

According to Baidu, Ernie 5.1 keeps the core capabilities of its predecessor but has only about one-third of the total parameters and roughly half of the active parameters used per request. The company also claims that the model’s pretraining costs were only around 6% of what comparable models typically require.
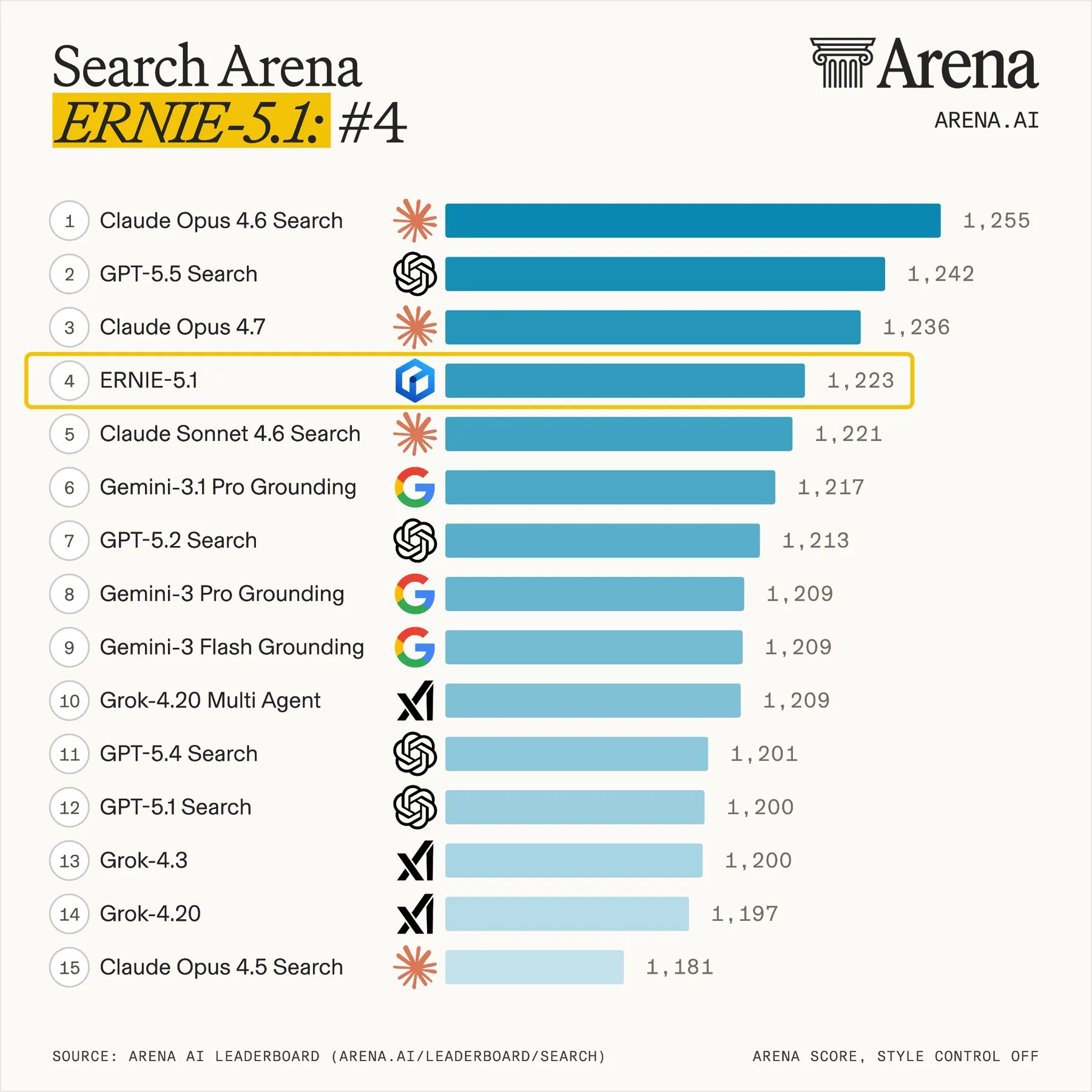
On the Arena-Search leaderboard, Ernie 5.1 scored 1,223 points on May 9. Baidu says this places the model fourth globally and first among Chinese models. It ranked behind Claude Opus 4.6 Search, GPT-5.5 Search and Claude Opus 4.7.
