

The standard GPT-5.4 model is available in the ChatGPT web interface, via the API, and in the Codex tool. The GPT-5.4 Thinking version has been opened to Plus, Team, and Pro subscribers.
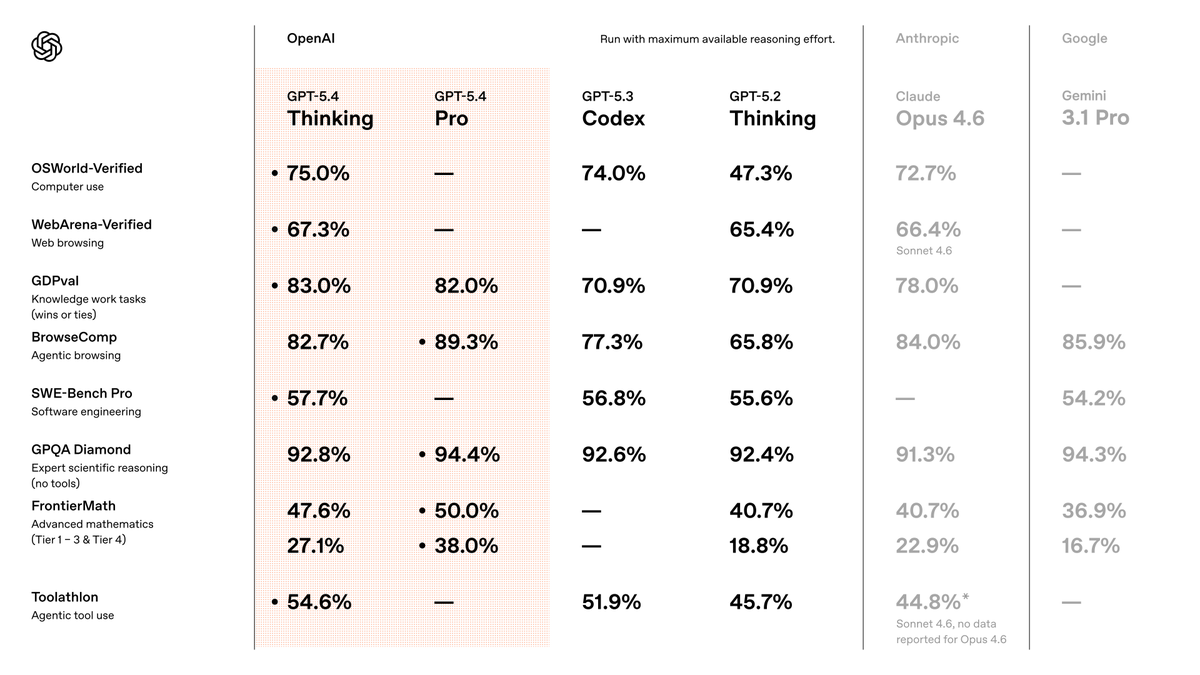
GPT-5.4 Pro is intended for Pro users and Enterprise clients, and it is also available through the API.
Base pricing starts at $2.5 per 1 million input tokens and $15 per 1 million output tokens. Pricing for the Pro version is significantly higher: $30 and $180 per 1 million tokens, respectively.
Performance in real-world tasks
GPT-5.4 delivers more stable and higher-quality results in practical use cases. In the GDPval benchmark, which evaluates task performance across 44 professions, the model reached a score of 83%. This suggests the system performs at the level of domain specialists or exceeds them. By comparison, GPT-5.2 scored 70.9%.
