

OpenAI’s new image model is official. ChatGPT Images 2.0 is based on the new GPT Image 2 model and, according to a company blog post, brings the same capability as Google’s Nano Banana Pro: the model “thinks” before generating, for a shorter or longer time depending on the selected mode, and can even search the internet while doing so. This is intended to enable greater diversity and accuracy in generated images. Expanded outputs with Thinking, however, are only available to ChatGPT Plus, Pro, and Business users.
With Thinking mode enabled, ChatGPT Images 2.0 can generate up to eight images at once from a single prompt. Characters, objects, and styles are supposed to remain consistent across all scenes. OpenAI cites manga pages, series of social media graphics, and design plans for different rooms in a house as example use cases.

Better image quality for all users
Regardless of Thinking mode, all ChatGPT users receive improvements in image quality. According to OpenAI, the generator is better at capturing the “distinctive characteristics of photographs” and shows progress in pixel art, manga, film stills, and other image types. The model is also said to handle fine-grained elements that previous image models regularly struggled with: small text, iconography, UI elements, dense compositions, and subtle stylistic instructions.
Support for aspect ratios ranges from 3:1 (ultra-wide) to 1:3 (ultra-tall), covering formats from banners and presentation slides to mobile screens. Resolution goes up to 2K in the API.
API pricing: token-based and quality-dependent
Through the API, developers can integrate the model into their own products under the name gpt-image-2. OpenAI charges on a token basis: $8 per one million image input tokens and $30 per one million image output tokens. Text tokens cost $5 per million input tokens and $10 per million output tokens. Cached inputs are significantly cheaper.
In practice, the cost per image depends heavily on quality and resolution. According to OpenAI’s pricing overview, a 1024 × 1024 image costs just $0.006 in low quality, $0.053 in medium quality, and $0.211 in high quality. At larger resolutions such as 1024 × 1536, costs drop slightly to $0.005, $0.041, and $0.165 respectively.
|
Model |
Quality |
1024 × 1024 |
1024 × 1536 |
1536 × 1024 |
|---|---|---|---|---|
|
GPT Image 2 |
Low |
$0.006 |
$0.005 |
$0.005 |
|
GPT Image 2 |
Medium |
$0.053 |
$0.041 |
$0.041 |
|
GPT Image 2 |
High |
$0.211 |
$0.165 |
$0.165 |
|
GPT Image 1.5 |
Low |
$0.009 |
$0.013 |
$0.013 |
|
GPT Image 1.5 |
Medium |
$0.034 |
$0.05 |
$0.05 |
|
GPT Image 1.5 |
High |
$0.133 |
$0.2 |
$0.2 |
At larger formats, GPT Image 2 is cheaper than its predecessors: 1024 × 1536 in high quality costs $0.165 instead of $0.20 with GPT Image 1.5 and $0.25 with GPT Image 1.5. At the standard 1024 × 1024 resolution in high quality, however, the new model is more expensive at $0.211 compared with GPT Image 1.5 at $0.133. API outputs above 2K are still in beta and may produce inconsistent results.
OpenAI lists localized advertising, infographics, educational content, design tools, and creative platforms as use cases. In Codex, image generation is expected to be available directly inside the workspace without a separate API key.
In our own benchmark prompt, ChatGPT Image 2 performs exceptionally well. Both versions handle the complex and abstract prompt with high fidelity to the details.
A hyper-realistic DSLR photo. A monkey holding a pink banana is sitting on a tiger in the foreground. In the background, a HORSE is RIDING AN ASTRONAUT. The astronaut is underneath like a living “spacesuit horse saddle,” and the HORSE is clearly on top, in control, as the rider. Make it 100% unambiguous: the HORSE is the rider and the ASTRONAUT is being ridden, NOT the other way around. High-resolution, sharp focus, realistic lighting.
The instant model has a slightly artificial look, while the Thinking version delivers the DSLR requirement much more convincingly.



