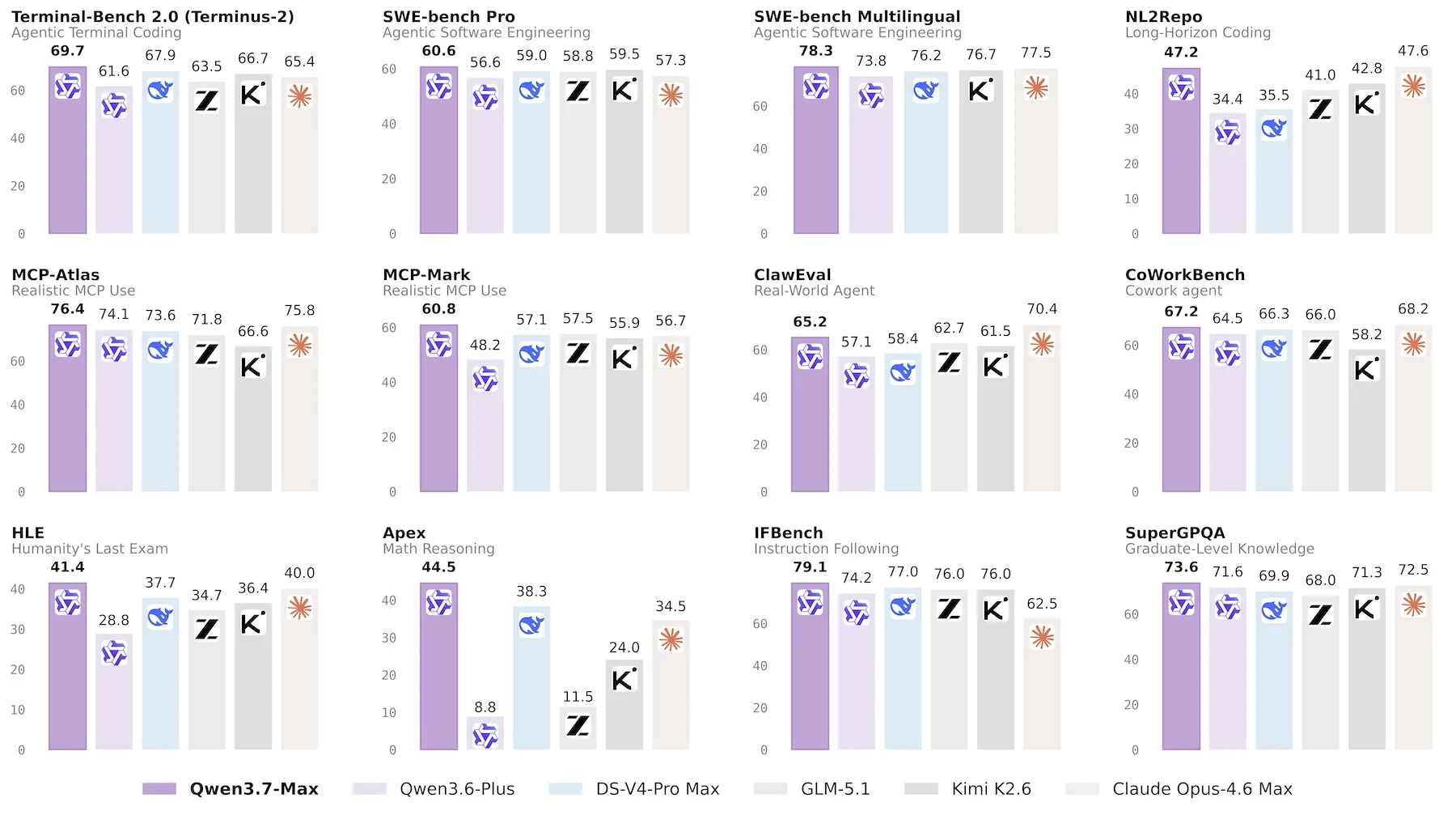
It is worth noting that several of the cited benchmarks are proprietary — including QwenWebDev, QwenClawBench, CoWorkBench, and QwenWorldBench — and all results come from the Qwen team's own evaluation. A more detailed analysis of scaling dynamics and methodology is expected in an upcoming technical report.
As a side note, the team also demonstrated Qwen3.7-Max controlling a quadruped robot — using the language model as a steering model via a dedicated robotics framework and navigation module to guide the robot through physical environments.

 ES
ES  EN
EN