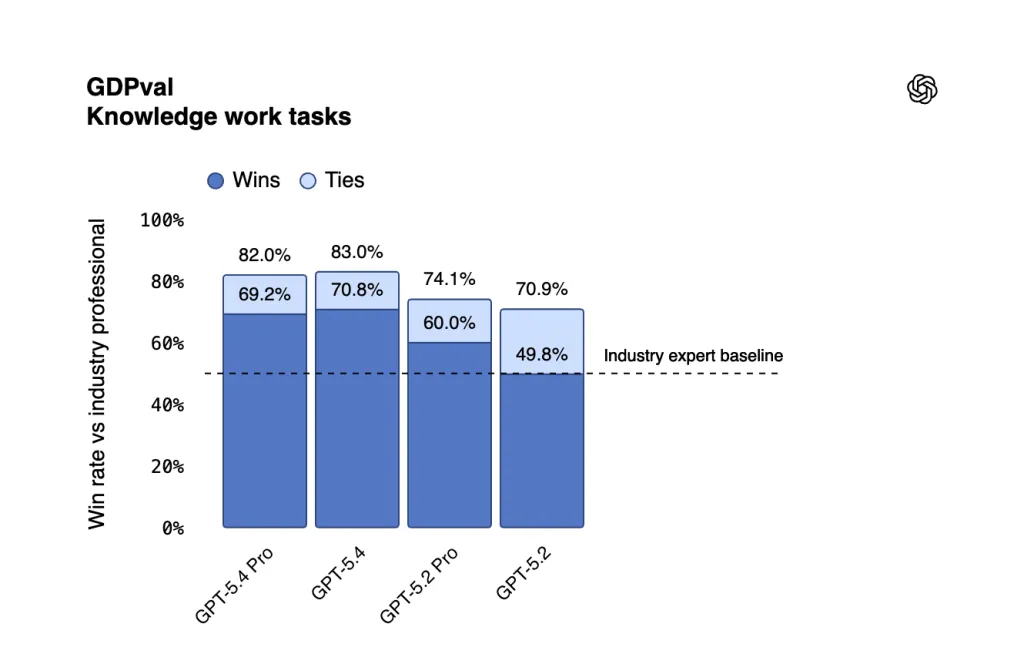
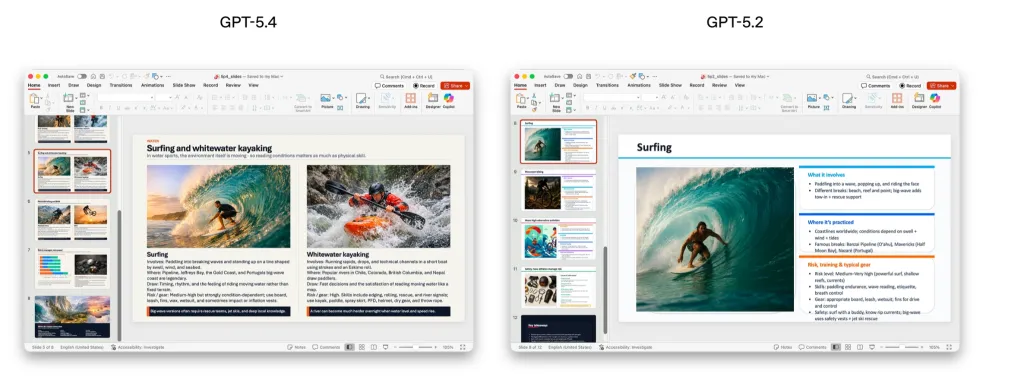
Developers placed particular emphasis on work involving spreadsheets, presentations, and documents. In tasks comparable to those handled by a junior investment banking analyst, GPT-5.4 scored 87.3%, versus 68.4% for GPT-5.2.
Presentations created by the new model were preferred by evaluators in 68% of cases due to better aesthetics, more variety, and more effective use of image generation.
GPT-5.4 also became OpenAI’s most accurate model in terms of factual reliability. In tests using prompts that contained known errors in advance:
- individual claims were false 33% less often;
- complete answers contained errors 18% less often compared with GPT-5.2.
Computer vision
This version is the first to receive built-in computer vision capabilities and PC control. The model can use a mouse and keyboard by ориентing itself via screenshots, and it can also write automation code through Playwright.
Its behavior can be configured for specific scenarios depending on the acceptable level of risk.
In the OSWorld-Verified benchmark for desktop control, GPT-5.4 successfully completed 75% of tasks, outperforming the previous version at 47.3% and even humans at 72.4%. The improvement is linked to stronger visual perception:
- in the MMMU-Pro test for understanding and reasoning, it scored 81.2% versus 79.5% for GPT-5.2;
- in OmniDocBench for document analysis, the average error rate fell from 0.140 to 0.109.
Programming
In coding, the model has caught up with the specialized GPT-5.3-Codex, while operating faster.
Codex now includes a /fast mode, which speeds up generation by 1.5x without reducing quality. According to internal testing, GPT-5.4 posted strong results in complex frontend development tasks.
OpenAI also introduced an experimental skill called Playwright (Interactive). It allows the model to visually debug web and Electron applications by testing its own code while generating it.
Tools
GPT-5.4 introduces a Tool Search function. Previously, the system had to preload descriptions of all available plugins into context. That added thousands of extra tokens to every request and increased cost.
Now the model receives only a basic list and can independently locate and load the required parameters when needed. In tests based on MCP Atlas, this approach reduced token usage by 47% without sacrificing accuracy.
Web search has also become more effective. In the BrowseComp benchmark, scores improved by 17%, while the Pro version reached a record 89.3%. GPT-5.4 Thinking is better at gathering information from multiple sources, handling complex queries, and producing more structured responses.
Controllability and context
When handling complex prompts, GPT-5.4 Thinking in ChatGPT first shows the user an action plan. This makes it possible to adjust direction on the fly without restarting generation or adding unnecessary clarifications. The feature is already available on the website and in the Android app, with iOS support coming soon.
The model also retains context better in long conversations and spends more time reasoning through difficult tasks. This helps preserve coherence and relevance even when working with large volumes of information.

 ES
ES  EN
EN