

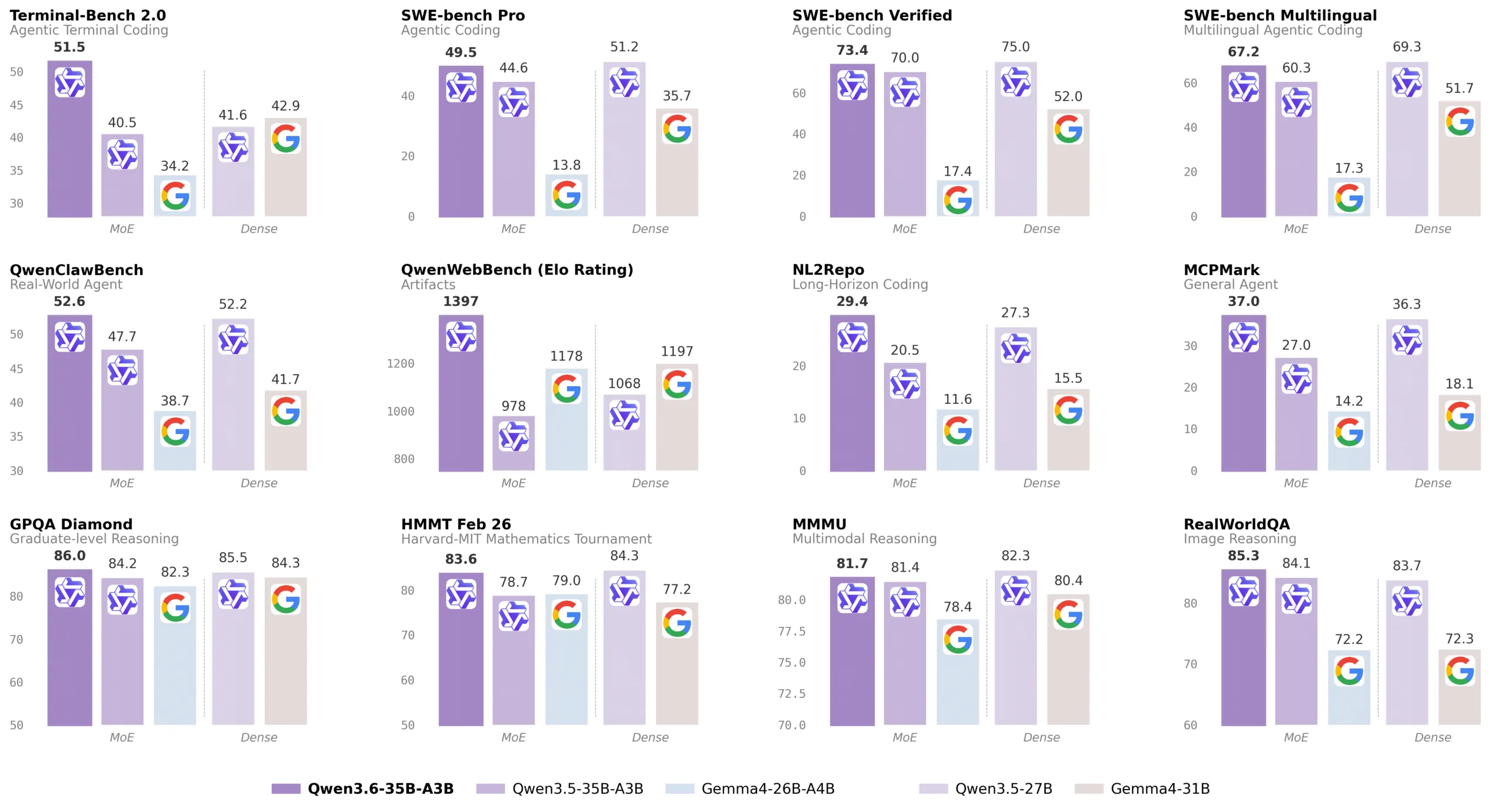
Alibaba says the model significantly outperforms its predecessor, Qwen3.5-35B-A3B, in agentic coding tasks, where the AI can independently handle programming-related work. Compared with Google’s open Gemma 4-31B, Qwen3.6-35B-A3B reportedly leads across all listed coding benchmarks. For example, it scores 73.4 versus 52.0 on SWE-bench Verified and 51.5 versus 42.9 on Terminal-Bench 2.0. It also performs better on knowledge and reasoning benchmarks such as GPQA (86.0 vs. 84.3) and AIME26 (92.7 vs. 89.2). For image and video tasks, Alibaba claims the model can even compete with Claude Sonnet 4.5.
The model includes both a thinking mode and a non-thinking mode. Users can test it in Qwen Studio, access it through the API as Qwen3.6-Flash via Alibaba Cloud Model Studio, or download the weights from Hugging Face and ModelScope.

 ES
ES  EN
EN