Baidu Claims Strong Results in Agentic AI and Reasoning Tasks
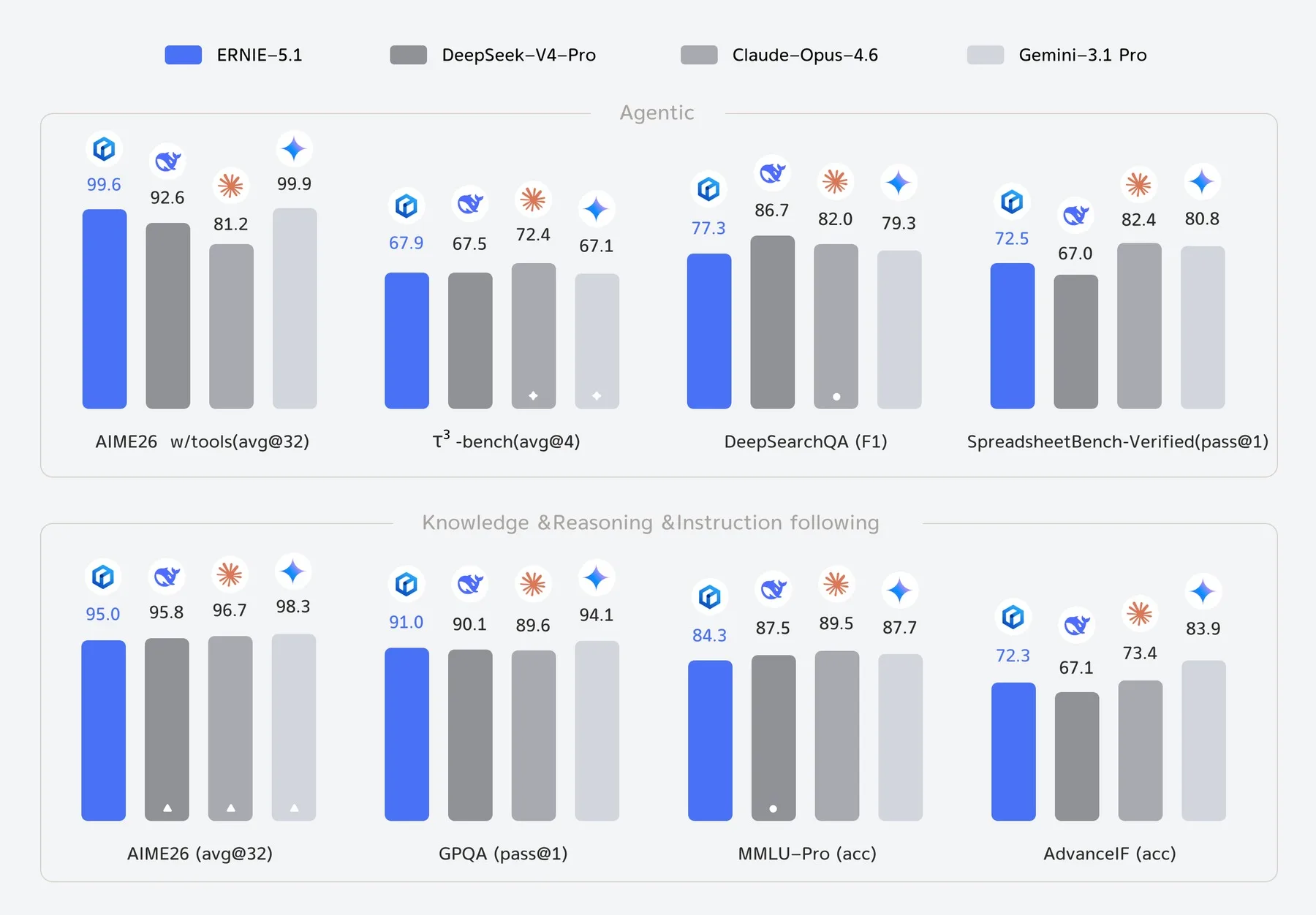
Baidu says Ernie 5.1 outperforms DeepSeek-V4-Pro in several benchmarks for autonomous AI agents, including τ³-bench and SpreadsheetBench-Verified.
