

Taking into account the rapid development of artificial intelligence, one of the biggest challenges technology leaders increasingly face is the transition from an “experimental” phase to solutions that are truly “enterprise-ready.” While consumer chatbots and interactive platforms help shape public perception, businesses cannot succeed by relying on chat interfaces alone. In an era of increasingly aggressive competition, enterprises need a robust, scalable, and secure ecosystem—and this is exactly what Google aims to deliver with Vertex AI, Google Cloud’s unified AI and machine learning platform
Vertex AI is designed to position itself as the foundation for integrating generative AI into modern cloud infrastructure. It offers a comprehensive set of capabilities that bridge the gap between foundation models and production-grade applications. Rather than acting as a simple wrapper around large language models (LLMs), Vertex AI is a unified ML/AI ecosystem that treats generative AI as a first-class component of enterprise cloud architecture.
At the core of Vertex AI is Model Garden—a centralized marketplace that provides access to more than 200 curated foundation models, including the powerful multimodal Gemini 2.5 Pro with an impressive two-million-token context window. This article explores the architecture of Vertex AI, explains how Model Garden functions as an “app store” for intelligent systems, and examines the technical foundations that make the platform a base layer for the next generation of enterprise software.
Core architecture: a unified platform
Vertex AI is not a loose collection of tools, but a single, integrated data and AI ecosystem designed to overcome the fragmentation of data, tools, and teams that has long plagued machine learning initiatives. Traditionally, AI development takes place in silos, with data scattered across multiple storage systems. Customer data may live in SQL databases, while unstructured documents sit in data lakes. When data is fragmented, AI models see only a “partial truth,” leading to biased outputs or high false-positive rates due to missing enterprise context.
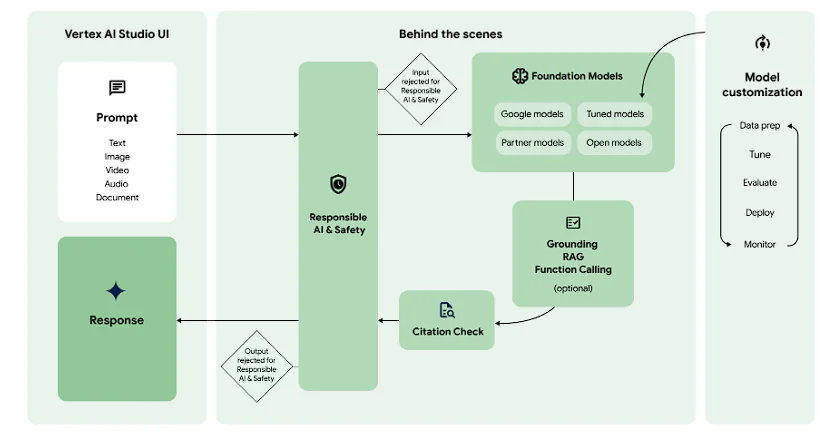
Vertex AI aims to integrate the entire lifecycle—from ingesting raw data in BigQuery and Cloud Storage to monitoring production systems—acting as connective tissue between these previously disconnected components. Its native integration with BigQuery and Cloud Storage allows models to access data directly, without complex ETL pipelines.
The foundation: Google’s AI Hypercomputer
The generative AI layer of Vertex AI runs on top of Google’s AI Hypercomputer—an integrated supercomputing architecture built around:
TPU v5p and v5e (Tensor Processing Units)
Google’s TPUs are custom ASICs optimized for matrix multiplication, the core operation of deep learning.
-
TPU v5p (performance): Google’s flagship accelerator for large-scale training. A single TPU v5p pod can scale to 8,960 chips connected via Google’s high-speed inter-chip interconnect (ICI) at 4,800 Gbps. This delivers up to 2.8× faster training for GPT-3-scale models (175B parameters), significantly reducing time-to-market.
-
TPU v5e (efficiency): Designed for cost-optimized workloads, v5e is ideal for mid-scale training and high-throughput inference, offering up to 2.5× better price-performance for always-on production use.
NVIDIA H100/A100 GPUs for flexibility
For teams that rely on the NVIDIA CUDA ecosystem, Vertex AI provides first-class support for:
-
NVIDIA H100 (Hopper): Well suited for fine-tuning very large open-source models such as Llama 3.1 405B, which demand extreme memory bandwidth.
-
Jupiter networking: Google’s data-center networking fabric supports RDMA, minimizing CPU overhead and enabling near-local performance across distributed GPU clusters.
