

Anyone who wants an AI agent today that can independently search for flights, fill out forms, or browse product listings in a browser is still dependent on closed systems. The most capable web agents come from companies that do not disclose either their training data or their methods.
The Allen Institute for AI (AI2) wants to change that with MolmoWeb, a fully open web agent released in two sizes with 4 billion and 8 billion parameters, along with all training data, model weights, and evaluation tools.
“Web agents today are where large language models were before OLMo,” the team wrote in its announcement. In its view, the open-source community needs an open foundation.
MolmoWeb is intended to provide exactly that, without distilling knowledge from proprietary systems. Instead, training is based on a mix of human demonstrations and automatically generated browsing trajectories. The models were trained exclusively with supervised fine-tuning on 64 H100 GPUs, without reinforcement learning. The foundation is the Molmo2 architecture, using Qwen3 as the language model and SigLIP2 as the vision encoder.
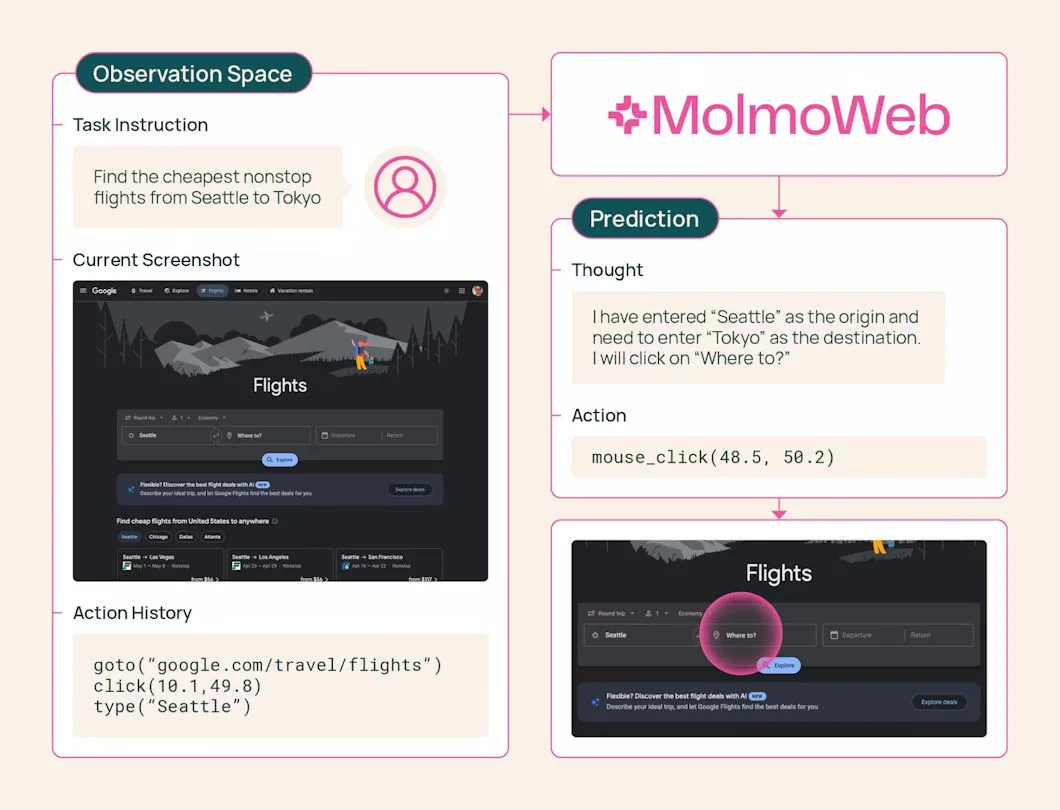
The agent sees what the user sees
The agent receives a screenshot of the current browser view, formulates a short thought about what to do next, and then takes an action: click, type, scroll, switch tabs, or open a URL. After that, it captures a new screenshot and starts again.
MolmoWeb does not read a website’s source code or access its technical page structure. It works exclusively with what a human would see on the screen. According to the developers, this makes the agent more robust because the appearance of a website changes less often than its underlying code. It also makes it easier to understand why the agent made a particular decision.
The largest public dataset of its kind
The real innovation may be less the model itself than the accompanying training dataset called MolmoWebMix. The biggest obstacle in building open web agents so far has simply been the lack of suitable data.
MolmoWebMix consists of three building blocks. First, the researchers had crowdworkers complete real browsing tasks and recorded every click and page transition. This produced 36,000 complete task trajectories across more than 1,100 websites. The team describes it as the largest publicly available dataset of human web task execution to date.