In knowledge and reasoning tasks such as GPQA and MMLU-Pro, the company claims the model comes close to Google’s Gemini 3.1 Pro.
On the difficult mathematics benchmark AIME26, Ernie 5.1 reportedly ranks just behind Gemini 3.1 Pro when tool access is enabled. Baidu also says internal evaluations show the model performing at a level comparable to major commercial models from the global West in creative writing.
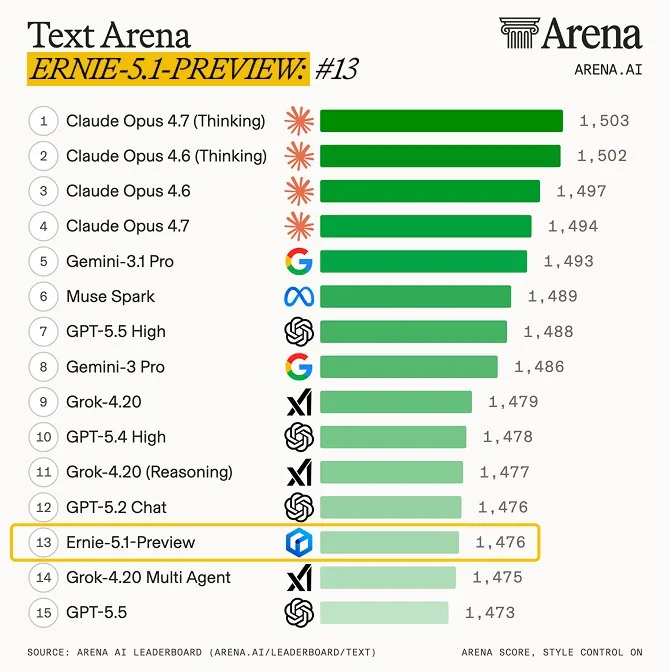
However, the picture is more mixed on text-focused rankings. On the Text-Arena leaderboard, the preview version of Ernie 5.1 scored 1,476 points, placing it 13th. The top positions are still held by Claude Opus variants and Gemini 3.1 Pro.
Ernie 5.1 Was Extracted From Ernie 5.0
Technically, Ernie 5.1 is not a model trained entirely from scratch. Instead, Baidu extracted it as a smaller sub-model from Ernie 5.0.
This was made possible by a training method the company calls Once-For-All. Instead of running a separate expensive pretraining process for every desired model size, Baidu optimizes a whole family of differently sized models during a single training run.
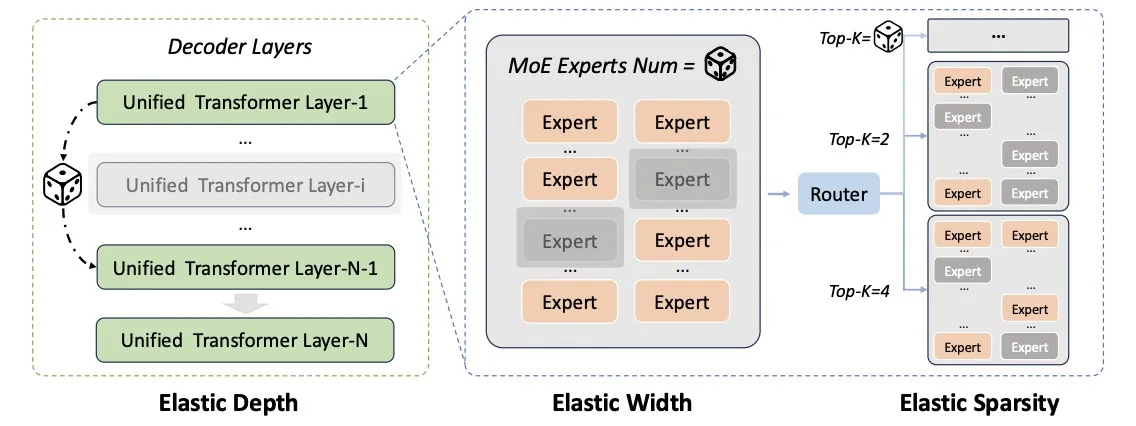
These models share weights but differ in depth, width and the number of specialized expert modules activated for each request.
