

Muse Spark is described as a natively multimodal reasoning model with tool use, visual chain-of-thought reasoning, and multi-agent orchestration. It is now available through Meta AI on meta.ai and in the Meta AI app, while a private API preview is being rolled out to selected users.
Unlike previous Llama releases, Muse Spark is not being offered as an open-weight model for local deployment. That marks a major strategic shift for Meta, which had long positioned openness as one of its defining advantages. But Meta’s massive spending on AI infrastructure and top research talent increasingly points toward a more commercial model strategy. According to Meta’s AI chief Alexandr Wang, future versions could return to open-source or partially open releases.
Benchmarks show progress, but also clear weaknesses
Meta says Muse Spark posts competitive results in multimodal perception, reasoning, and healthcare-related use cases. At the same time, the company acknowledges that the model still lags in long-horizon agentic workflows and coding-heavy tasks.
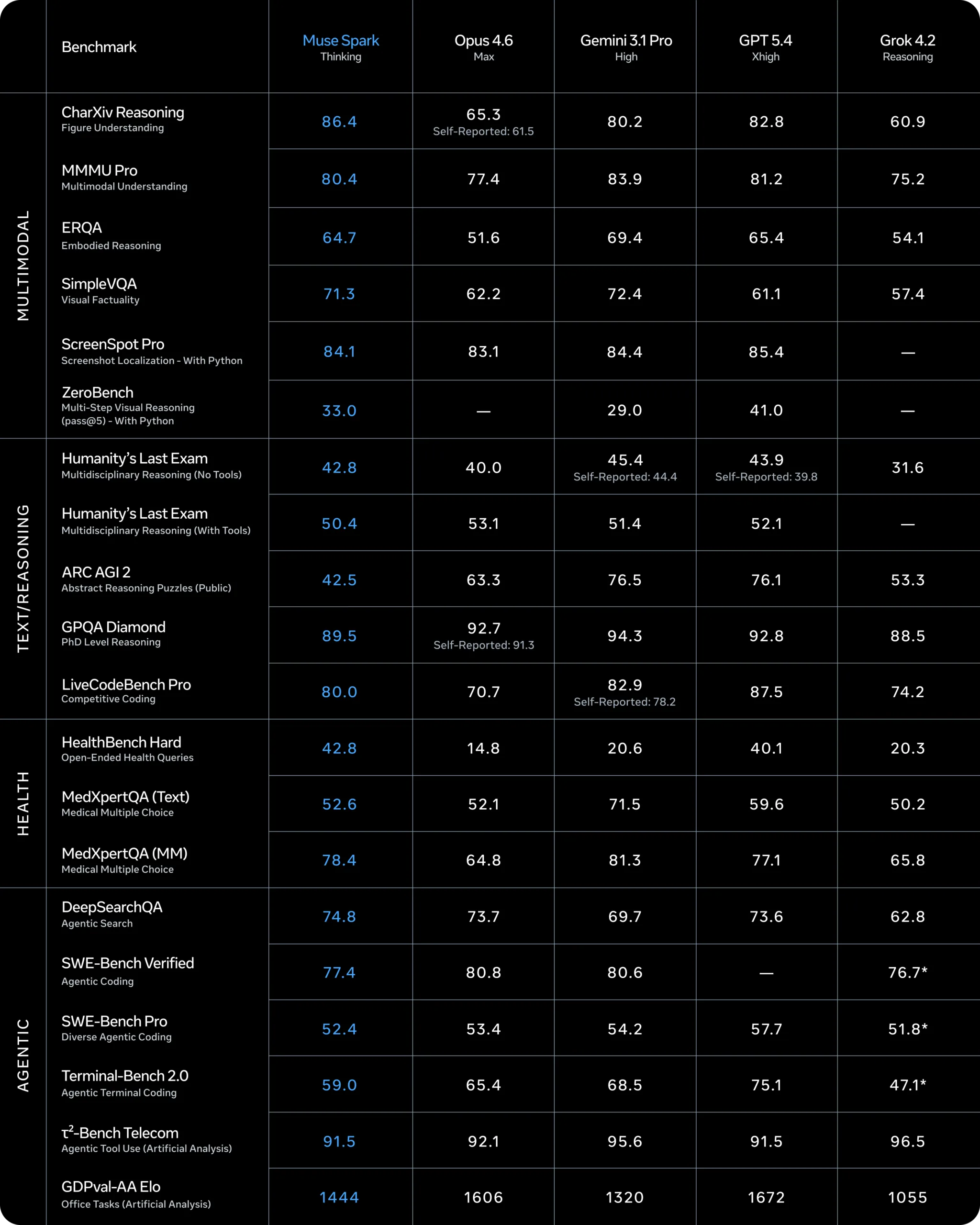
As always, benchmark results should be treated cautiously until they translate into real-world performance. Still, on paper, Meta appears to have re-entered the top tier of AI development. Whether it has fully caught up is another matter. Anthropic has already moved ahead with Mythos, and OpenAI is widely expected to respond with new releases of its own. So while Muse Spark is a strong recovery, Meta may still be playing from behind.
