

MiMo-V2.5-Pro is a Mixture-of-Experts model, meaning only a portion of the network is activated for each request rather than the entire model. In total, the system contains 1.02 trillion parameters, with 42 billion active per query. According to the MiMo team, the new version is primarily aimed at long-horizon tasks spanning hours of work and thousands of tool calls.
The context window pushes the boundaries of what is currently possible: the main version processes up to one million tokens at once, while the base variant — without post-training — is capped at 256,000 tokens.
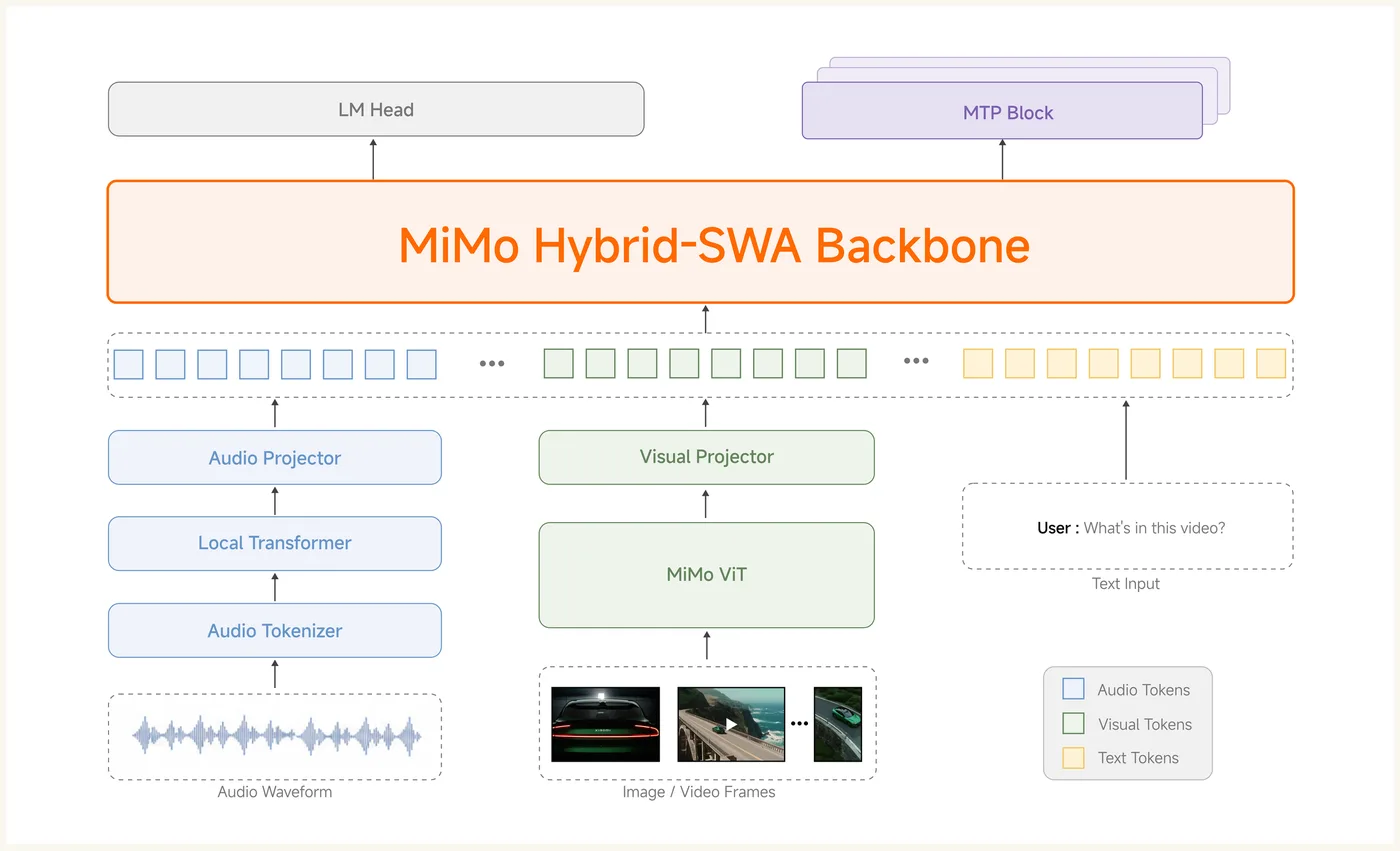
A Compiler Built in an Afternoon
Xiaomi illustrates the leap forward over its predecessor with three concrete examples. In the first, the team tasked the model with building a complete compiler project used in coursework at Peking University — an assignment that typically takes computer science students several weeks to complete.
