

Anthropic released Claude Opus 4.6 as an upgrade to its former top model, Opus 4.5. The most significant change is the introduction of a one-million-token context window, currently available in beta.
This, however, intensifies a known challenge: the more context a model must process, the more its performance can degrade—a phenomenon known as “context rot.” Anthropic addresses this with improvements to the model itself and a new “Compaction” feature that automatically summarizes older context before the window is filled.
According to Anthropic, the improvement is clearly visible in benchmarks. In MRCR v2, a test measuring the ability to find hidden information in large text corpora, Opus 4.6 scores 76% at one million tokens. Under the same conditions, the smaller Sonnet 4.5 reaches only 18.5%.
The model is available immediately on claude.ai, via the API, and across all major cloud platforms. Standard pricing remains $5 per million input tokens and $25 per million output tokens. For prompts exceeding 200,000 tokens, premium pricing applies: $10 per million input tokens and $37.50 per million output tokens
Opus 4.6 outperforms GPT-5.2 in knowledge-work benchmarks
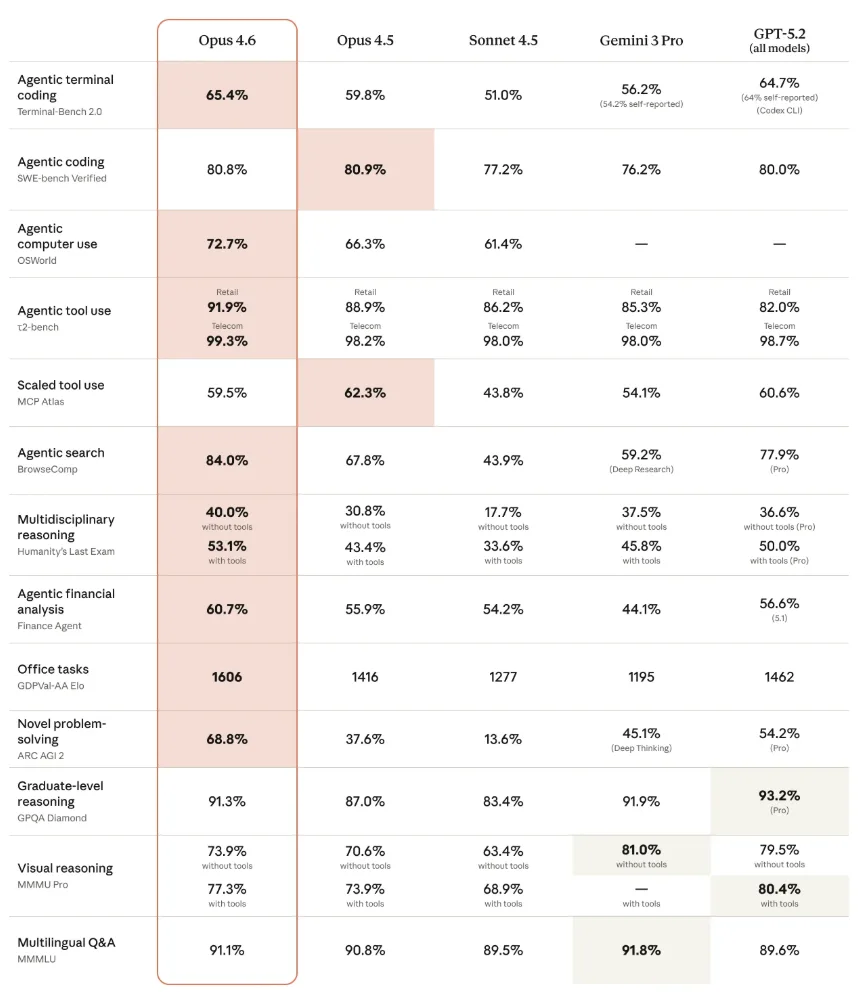
Across multiple benchmarks, Anthropic reports industry-leading results. On the GDPval-AA benchmark, which evaluates economically relevant knowledge work in areas such as finance and law, Opus 4.6 achieves an Elo score of 1606. This represents a 144-point lead over OpenAI’s strongest GPT-5.2 variant (1462) and a 190-point improvement over its own predecessor, Opus 4.5 (1416).
