
While multimodal AI models achieve over 90% on expert-level benchmarks such as MMMU, a new study by UniPat AI exposes a striking gap. The same systems struggle with elementary visual tasks that humans master before language acquisition. The best-performing model tested, Gemini-3-Pro-Preview, achieved only 49.7% according to the study, while human adults reached 94.1%.
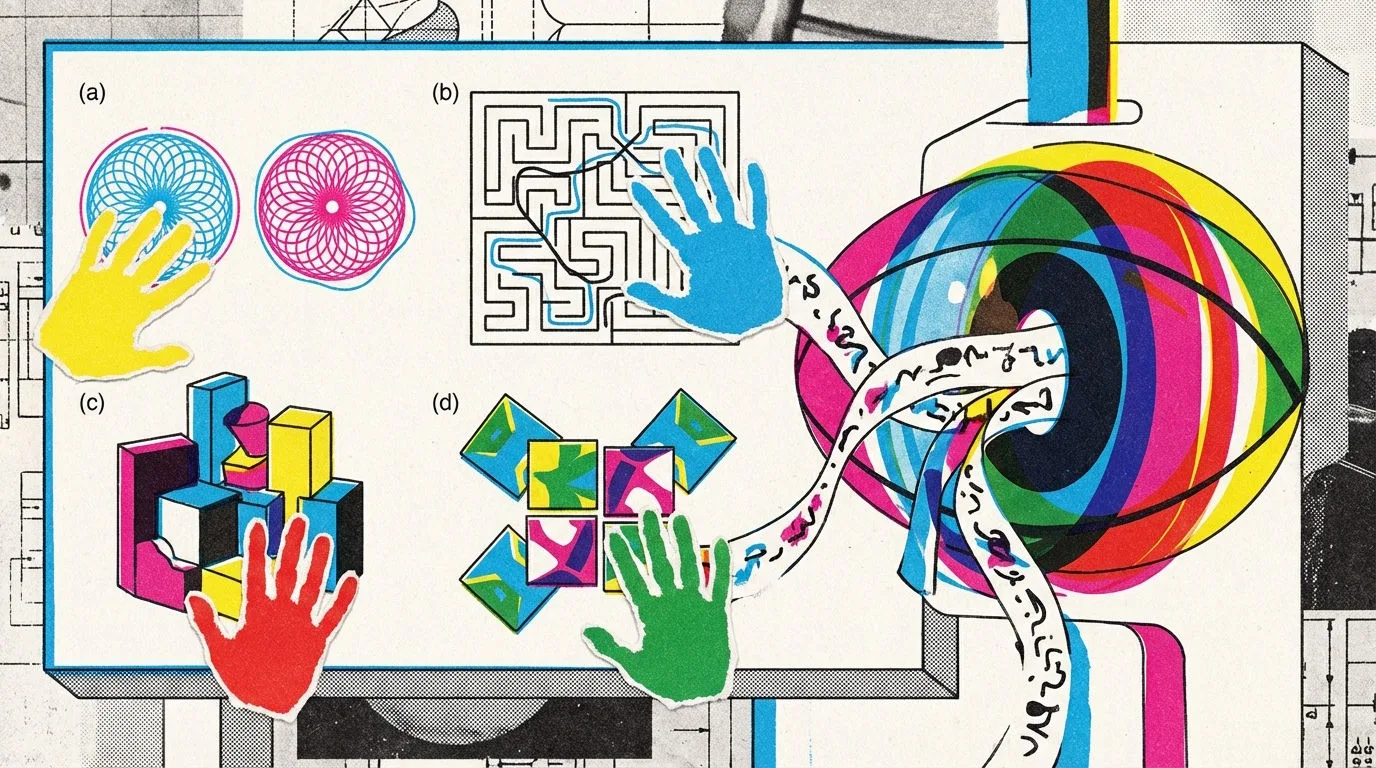
In one example of a fine-grained visual perception task, a hexagonal honeycomb puzzle with a missing white segment, Gemini-3-Pro-Preview selected the wrong option. The model over-verbalized the geometry and failed to capture the exact contour, choosing option D instead of the correct option B.

Researchers from Chinese institutions including UniPat AI, Peking University, Alibaba Group, and MoonShot AI developed a new benchmark called BabyVision, consisting of 388 tasks across four categories. These tasks test abilities that developmental psychology shows humans acquire within the first months of life: fine-grained visual discrimination (such as detecting subtle differences between similar patterns), line tracking through mazes or intersections, spatial perception (for example counting occluded 3D blocks), and visual pattern recognition involving rotations and mirrorings.
80 children vs. six frontier models
In a comparative study involving 80 children from different age groups, the scale of the discrepancy became clear. Most frontier AI models performed below the average level of three-year-old children. Only Gemini-3-Pro-Preview consistently surpassed this group, yet still lagged about 20 percentage points behind typical six-year-olds.