MiMo-V2.5-Pro delivered the project in 4.3 hours through 672 tool calls, achieving a perfect score of 233 out of 233 on the hidden test suite. What Xiaomi highlights is not the score itself, but the approach: the model first constructed the entire pipeline as a scaffold, then worked through each stage layer by layer. Even the very first compile run passed 137 of 233 tests. A later refactoring phase introduced a regression that the model independently diagnosed and resolved.
In a second demonstration, MiMo-V2.5-Pro built a desktop video editor of roughly 8,000 lines of code from just a few instructions — working autonomously for 11.5 hours and making around 1,870 tool calls in the process.
A third demonstration connected the model via Claude Code to a circuit simulator and had it design a voltage regulator. Within one hour, the result met all six technical specifications simultaneously — four of which exceeded the model's initial design by roughly an order of magnitude.
Fewer Tokens for Comparable Results
Xiaomi positions MiMo-V2.5-Pro primarily on its performance-to-token-cost ratio. On the in-house agent benchmark ClawEval, the model achieves a 64% success rate using around 70,000 tokens per task run — 40 to 60% fewer than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 require for comparable results.
On coding benchmarks, the model scores 78.9 on SWE-bench Verified, 57.2 on SWE-Bench Pro, and 68.4 on Terminal-Bench 2.0, with 73.7 on the proprietary MiMo Coding Bench. This puts it within striking distance of Claude Opus 4.6 (77.1), while Gemini 3.1 Pro falls back to 67.8. On general agent tasks, MiMo-V2.5-Pro earns 1,581 Elo points on GDPVal-AA and 72.9 on τ³-bench.
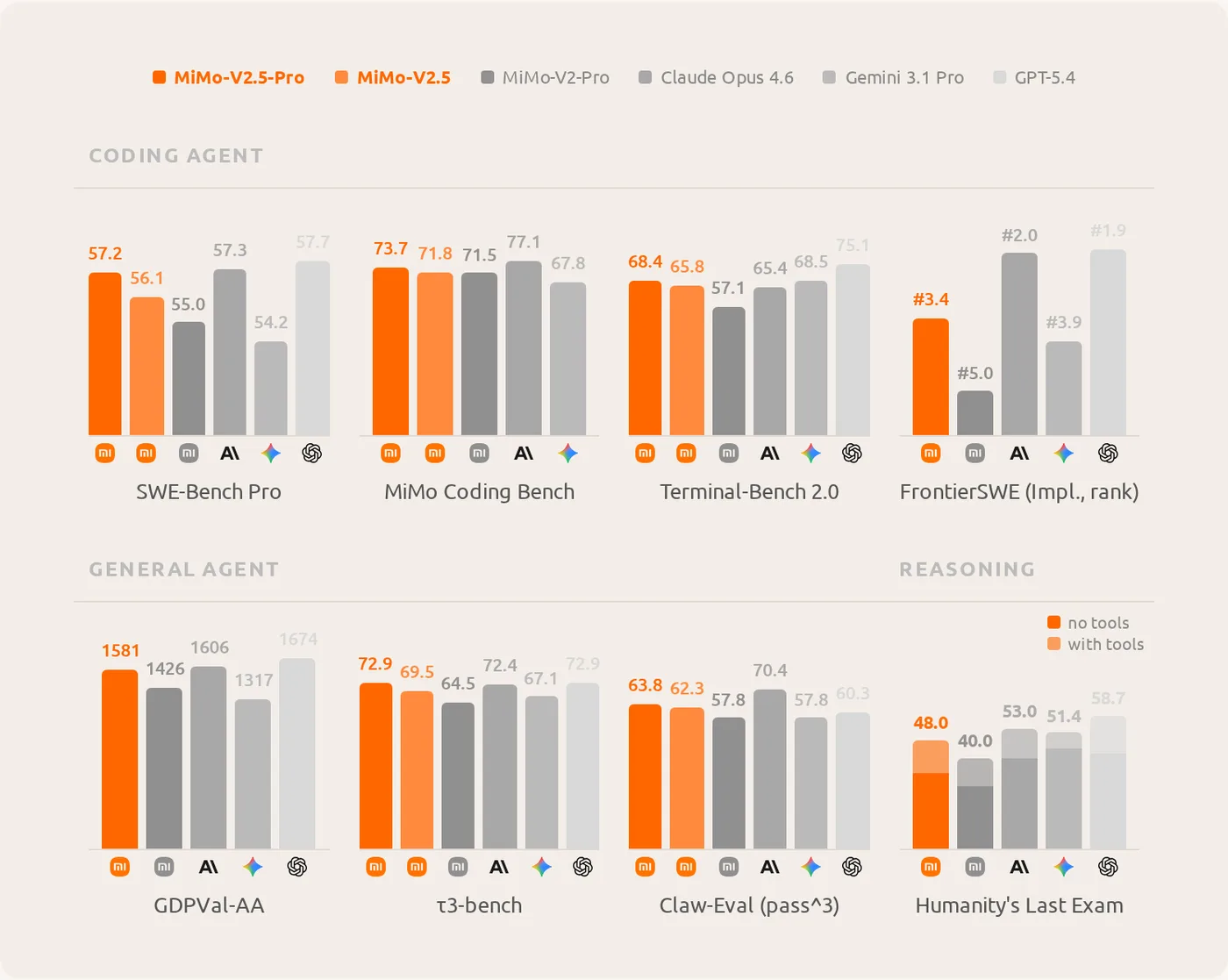