On Humanity’s Last Exam, a complex, multidisciplinary reasoning test, the model scores 53.1% with tools, ahead of all competitors. On the agentic coding benchmark Terminal-Bench 2.0, Opus 4.6 achieves 65.4%, again the highest score. On BrowseComp, which measures the ability to locate hard-to-find information online, the model reaches 84%. As always, benchmarks are only an indicator of real-world performance.
Improved coding capabilities for more autonomous work
Beyond information retrieval, Anthropic has enhanced the model’s programming capabilities. Opus 4.6 is designed to plan more carefully, work autonomously for longer periods, and operate more reliably in large codebases. It also brings improved code review and debugging abilities, allowing the model to better identify its own mistakes.
On the well-known SWE-bench coding benchmark, Opus 4.6 does not surpass Opus 4.5 with the standard prompt. With prompt tuning, however, it performs slightly better, reaching 81.42%.
Anthropic notes that the model can overthink simple tasks. Opus 4.6 checks its conclusions more frequently and thoroughly, which improves results on complex problems but can increase cost and latency for simpler queries. In such cases, Anthropic recommends reducing the new Effort parameter from the default “high” to “medium.”
New features for developers and office users
Anthropic is introducing several new API features for developers. With “Adaptive Thinking,” the model can decide on its own when deeper reasoning is beneficial. The Compaction feature automatically summarizes older context as conversations approach the context limit. The maximum output length has been increased to 128,000 tokens.
In Claude Code, users can now deploy “Agent Teams,” where multiple AI agents work in parallel and coordinate autonomously. This feature is currently available as a research preview.
For office users, Anthropic has improved the Excel integration and introduced a new PowerPoint integration, also as a research preview. Claude in Excel can now process unstructured data, infer the correct structure automatically, and apply multi-step changes in a single pass.
No major advances in safety
Anthropic emphasizes that performance gains have not come at the expense of safety. In automated behavioral audits, Opus 4.6 shows low rates of undesirable behaviors such as deception, sycophancy, or cooperation in misuse.
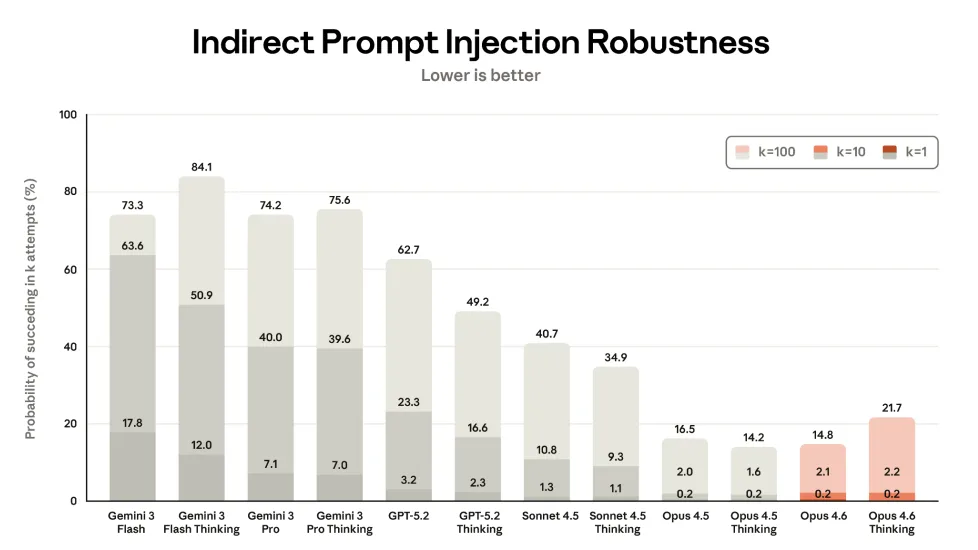
However, Opus 4.6 Thinking is slightly more vulnerable to indirect prompt-injection attacks than its already vulnerable predecessor—a concern particularly relevant for agentic AI models.
