

OpenAI’s GPT-5.2 Pro has achieved a new record on the highly challenging FrontierMath benchmark, according to tests conducted by Epoch AI. The model scored 31% on the hardest Tier 4 level, a significant leap from the previous best result of 19% set by Gemini 3 Pro. Due to API issues, Epoch AI tested the model manually via the ChatGPT web interface.
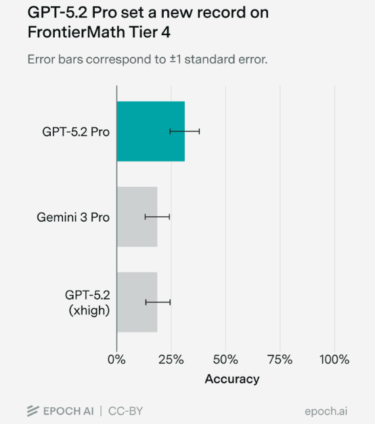
GPT-5.2 Pro’s performance clearly surpassed its closest competitors: Gemini 3 Pro (19%) and GPT-5.2 xhigh (17%). Source: Epoch AI
Out of 48 tasks, GPT-5.2 Pro successfully solved 15, including four problems that no previous model had managed to solve. Several professional mathematicians evaluated the solutions, largely praising their quality, though some criticized occasional lack of precision in the reasoning.
The results reinforce recent positive reports about advanced AI models — particularly GPT-5 Thinking and GPT-5 Pro — as powerful tools for solving complex mathematical problems. According to some accounts, GPT-5 has even solved Erdős problems autonomously, while in other cases it acted as an advanced assistant

 ES
ES  EN
EN