

Architecture and Scale
DeepSeek V4-Pro contains around 1.6 trillion total parameters, but only 49 billion are activated at each step. A smaller version, V4-Flash, has 284 billion total parameters, with 13 billion active during inference.

Both models use a Mixture of Experts architecture. In this approach, only the most relevant subnetworks are activated for each token. This can make inference more efficient than fully dense models while maintaining strong performance.
The models were pretrained on a corpus of more than 32 trillion tokens. DeepSeek then applied staged post-training, with separate phases focused on coding, mathematics, logical reasoning, and instruction following. The final model combines these capabilities through distillation.
Long Context Becomes Cheaper
One of the main upgrades in V4 is the optimization of long-context processing. While several frontier models already support context windows of up to 1 million tokens, using such long inputs often comes with high cost and increased latency.
DeepSeek says V4 significantly reduces the resources required for these operations. Compared with V3.2, V4-Pro reportedly needs about 27% of the compute and 10% of the KV-cache memory when operating at maximum context length. For V4-Flash, the figures are around 10% and 7%, respectively.
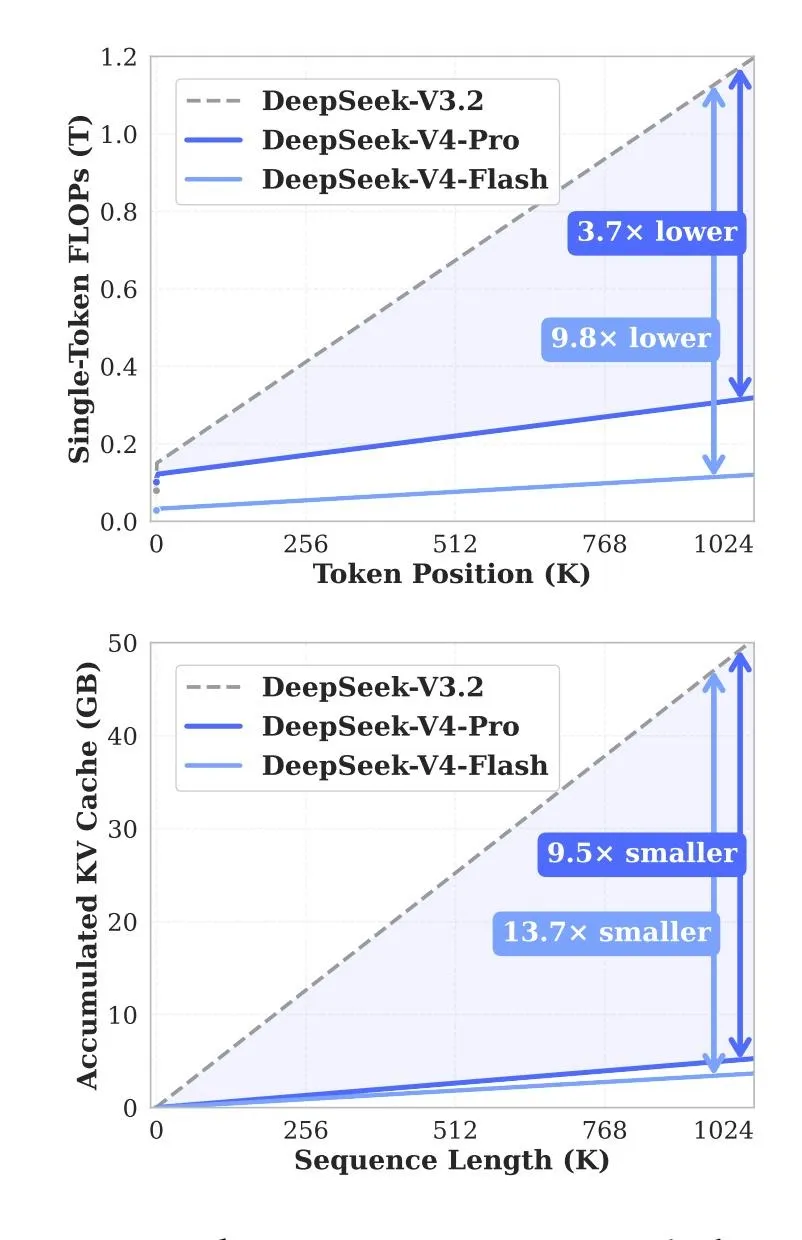
The team says these gains come from a hybrid attention architecture. Two compression mechanisms reduce the load when processing long documents and extended conversations. DeepSeek also used specialized hyper-connections for training stability and the Muon optimizer to accelerate training.
Reasoning Modes and Agent Capabilities
DeepSeek V4 supports three reasoning modes:
- Non-think: fast responses for simple questions without additional analysis.
- Think High: deeper reasoning for complex tasks and planning.
- Think Max: the most intensive mode, where the model works through each step and checks multiple options.