Security
Automated audits show that Opus 4.6 has a low propensity for undesirable behaviors, including deception, flattery, reinforcing user misconceptions, and assisting in wrongdoing.
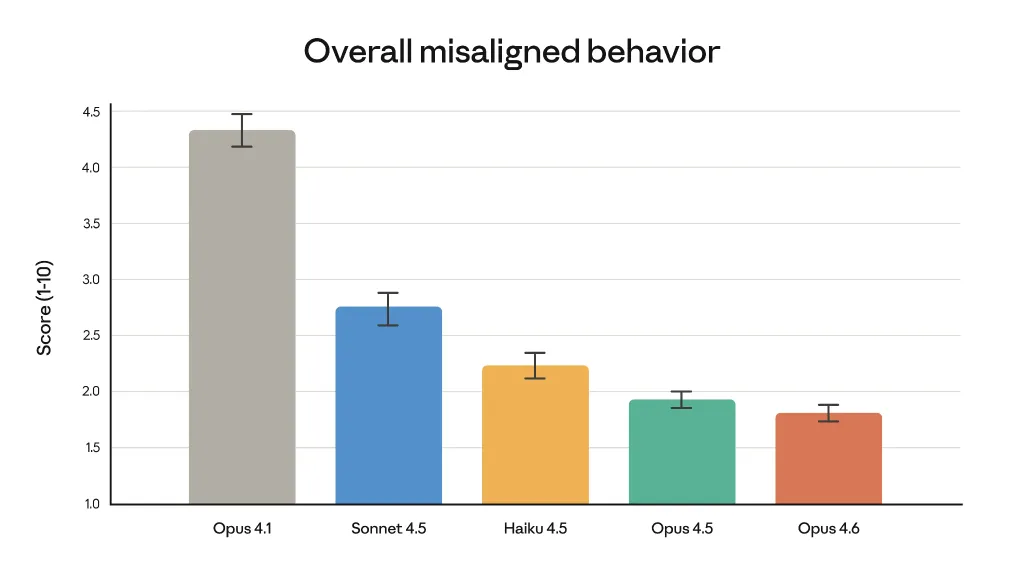
To evaluate the model, the company conducted its most comprehensive assessment to date, introducing new testing methodologies for the first time and refining existing evaluation approaches.
Availability and new features
Claude Opus 4.6 is now available via the web interface, the API, and across major cloud platforms.
New features in the developer toolkit include:
-
Adaptive Thinking — the model autonomously decides when deeper reasoning is required;
-
Effort control — four levels of computational intensity, from low to maximum;
-
Context compaction — automatically summarizes and replaces older context as conversations approach token limits.
Opus 4.6 also delivers improved performance with office tools such as Excel and PowerPoint.
Conclusion
Claude Opus 4.6 marks a clear step forward in large-context AI systems. By combining a one-million-token window with improved context compaction, Anthropic shows it can scale long-document reasoning without a proportional drop in usefulness. Strong benchmark results in knowledge work, agentic coding, and information retrieval position Opus 4.6 as a serious challenger to leading GPT-5.x variants, especially for complex, professional tasks.
At the same time, the model’s tendency toward overthinking on simpler requests and its increased sensitivity to indirect prompt injection highlight the trade-offs of pushing autonomy and context length further. Overall, Opus 4.6 reinforces Anthropic’s strategy: prioritize reliability in large-scale reasoning and developer workflows, while accepting that careful configuration and human oversight remain essential as models grow more powerful.

 ES
ES  EN
EN