OpenAI’s new image model will be released soon. The model, which has been circulating for some time under the codename “gpt-image-2,” is already being tested by some ChatGPT users and on public leaderboards. In recent weeks, the first images have appeared on platforms like X and Reddit that are barely distinguishable from real photographs. So far, only testers in the U.S. or those with U.S.-based accounts seem to have gained access to the model.
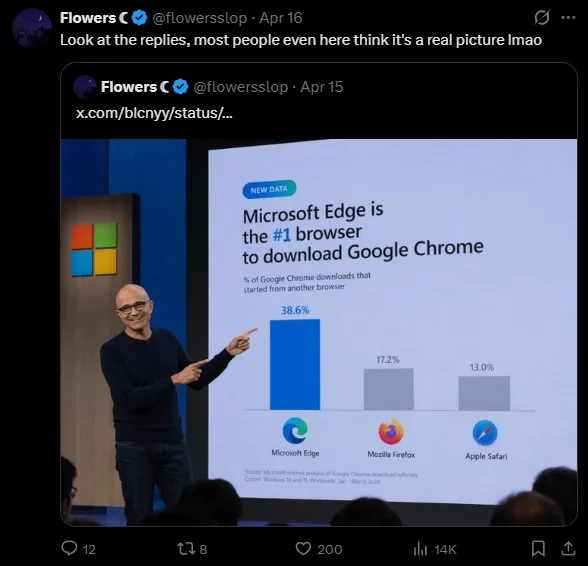
The new model is expected to perform especially well on complex images and diagrams containing text. For example, it is said to be able to generate detailed screenshots. Accordingly, the model could also be useful for advertising and educational content such as infographics, since it renders text more reliably.
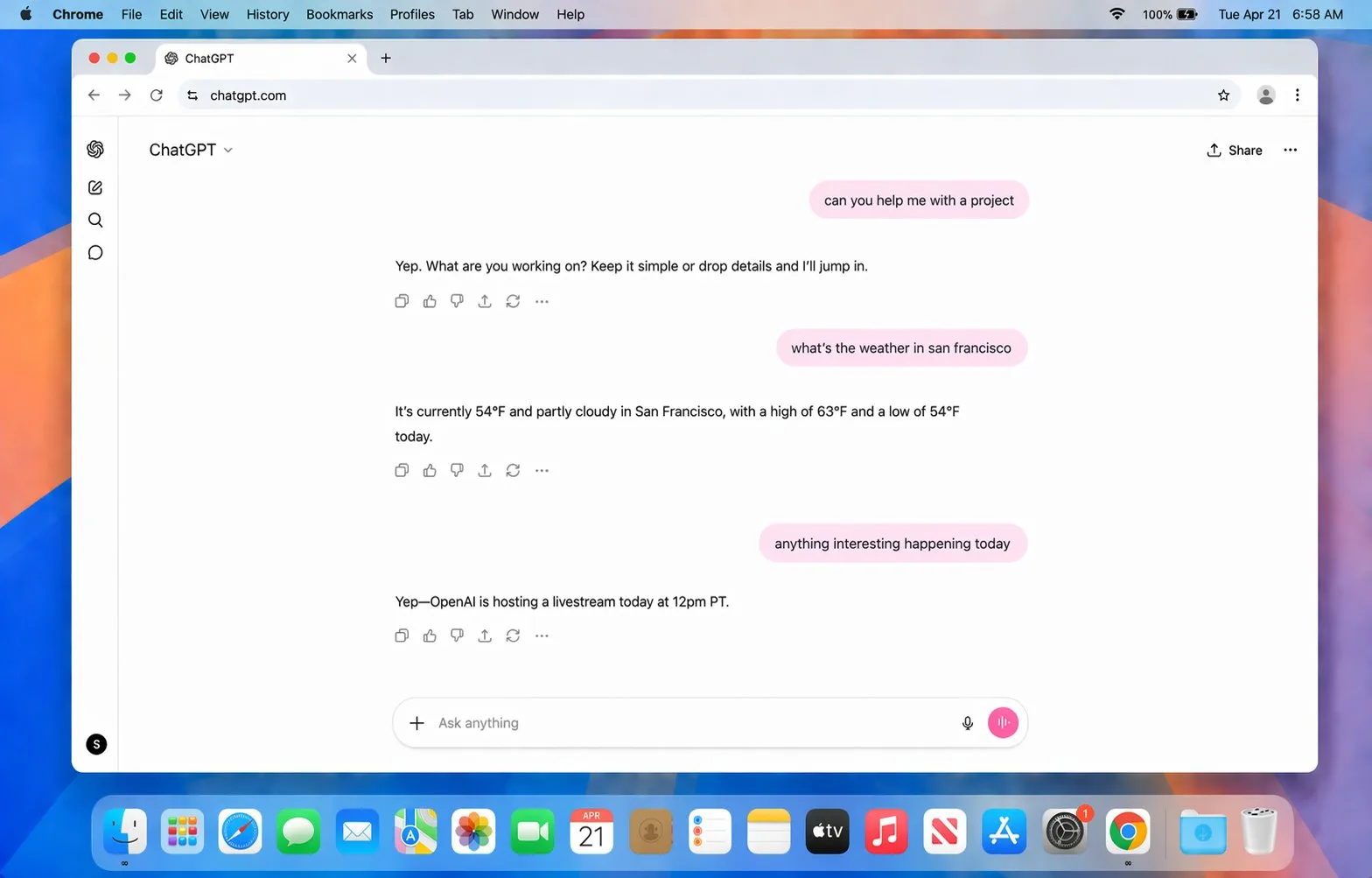
The typical “AI look” with perfect lighting and smooth faces is also supposed to be fixed — a problem that still affected GPT-image 1.5. Until now, Google’s Nano Banana Pro clearly had the upper hand here. OpenAI is officially unveiling its new image model tonight in a livestream starting at 9 p.m. German time.
GPT Image 2 looks like a meaningful step forward because OpenAI is combining higher visual fidelity with reasoning, web-aware generation, and better consistency across multiple outputs. The most important practical improvements are not just prettier images, but stronger handling of text, layouts, UI-like compositions, and production-oriented formats that make the model more useful for real creative and commercial workflows.

 ES
ES  EN
EN