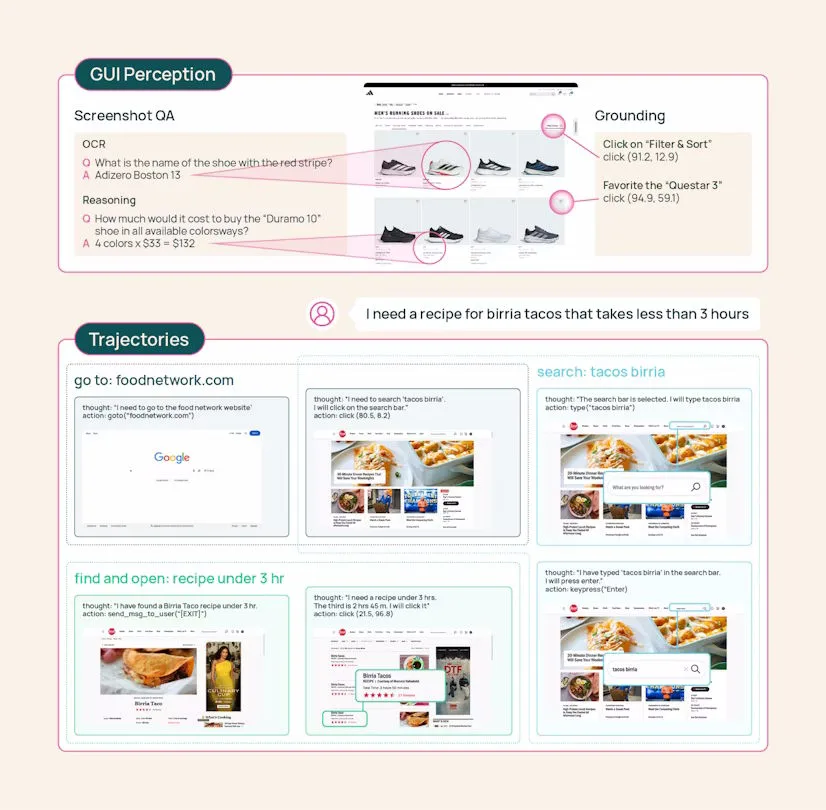
Second, automated agents generated additional trajectories to scale the dataset beyond what human annotation alone could provide. This included a three-role system: a planner based on Gemini 2.5 Flash breaks tasks into subgoals, an operator executes browser actions, and a verifier based on GPT-4o checks screenshots to confirm whether each subgoal was achieved.
Finally, the dataset includes more than 2.2 million screenshot question-answer pairs for reading and understanding webpage content. UI element localization is trained in a separate grounding dataset containing more than 7 million examples.
One counterintuitive result from the accompanying paper is that, on identical tasks, MolmoWeb learns better from synthetically generated browsing trajectories than from human demonstrations. The researchers explain this by noting that humans tend to experiment more and take detours on unfamiliar websites.
Automated agents, by contrast, have access to the technical page structure and find more direct paths, which makes imitation learning easier. At the same time, ablation studies show that just 10% of the dataset already delivers 85% to 90% of final performance.
Small models beat larger ones on multiple benchmarks
Despite their modest size, both MolmoWeb models achieve state-of-the-art results among open web agents, according to the developers. On the WebVoyager benchmark, which tests navigation across 15 popular websites such as GitHub and Google Flights, the 8B model reaches 78.2%.
That puts it ahead of the previously leading open model Fara-7B on all four tested benchmarks and close to OpenAI’s o3 at 79.3%. On the DeepShop benchmark, MolmoWeb-8B trails GPT-5 by only six points.
According to the developers, MolmoWeb also outperforms agents built on the much larger GPT-4o, even when those systems additionally use annotated screenshots and structured page data. For precise UI element localization, a specialized 8B model surpasses Anthropic’s Claude 3.7 and OpenAI’s CUA on the ScreenSpot benchmarks, although AI2 selected somewhat older proprietary models as comparison points.
