

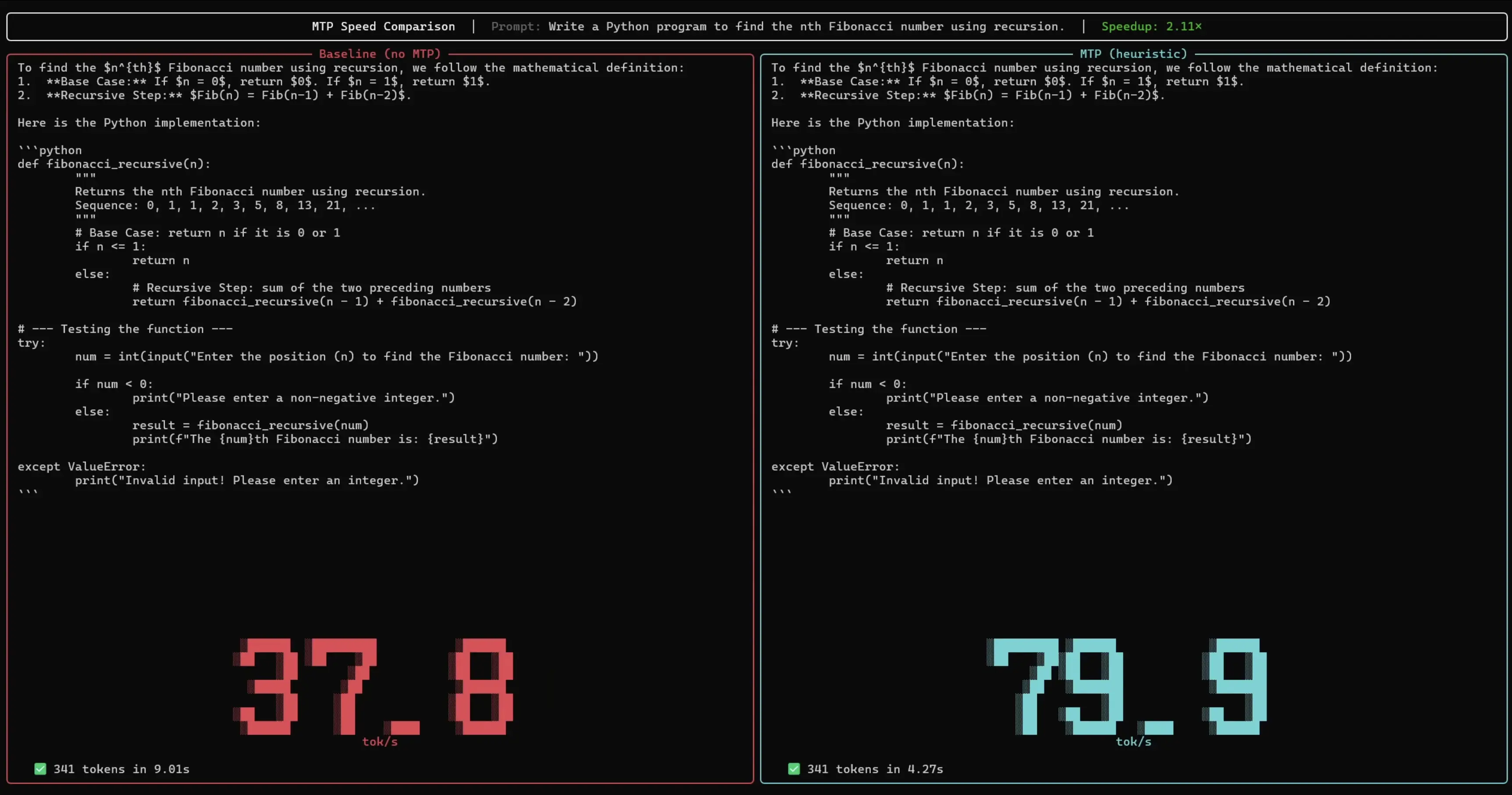
Normally, large language models generate text one token at a time. At each individual step, billions of parameters must be loaded from memory — leaving the processor's compute core largely idle, waiting most of the time for data to arrive from memory.
This is exactly where MTP technology comes in. While the large main model is waiting on its data, a small, fast auxiliary model uses the spare compute capacity to propose several words at once. The main model then reviews these suggestions in a single batched pass. If the proposals are correct, all of them are accepted at once. Although two models are running simultaneously, the small auxiliary model fills idle cycles that would otherwise go to waste — producing the same output in significantly less time, reportedly without any loss in quality or accuracy.
According to Google, smartphones, local machines, and cloud applications all stand to benefit. The drafters are available under the open Apache 2.0 license on Hugging Face and Kaggle. The Gemma 4 open-weight model, introduced in early April, has already been downloaded more than 60 million times, according to Google.
MTP drafters represent a meaningful engineering step toward making large language models practical on consumer hardware — closing the gap between raw model capability and real-world deployment speed. If the reported 3x throughput gains hold across diverse workloads, this could significantly accelerate the adoption of on-device AI without requiring hardware upgrades.

 ES
ES  EN
EN