From this model family, Baidu says it selected the best configuration for Ernie 5.1. This also explains the unusually low reported pretraining cost: much of the heavy compute work had already been performed for Ernie 5.0.
How Once-For-All Training Works
Baidu’s Once-For-All framework varies several parts of the architecture during one training process.
It adjusts:
- the depth of the model;
- the number of available expert modules;
- the number of experts activated per request;
- routing configurations inside the Mixture-of-Experts structure.
This allows Baidu to create multiple model sizes from a shared training foundation. In theory, the approach can reduce cost and make it easier to deploy models optimized for different use cases.
For Ernie 5.1, Baidu appears to have chosen a smaller configuration that keeps much of the performance of Ernie 5.0 while requiring fewer active parameters during inference.
Baidu Separates Key Reinforcement Learning Systems
For reinforcement learning fine-tuning, Baidu redesigned parts of its infrastructure.
Traditionally, several components of reinforcement learning training are tightly connected: model updates, generation of new responses and evaluation of those responses. Baidu now runs these as separate subsystems that can scale independently.
A central control system coordinates the process. The advantage is that each part can run on the hardware best suited to it, while bottlenecks in one stage do not block the rest of the training pipeline.
This is important because training large models with reinforcement learning is resource-intensive. Separating the workflow can make the process more flexible and efficient.
Reducing Instability During Reinforcement Learning
One challenge in reinforcement learning for large models is that the model used during training and the model used to generate new examples can drift apart. This can happen because different compute settings are used in each stage.
Such differences may destabilize training.
Baidu says it addresses this with a unified low-precision computation library. For Mixture-of-Experts models, the company also uses a correction mechanism that reportedly reduces this divergence by half without noticeably slowing training.
This is especially relevant for Ernie 5.1 because the model relies on a sparse expert-based architecture.
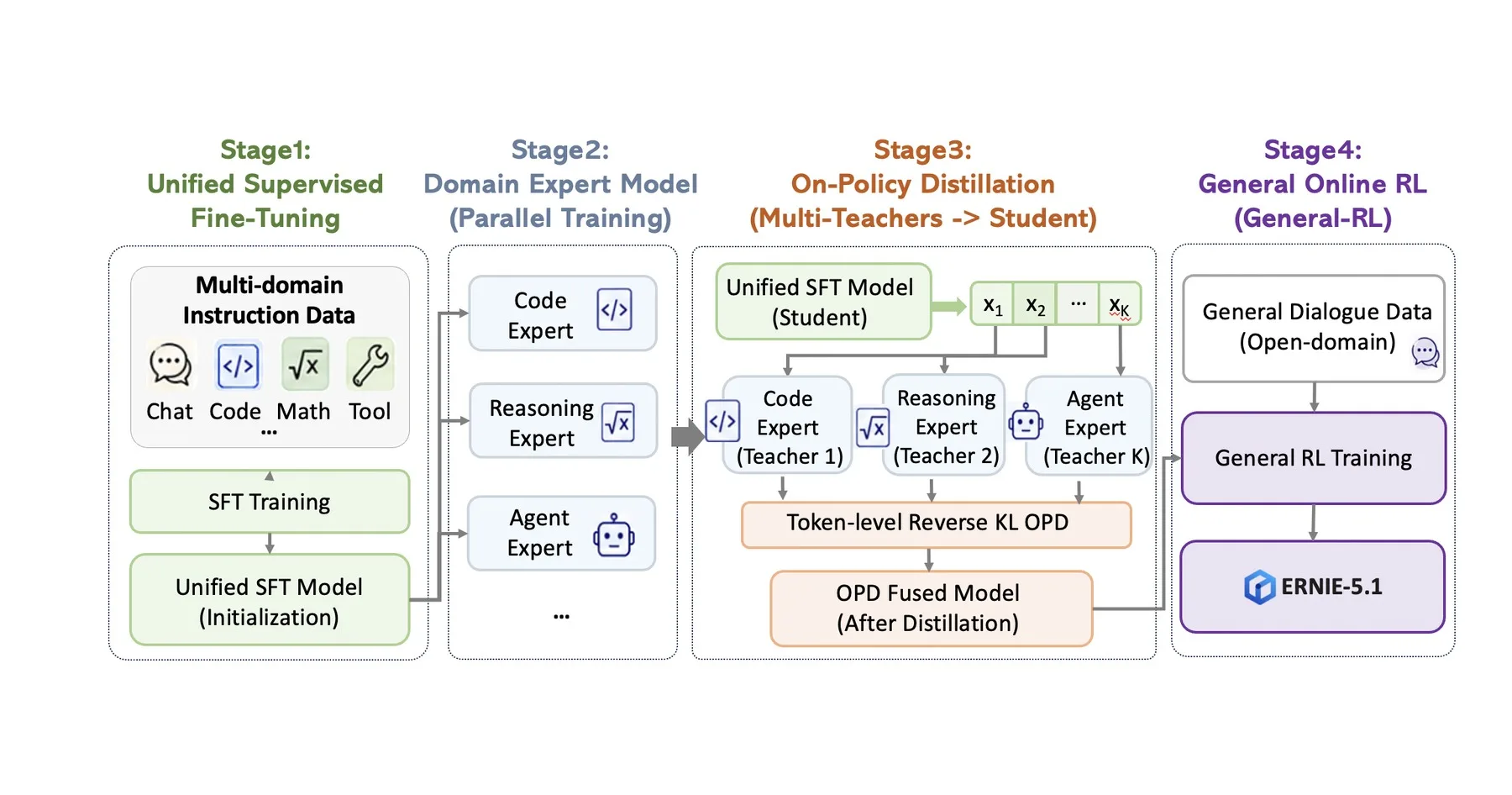
Four-Stage Fine-Tuning to Reduce the “Seesaw Effect”
Baidu also uses a four-stage post-training process designed to reduce what it calls the “seesaw effect.”
This effect happens when improving one capability during training weakens another. For example, gains in coding ability may reduce creativity, or stronger reasoning may come at the cost of conversational flexibility.