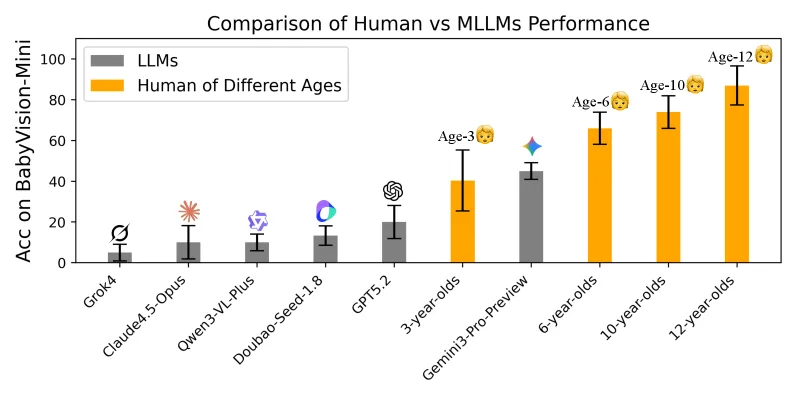
A bar chart comparing AI models with children of different ages on the BabyVision-Mini test shows that most AI models score between 5% and 45%, while children aged 3 to 12 score between 40% and 90%. Grok-4 reaches about 5%, Claude-4.5-Opus around 12%, and GPT-5.2 about 20%. Three-year-olds reach roughly 40%, Gemini-3-Pro-Preview about 45%, six-year-olds about 65%, and twelve-year-olds around 88%.
Among proprietary models, Gemini-3-Pro leads by a wide margin, followed by GPT-5.2 at 34.4%, ByteDance’s Doubao-1.8 at 30.2%, and Claude-4.5-Opus at just 14.2%. Open-source models perform even worse: the best among them, Qwen3VL-235B-Thinking, reaches only 22.2%.
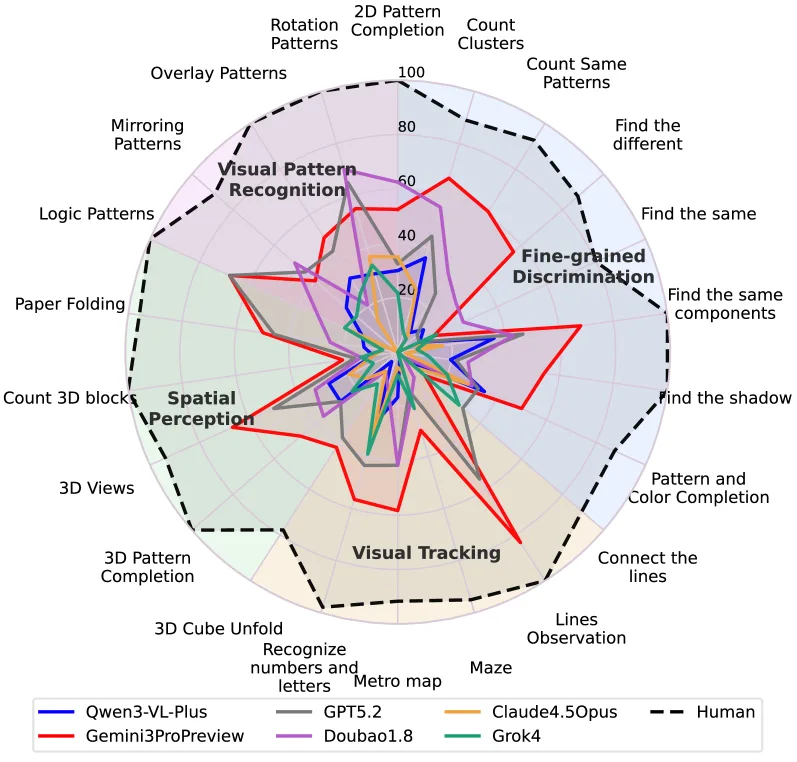
Results are especially poor for certain task types. In counting occluded 3D blocks, even the best model achieved only 20.5%, while humans scored 100%. In the “Lines Observation” task, which requires tracking lines through intersections, only Gemini reached 83.3%, while most other models scored zero.
A radar chart across 22 BabyVision task types shows human performance near 100% in all categories, while all AI models remain far below, particularly in visual tracking and spatial perception.
The verbalization bottleneck
The researchers attribute all these failures to a shared issue they call the verbalization bottleneck. Current multimodal models translate visual input into language representations before reasoning. Visual information that cannot be expressed in language is lost in the process.
Semantic content such as “a red car on a road” is easy to verbalize. Geometric relationships, however, resist verbalization: the exact curvature of a boundary or the precise position of an intersection cannot be captured without loss in words. According to the authors, BabyVision is explicitly designed to target these non-verbalizable visual properties.
Mazes as the ultimate challenge
The researchers also introduced BabyVision-Gen, an extension with 280 tasks where models must demonstrate solutions via image generation, such as drawing paths or marking differences. Humans often solve such tasks by drawing rather than verbalizing. Children externalize visual reasoning through drawing long before they can describe solutions verbally.
The tested image generators show some promise. Nano Banana Pro achieves 18.3%, while GPT-Image-1.5 reaches 9.8%. On “spot the difference” tasks, Nano Banana Pro reaches 35.4%.
However, all generators fail completely on maze tasks and line-connection problems. These require continuous spatial coherence over extended sequences—something current architectures cannot maintain.
The researchers see Unified Multimodal Models, which natively integrate visual processing and generation, as a potential way forward. Such architectures could preserve visual representations throughout the reasoning process instead of compressing them into a linguistic bottleneck. The BabyVision benchmark, available on GitHub, is intended as a diagnostic tool to measure progress toward true visual intelligence.
Similarly, the ARC-AGI-3 benchmark developed by François Chollet tests fundamental cognitive abilities such as object permanence and causality. In its interactive mini-games—where AI agents must discover game mechanics on their own—current systems score zero points, while humans solve the tasks within minutes.

 ES
ES  EN
EN