Dynamic orchestration
A key technical shift in Vertex AI is dynamic orchestration. In legacy environments, a single hardware failure during a multi-week training run could terminate the entire job.
-
Automated failover: Built on Google Kubernetes Engine (GKE), Vertex AI uses self-healing nodes that automatically migrate workloads when hardware failures occur.
-
Dynamic workload scheduling: Teams can request resources based on urgency, choosing flexible (lower-cost) starts or guaranteed starts for critical releases.
-
Serverless training: Vertex AI Serverless Training allows teams to submit code and data without managing infrastructure. The platform provisions resources, runs the job, and shuts everything down—charging only for compute seconds used.
Three entry points: discovery, experimentation, and automation
To serve data scientists, ML engineers, and application developers alike, Vertex AI offers three main entry points:
-
Model Garden: discovery
-
Vertex AI Studio: experimentation
-
Vertex AI Agent Builder: automation
Model Garden: a marketplace for discovery
Vertex AI Model Garden is a centralized hub for discovering, testing, fine-tuning, and deploying proprietary, open-source, and third-party AI models, including multimodal models for text, vision, and code. It integrates seamlessly with Vertex AI’s MLOps tooling, helping organizations select the right model for each task and deploy it efficiently on Google Cloud.
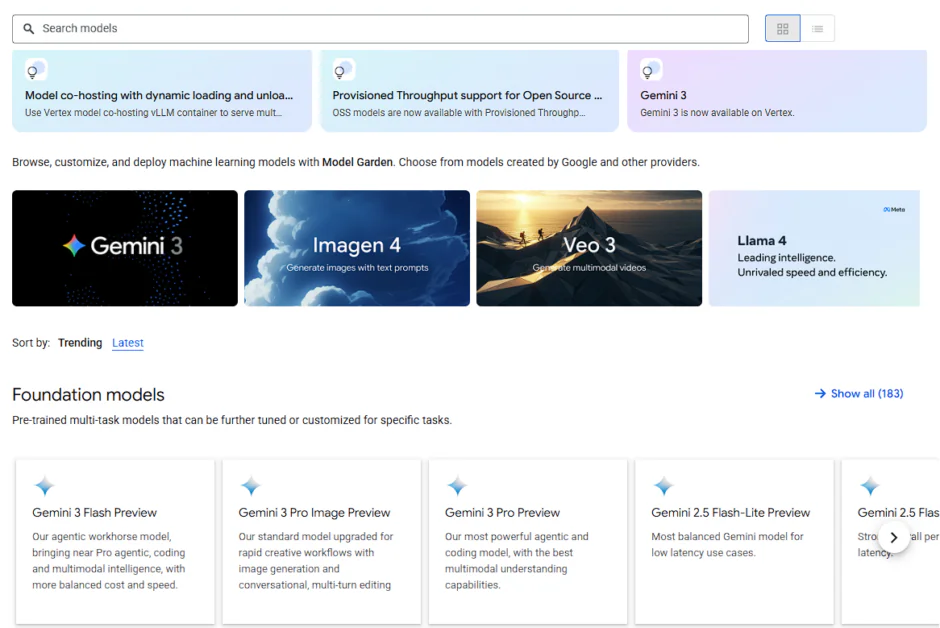
Models are organized into three tiers:
-
Google-built models: Flagship multimodal models such as Gemini, available in different sizes—from Pro (advanced reasoning) to Flash (low latency and high throughput).
-
Third-party proprietary models: Through strategic partnerships, Vertex AI offers models from providers like Anthropic (Claude 3.5) and Mistral under a “model-as-a-service” approach with a unified API and billing model.
-
Open-source and open-weight models: Including Meta’s Llama 3.2, Mistral, and Google’s Gemma, ideal for organizations that want to deploy models inside their own VPCs for maximum data isolation.
Model Garden simplifies deployment through managed endpoints:
-
One-click deployment: Automatically provisions TPU/GPU resources and exposes a production-ready REST API.
-
Hugging Face integration: Models can be deployed directly from Hugging Face Hub to Vertex endpoints.
-
Private Service Connect: Ensures model endpoints remain accessible only within a private corporate network.
Vertex AI Studio: the experimentation workspace
If Model Garden is about selection, Vertex AI Studio is about precision. It is the environment where foundation models are transformed into business-ready tools through prompt engineering, multimodal testing, and advanced tuning.