The first stage is standard supervised fine-tuning on a broad dataset covering chat, code, mathematics and tool use.
In the second stage, Baidu trains several specialized expert models in parallel. Each expert focuses on a specific capability, such as coding, reasoning or agentic tasks, using its own evaluation signals.
In the third stage, a single student model learns from all of these teacher models. It generates its own answers and compares them with responses from the experts.
The final stage is a general online reinforcement learning phase focused on open dialogue and creative tasks. Baidu says this is needed because teacher-student training alone can make responses too smooth and not diverse enough.
Ernie 5.1 Will Roll Out Across Creative Platforms
Ernie 5.1 is available through ernie.baidu.com and a Playground inside Baidu AI Studio.
Baidu also plans to gradually roll out the model across more than ten creative platforms. These include the role-playing platform Isekai Zero, the creative agent Mulan AI, the AI canvas application Diting Huanliu and the short-drama generator Storymaster.
This suggests Baidu is positioning Ernie 5.1 not only as a technical research model but also as a practical tool for content generation, creative workflows and agent-based applications.
No Open Weights Yet
As with Ernie 5.0, Baidu has not released the model weights for Ernie 5.1.
This means the company’s benchmark scores and efficiency claims cannot yet be independently verified. For now, outside researchers and developers have to rely on Baidu’s own published results and access through the company’s platforms.
Earlier this year, Baidu released Ernie 5.0 as the foundation for this smaller model. The January 2026 model supports text, images, audio and video within a unified architecture and uses a Mixture-of-Experts design with around 2.4 trillion parameters, of which less than 3% are active per request.
Expert Takeaway
Ernie 5.1 shows how major AI developers are trying to make frontier-level models smaller, cheaper and more efficient without fully sacrificing performance. Baidu’s approach focuses on extracting a lighter model from a larger pretrained system, using shared weights, sparse experts and a more modular reinforcement learning pipeline.
If Baidu’s claims hold up, Ernie 5.1 could strengthen China’s position in search, agentic AI and creative applications. However, without open model weights or independent verification, the reported benchmark and efficiency results should be treated as promising but not yet fully confirmed.

 ES
ES  EN
EN