Progress is most striking on long-context tasks. On OpenAI's GraphWalks benchmark — which requires navigating complex node graphs — the predecessor MiMo-V2-Pro collapsed to zero at one million tokens. MiMo-V2.5-Pro scores 0.37 for breadth-first search and 0.62 for parent-node queries under the same conditions.
The model inherits its technical foundation from MiMo-V2-Flash. A hybrid local-global attention mechanism cuts memory usage on long texts by nearly seven times, while a parallel token prediction mechanism triples output speed. Pre-training ran on 27 trillion tokens, with the context window subsequently extended in stages to one million tokens.
Post-training follows a teacher-student approach: multiple specialist models are first trained separately on domains such as mathematics, safety, and tool use. A single student model then learns from its own solution attempts under the guidance of all specialists, absorbing their combined capabilities.
Three More Models in Tow
Alongside the Pro model, Xiaomi is releasing three additional systems. MiMo-V2.5 is a smaller variant with 310 billion parameters, 15 billion of which are active per query. It natively processes text, images, video, and audio, supports up to one million tokens of context, and was trained on roughly 48 trillion tokens. On the Video-MME benchmark, it scores 87.7 — on par with Gemini 3 Pro, according to Xiaomi. Like the Pro model, it is available as open weights on Hugging Face.
The picture is different for speech synthesis. MiMo-V2.5-TTS is a family of three models: one offering preset voices, one generating new voices from text descriptions, and one cloning voices from short audio clips. Users can control prosody directly in the text using inline tags such as [crying] or [whispers]. These models are not openly available; they can only be accessed via API through Xiaomi's own platform, currently free during a limited period.