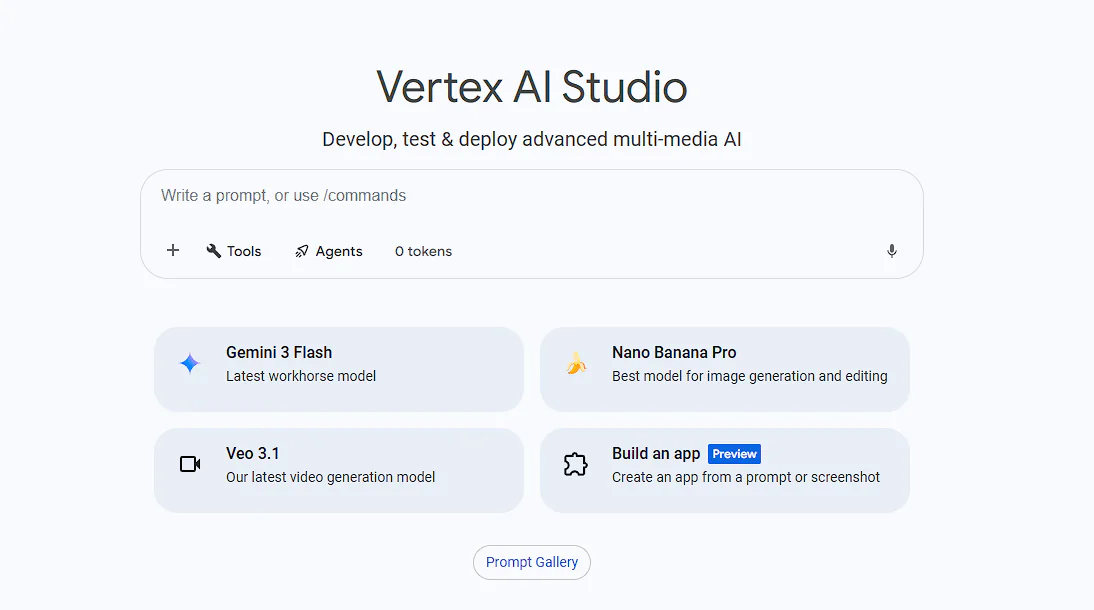
Multimodal prototyping
Studio natively supports multimodal workflows:
-
Video intelligence: Upload long videos and ask the model to identify specific events with timestamps.
-
Document analysis: Understand relationships between charts, tables, and surrounding text in large PDFs.
-
Code execution: Models can generate and run Python code in a secure sandbox to validate results.
Advanced tuning capabilities
-
Supervised fine-tuning (SFT): Train models using curated prompt-response pairs to enforce brand voice, structured outputs, or domain-specific language.
-
Context caching: Preload large static datasets (e.g., legal corpora or codebases) to reduce latency and cost.
-
Distillation: Use large models (Gemini 2.5 Pro) to train smaller, faster models (Gemini Flash) that retain high quality at lower cost.
Vertex AI Agent Builder: the automation factory
Vertex AI Agent Builder enables developers to create agents by combining foundation models with enterprise data and external APIs.
Grounding and RAG architecture
To address hallucinations, Agent Builder uses advanced grounding techniques:
-
Google Search grounding: Agents can fetch real-world data with source attribution.
-
Vertex AI Search (RAG-as-a-Service): Automatically indexes enterprise documents and ensures responses are based only on approved internal sources.
-
Vertex AI RAG Engine: Supports hybrid search, improving accuracy by up to 30% over standard LLM approaches.
Multi-agent orchestration (A2A protocol)
The Agent-to-Agent (A2A) protocol allows specialized agents to collaborate and interoperate with agents built on frameworks like LangChain or CrewAI.
Developer tooling
-
No-code console: Visual drag-and-drop interface for rapid prototyping.
-
Agent Development Kit (ADK): Python-based toolkit for code-driven development.
-
Vertex AI Agent Engine: Managed runtime that handles session persistence, scaling, and state management.
Conclusion: from “what if” to “what’s next”
Moving from impressive AI demos to production-ready enterprise systems has long been a major obstacle in digital transformation. Vertex AI is designed specifically to overcome this gap. By unifying data, infrastructure, and model management, Google Cloud shifts the focus from raw model power to the operational maturity of the AI lifecycle—laying the groundwork for sustainable, enterprise-scale AI adoption.






 ES
ES  EN
EN