

Previously, Alibaba relied on two separate models for generation and editing, with the earlier version reaching 20 billion parameters. Shrinking the model to roughly one-third of that size was the result of months of consolidating previously independent development tracks, according to the team.
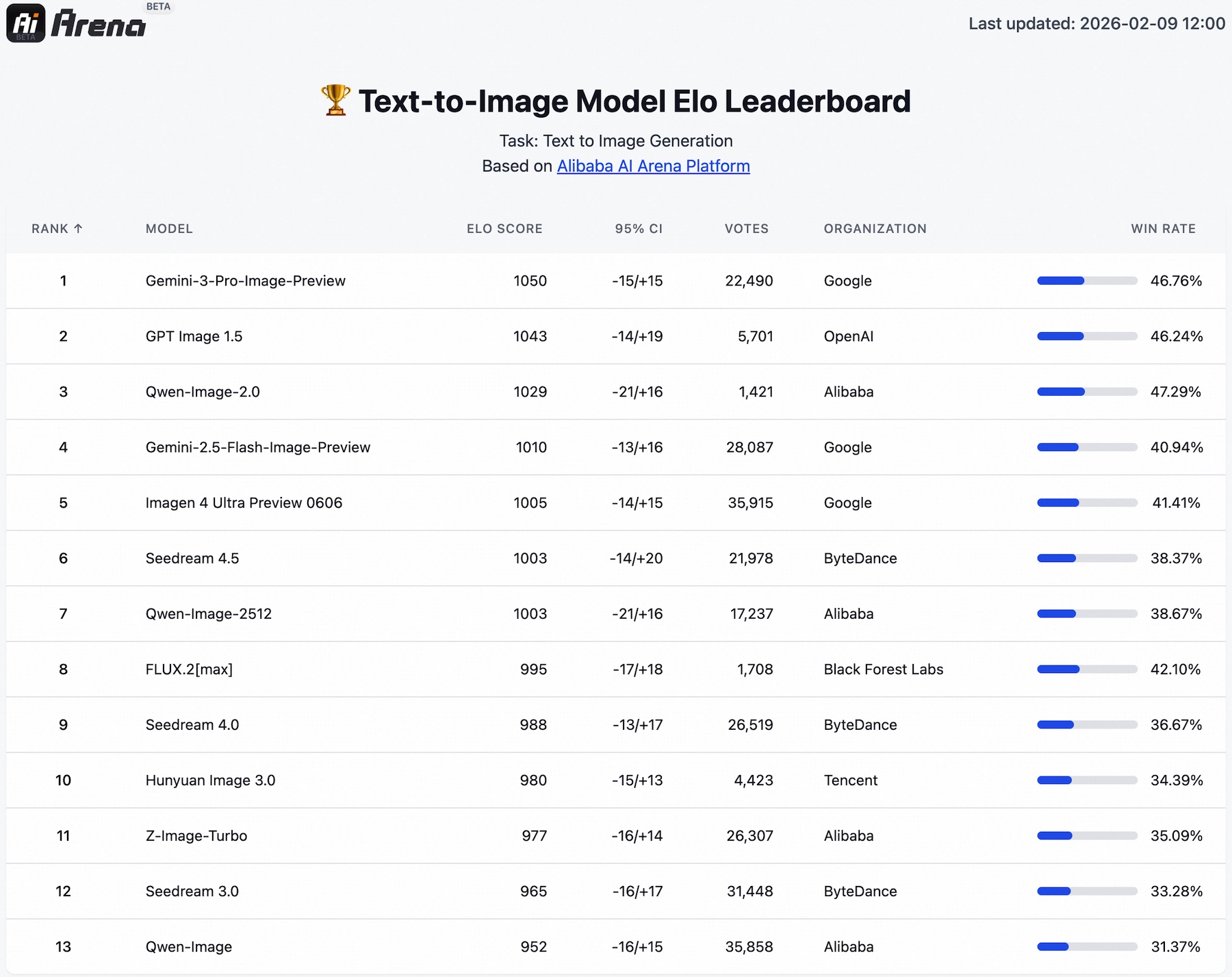
In blind tests conducted on Alibaba’s internal AI Arena platform, Qwen-Image-2.0 reportedly outperformed competitors in both text-to-image and image-to-image tasks. Despite being a unified model competing against specialized systems, it ranks just behind OpenAI’s GPT-Image-1.5 and Google’s Gemini-3-Pro-Image-Preview. On the image editing leaderboard, it holds second place between Nano Banana Pro and ByteDance’s Seedream 4.5.
Near-Perfect Text Rendering
One of Qwen-Image-2.0’s most distinctive capabilities is its ability to render text accurately within generated images. The team highlights five core strengths: precision, complexity, aesthetics, realism, and alignment.
The model supports prompts up to 1,000 tokens, enabling the direct creation of infographics, presentation slides, posters, and even multi-page comics. In one example, it generated a PowerPoint-style slide with a fully accurate timeline and embedded “image-in-image” elements.

Qwen-Image-2.0 also demonstrates advanced multilingual capabilities. A fully AI-generated bilingual travel poster in hand-drawn Chinese style included schedules, illustrations, and travel tips in both Chinese and English.
The most ambitious demonstrations involve Chinese calligraphy. The model reportedly reproduces various historical writing styles, including Emperor Huizong’s “Slender Gold Script” and standard script. In one example, it rendered nearly the entire text of the “Preface to the Orchid Pavilion,” with only minor character errors.

Beyond paper-like surfaces, the model can render text on glass whiteboards, clothing, and magazine covers while maintaining correct lighting, reflections, and perspective. A film poster example combines photorealistic scenes with dense typography in a single coherent image.
Unified Model Improves Editing Quality
Because image generation and editing are handled by the same model, improvements in one domain directly benefit the other.

The team showcased a photorealistic forest scene differentiating more than 23 shades of green with varying textures—from waxy leaves to velvety moss. Editing capabilities include writing poetry onto photos, generating nine-grid portrait variations from a single image, and merging separate photos into natural-looking group shots.

The model also supports cross-dimensional editing, such as inserting cartoon characters into real-world photographs while preserving perspective and scale.

Not Open Source — Yet
Currently, Qwen-Image-2.0 is available via API on Alibaba Cloud in invitation-only beta and as a free demo through Qwen Chat. The model weights have not been released.
However, interest is growing within the open-source community. Its 7B parameter size is considered suitable for running locally on consumer hardware. Observers note that the original Qwen-Image weights were released roughly one month after launch under an Apache 2.0 license, leading many to expect a similar trajectory. No architecture paper has been published so far.
Qwen-Image-2.0 joins a broader trend among Chinese image models emphasizing accurate text rendering. In December, Meituan introduced the 6B LongCat-Image model, followed in January by Zhipu AI’s 16B GLM-Image under an MIT license.

 ES
ES  EN
EN