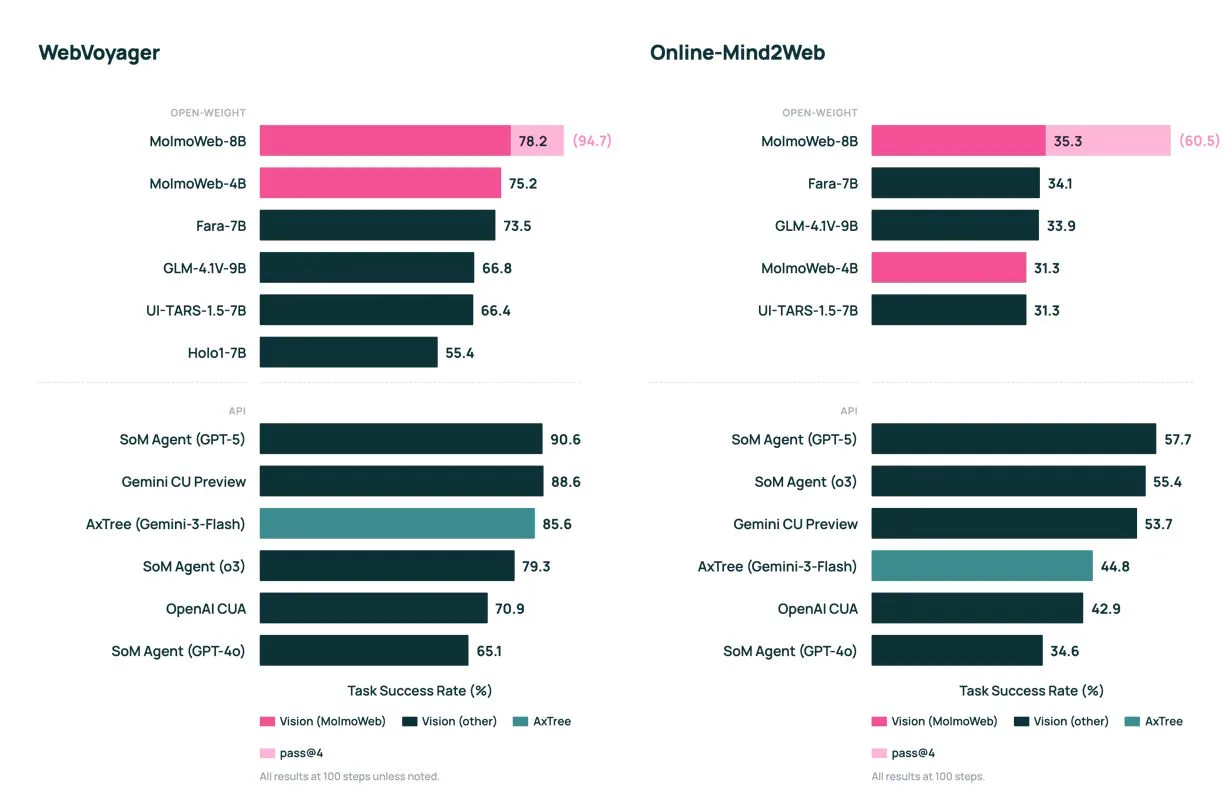
However, MolmoWeb still trails its own “teacher,” a Gemini-based agent with access to technical page structure, by five points. This highlights the cost of the purely visual approach: a system that only looks at screenshots must implicitly perform text recognition as well, whereas an agent with access to the page structure gets that information directly.
Another finding is that if the agent attempts the same task multiple times independently and the best result is selected, the success rate on WebVoyager rises from 78.2% to 94.7%. Extra compute at inference time can therefore significantly improve reliability.
No logins, no payments, many open questions
The developers openly acknowledge the system’s limitations. As a purely visual model, MolmoWeb can misread text in screenshots. Performance declines when instructions are ambiguous or involve many constraints. Tasks that require logins or financial transactions were deliberately excluded from training for safety reasons.
In the hosted demo, only certain websites are allowed, inputs into password and credit card fields are blocked, and a Google interface checks prompts for problematic content. These safeguards, however, are part of the demo environment, not the model itself.
More fundamental questions remain unanswered. How should web agents deal with website terms of service? How can they be prevented from accessing illegal content or carrying out irreversible actions? The team argues that full disclosure of all components will allow more people to work on these problems. MolmoWeb is available on Hugging Face and GitHub under the Apache 2.0 license.
Only recently, the academic project OpenSeeker pursued a similar approach for AI search agents: fully open data, code, and model weights as an answer to the data monopolies of major corporations. MolmoWeb now extends that trend into browser automation.
The Allen Institute for AI (AI2), known for its ambition to advance transparent AI, recently suffered a major setback: Microsoft hired several of its leading AI researchers. They are set to work on model development within Microsoft’s new superintelligence team, led by DeepMind co-founder Mustafa Suleyman.

 ES
ES  EN
EN