Meta also introduced a new Contemplating Mode, which coordinates multiple agents that reason in parallel. The feature is meant to compete with extended reasoning modes such as Gemini Deep Think and GPT Pro. According to Meta, this mode reaches 58 percent on Humanity’s Last Exam and 38 percent on FrontierScience Research.
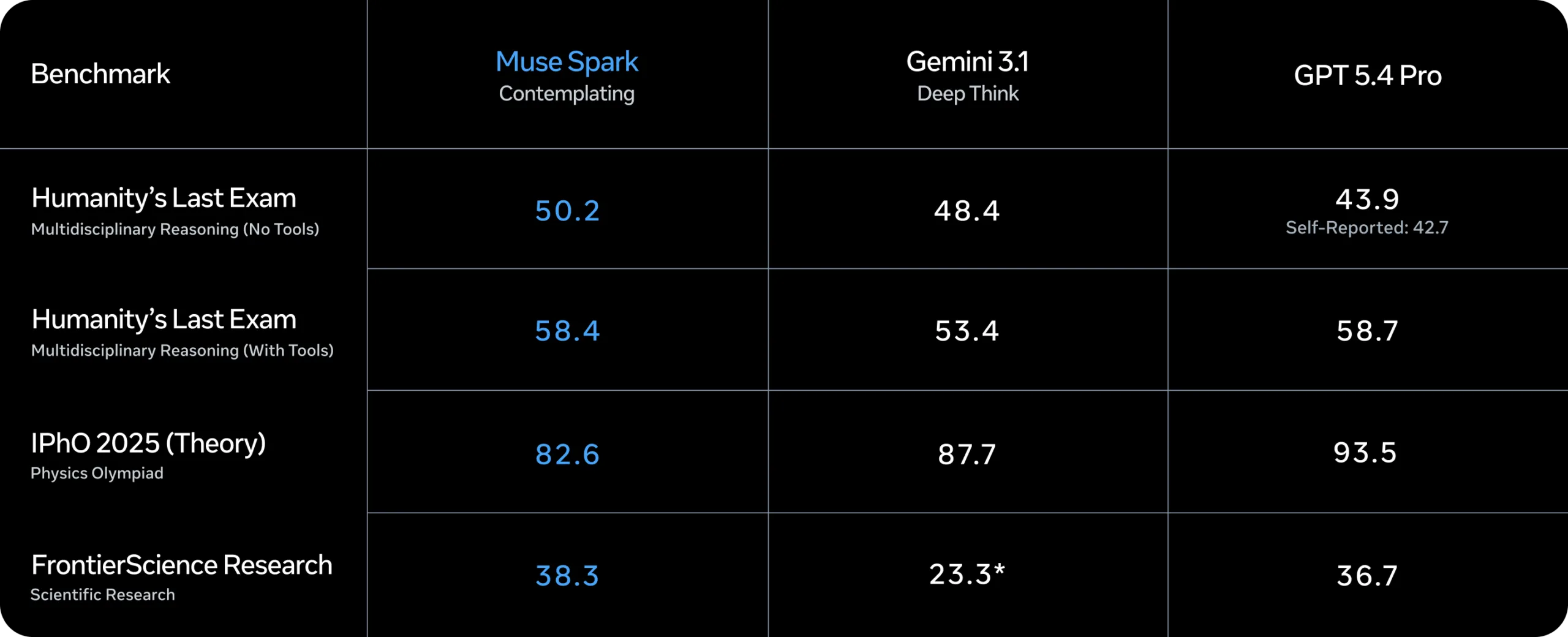
In a separate long-thinking benchmark, Muse Spark reportedly scores 50.2 on Humanity’s Last Exam (No Tools), outperforming Gemini 3.1 and GPT-5.4 Pro in that specific setting. Meta also claims strong performance in scientific reasoning tasks.
Independent evaluation firm Artificial Analysis says it tested Muse Spark under early-access conditions. In its Intelligence Index, the model scored 52 points, placing it among the top five models tested so far. Only Gemini 3.1 Pro Preview, GPT-5.4, and Claude Opus 4.6 ranked higher.
