

For the first time, Google is splitting its Tensor Processing Units into two separate lines: TPU 8t for training and TPU 8i for inference. According to Amin Vahdat, SVP and Chief Technologist for AI and Infrastructure, the change reflects growing inference demand from AI agents that continuously plan, execute, and learn in loops.
Compared with Nvidia, Google is focusing less on peak per-chip performance and more on large-scale connectivity. The Register notes that Nvidia’s upcoming Rubin GPUs are expected to offer more compute performance and much higher memory bandwidth per chip than TPU 8t. But for training frontier models, the decisive factor is not the power of a single chip — it is how many chips can be linked together efficiently.
That is where Google appears to have an advantage. Nvidia’s latest GPUs can connect up to 576 accelerators within a single NVLink domain before they have to rely on slower Ethernet or InfiniBand links. Google, by contrast, uses optical circuit switches to connect 9,600 TPUs inside a single pod. Through its new Virgo Network, the company says multiple data centers can eventually be linked into clusters of up to one million TPUs. A managed Lustre storage layer feeds data directly into accelerator memory. Google is targeting a “goodput” rate of around 97 percent, meaning the chips spend nearly all of their time actually training instead of waiting on checkpoints or recovering from failures.
The inference-focused TPU 8i trades some raw compute for more on-chip SRAM and faster HBM memory. The larger SRAM allows more of the key-value cache — essentially the model’s short-term memory of prior outputs — to stay directly on the chip, reducing delays caused by data movement. A new Collective Acceleration Engine is designed to speed up Mixture-of-Experts models, where different experts may be distributed unpredictably across chips. Google has also developed a network topology called Boardfly, intended to reduce chip-to-chip latency.
Both TPUs will also run, for the first time, on Google’s Arm-based Axion CPUs.
Agent platform combines development and deployment
On the software side, Google is consolidating its AI services into the Gemini Enterprise Agent Platform, built on Vertex AI. For development, the platform includes a tool that lets teams define multi-agent workflows as flowcharts, as well as an interface called Agent Studio, where agents can be created using natural language. A central directory is supposed to prevent organizations from ending up with dozens of overlapping agents built for nearly the same task.
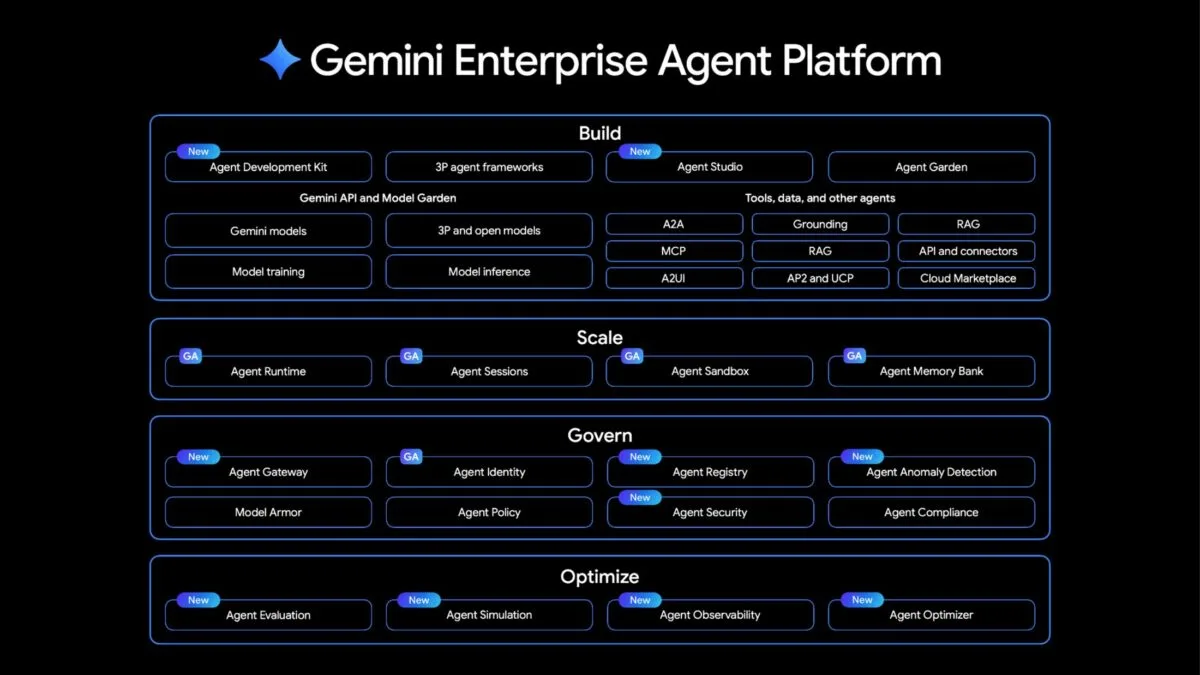
For deployment, Google is targeting some of the most familiar weaknesses of autonomous agents. Long-running agents are supposed to handle multi-step processes on their own instead of waiting for human approval at every stage. Sandboxed test environments allow agents to run code they have written themselves or perform browser automation without putting host systems at risk. A Memory Bank is intended to give agents longer-term memory so they do not have to start from scratch in every session.
Because autonomous agents also create new attack surfaces, Google is adding control mechanisms as well: cryptographic identities for every agent, filters against prompt injection, and anomaly detection for suspicious behavior such as unauthorized data access or reasoning loops that do not end. Simulation tools let developers test agents against synthetic user interactions before they are exposed to real customers. How effective these protections will be in practice remains to be seen.
Available models include Gemini 3.1 Pro, Nano Banana 2, and Lyria 3, alongside Anthropic’s Claude Opus, Sonnet, Haiku, and the new Claude Opus 4.7.
The associated Gemini Enterprise app is aimed at end users. Employees can assemble their own agents from modular building blocks, monitor ongoing tasks in an inbox-like interface, and edit documents directly inside the app.
Workspace Intelligence as a shared knowledge layer
At the same time, Google is launching Workspace Intelligence, a layer designed to connect information across Gmail, Docs, Drive, Meet, and Chat. The idea is that Gemini and the agents built on top of it should understand the relationships between emails, meetings, chats, and files, instead of querying each app in isolation.
In Gmail, Gemini can sort incoming mail and summarize topics. In Google Chat, users can create calendar events or documents directly from a conversation. In Docs, Gemini can generate drafts from emails and files; in Sheets, it can build dashboards; and in Slides, it can create presentations. Drive Projects groups files and emails into topic-based workspaces. For customers looking to switch ecosystems, Google is also offering faster migration from Microsoft 365.
The TPU 8t/8i split is the most strategically telling detail in the entire announcement: Google is effectively admitting that training and inference are now different engineering problems at scale, and that trying to optimize a single chip for both is a losing trade-off. The one-million-TPU cluster target via Virgo, combined with a 97% goodput goal, signals that Google is betting the infrastructure race will be won on interconnect efficiency and utilization — not raw per-chip compute — which is a direct architectural argument against Nvidia's current NVLink-centric approach.

 ES
ES  EN
EN