In agentic tasks, Max mode now preserves the chain of intermediate steps within a single task. In the previous version, some of this context could be lost during user interaction.
Benchmark Results
According to DeepSeek, the flagship model delivers results comparable to leading AI systems across several domains:
- In programming tasks on Codeforces, the model reached a rating of 3206, placing it around 23rd among active human programmers and roughly matching GPT-5.4.
- In mathematics, it scored 95.2 on HMMT 2026 and 89.8 on IMOAnswerBench, outperforming most competing models.
- On SimpleQA Verified, it scored 57.9, ahead of Claude Opus 4.6 at 46.2, but behind Gemini 3.1 Pro at 75.6.
- In reasoning, DeepSeek says the models trail GPT-5.4 and Gemini 3.1 Pro by only three to six months.
- In DeepSeek’s internal software engineering benchmark, which includes development, debugging, and refactoring tasks, the model reached 67%, placing it between Sonnet 4.5 at 47% and Opus 4.5 at 70%.
- In agentic development scenarios, V4-Pro-Max scored 80.6% on SWE Verified and 67.9% on Terminal Bench.
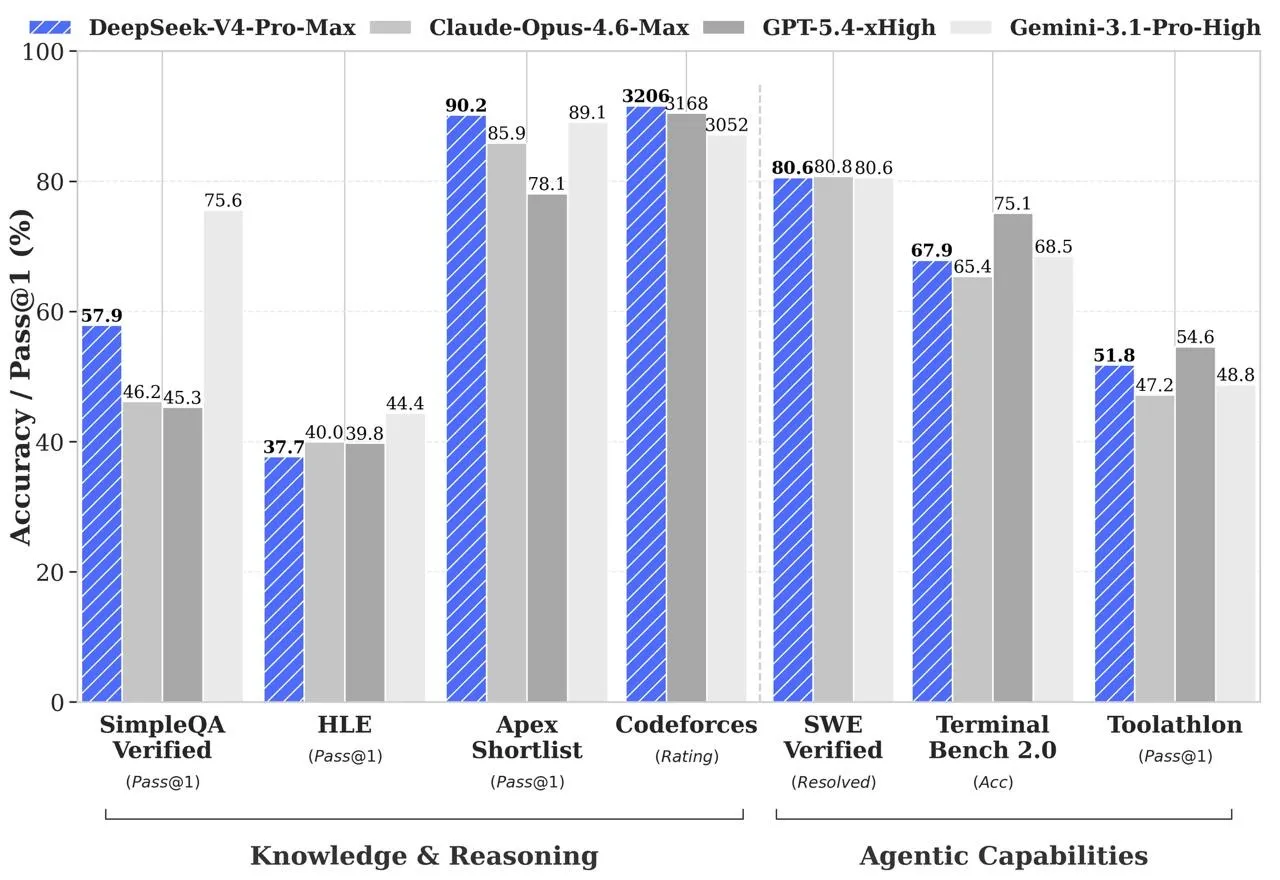
DeepSeek says V4 was trained specifically on real-world workflows, including data analysis, report generation, document editing, web research, and iterative tool use.
To evaluate the model’s usefulness in software development, the startup ran internal tests using tasks from its own engineers. In a survey of 85 developers and researchers, 52% said they would use V4-Pro as their primary coding model, while another 39% said they were leaning toward doing so.
Expert takeaway: DeepSeek V4-Pro is positioned as a serious open-weight competitor in the frontier AI race, especially in coding, long-context processing, and agentic workflows. The most relevant angle for an English-language audience is not just benchmark leadership, but the claim that DeepSeek can deliver high-end AI performance with much lower inference costs.
The preview comes shortly after OpenAI released GPT-5.5 on April 23. OpenAI positions that model as a new level of intelligence for real-world work and AI agent management.

 ES
ES  EN
EN