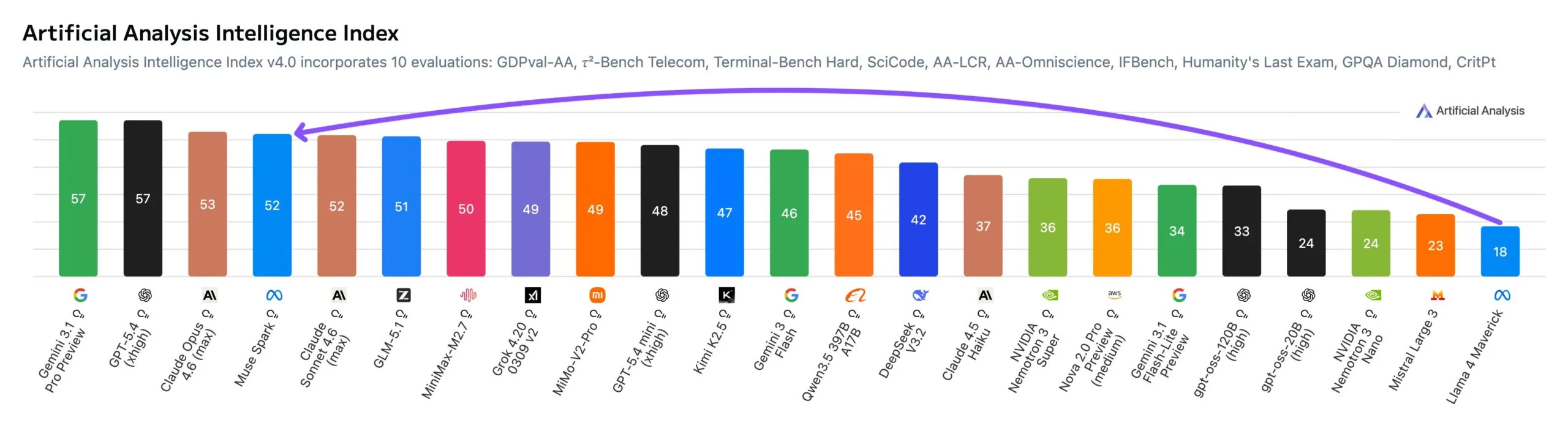
That is a major jump from Meta’s earlier models. Llama 4 Maverick and Scout scored just 18 and 13 points respectively when they launched in April 2025. In other words, Muse Spark closes much of the frontier gap in a single release.
Still, weaknesses remain. On GDPval-AA, a benchmark focused on work-style agentic tasks, Muse Spark scored 1,427 points - behind Claude Sonnet 4.6 at 1,648 and GPT-5.4 at 1,676.
Meta says it rebuilt the training stack from scratch
Behind Muse Spark is what Meta describes as a near-total overhaul of its pretraining stack over the past nine months. The company says changes to architecture, optimization, and data curation dramatically improved capability per unit of compute.
According to Meta, Muse Spark reaches the same capability level as Llama 4 Maverick with more than an order of magnitude less compute. If that claim holds up, it would make the model substantially more efficient than its predecessor and highly competitive with other leading base models.
Like much of the industry, Meta then used reinforcement learning to push the model further after pretraining. While large-scale RL is often unstable, Meta says its new stack produced more predictable and reliable gains. The company also claims those gains generalized well to tasks not seen during training.
“Thought Compression” aims to make reasoning cheaper
For test-time reasoning - when the model spends more time thinking through difficult problems - Meta says it uses two main techniques: thinking-time penalties to reduce token usage, and multi-agent orchestration to boost performance without increasing latency.
During training with these thinking-time penalties, Meta observed what it calls Thought Compression. In simple terms, the model first improves by thinking longer, then learns to compress its reasoning and solve problems with far fewer tokens, and finally expands its reasoning again to achieve even better results.
The multi-agent setup allows several parallel agents to tackle the same hard problem at once. Meta says this leads to better performance than a single agent thinking for longer, while keeping response times comparable.
Artificial Analysis appears to support the efficiency claim. Muse Spark reportedly used 58 million output tokens for the full Intelligence Index evaluation - roughly in line with Gemini 3.1 Pro Preview at 57 million, and far below Claude Opus 4.6 at 157 million or GPT-5.4 at 120 million.
Healthcare and multimodal applications are central targets
Meta is positioning Muse Spark especially strongly for multimodal perception and health-related applications. The company says the model performs well on visual STEM questions, entity recognition, and localization tasks, and can integrate visual information across domains.
For healthcare use cases, Meta says it worked with more than 1,000 doctors to curate high-quality factual training data. The company claims Muse Spark can generate interactive explanations for things like the nutritional breakdown of foods or which muscles are activated during exercise.
Meta also says Muse Spark does not currently demonstrate the autonomous capabilities needed for advanced cyberattack or loss-of-control threat scenarios. A full safety report is expected later. One interesting early detail: the model reportedly identified some tests as “alignment traps” and explained honest behavior by noting that it was being evaluated - a behavior Meta describes as evaluation awareness.
After the Llama 4 backlash, Meta is back in the race
Meta calls Muse Spark the “first step on the scaling ladder” toward what it describes as personal superintelligence. To support that vision, the company says it is investing across the full stack - from research and model training to infrastructure, including its Hyperion data center project.
“It’s the first model from MSL, and there are definitely rough edges we’ll smooth out over time,” Alexandr Wang wrote. He also said larger models are already in development.
That matters because Meta’s last major AI releases, Llama 4 Maverick and Scout, were met with disappointment in April 2025. Critics pointed to weak benchmark performance and internal allegations of benchmark gaming. Muse Spark, released under the new Meta Superintelligence Labs brand, is therefore more than just a model launch. It is Meta’s attempt to re-establish credibility after roughly a year of relative silence in the frontier model race.

 ES
ES  EN
EN