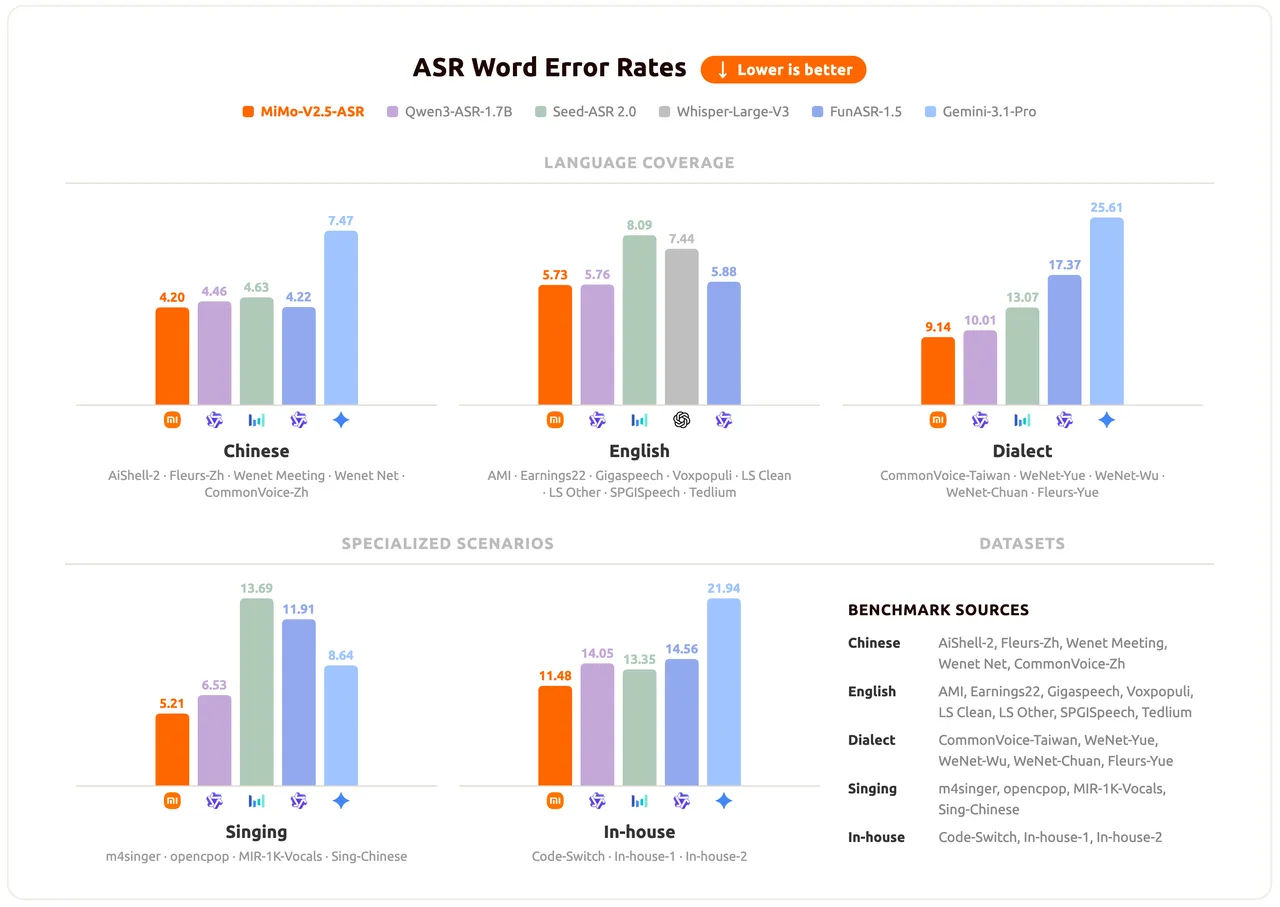
The speech recognition model MiMo-V2.5-ASR, by contrast, is openly available. It operates bilingually in Chinese and English, handles Chinese dialects including Wu, Cantonese, and Hokkien, and can manage mid-sentence language switches as well as song lyrics. On the Open ASR Leaderboard, it achieves an average word error rate of 5.73%.
China's Open-Weight Providers Double Down
With this release, Xiaomi's MiMo team continues the trajectory it set at the end of 2025: many models released simultaneously, largely open, and all designed for autonomously operating AI agents. Next steps outlined by the team include further scaling of training and improved understanding of long-range dependencies beyond individual sentences.
Shortly before this release, Xiaomi had already introduced its first complete three-model package with MiMo-V2-Pro, MiMo-V2-Omni, and MiMo-V2-TTS. The Pro model at the time had previously topped OpenRouter's usage rankings for several days under the anonymous codename "Hunter Alpha," with many users initially suspecting it was a new Deepseek release.

 ES
ES  EN
EN