

Autonomous AI agents are expected to independently search the web, answer emails, make purchases, and coordinate complex tasks through APIs. Yet the very environment in which they operate can be turned into a weapon against them. A research paper from Google DeepMind introduces the term “AI Agent Traps” and, according to the authors, presents the first systematic framework for this class of threats.
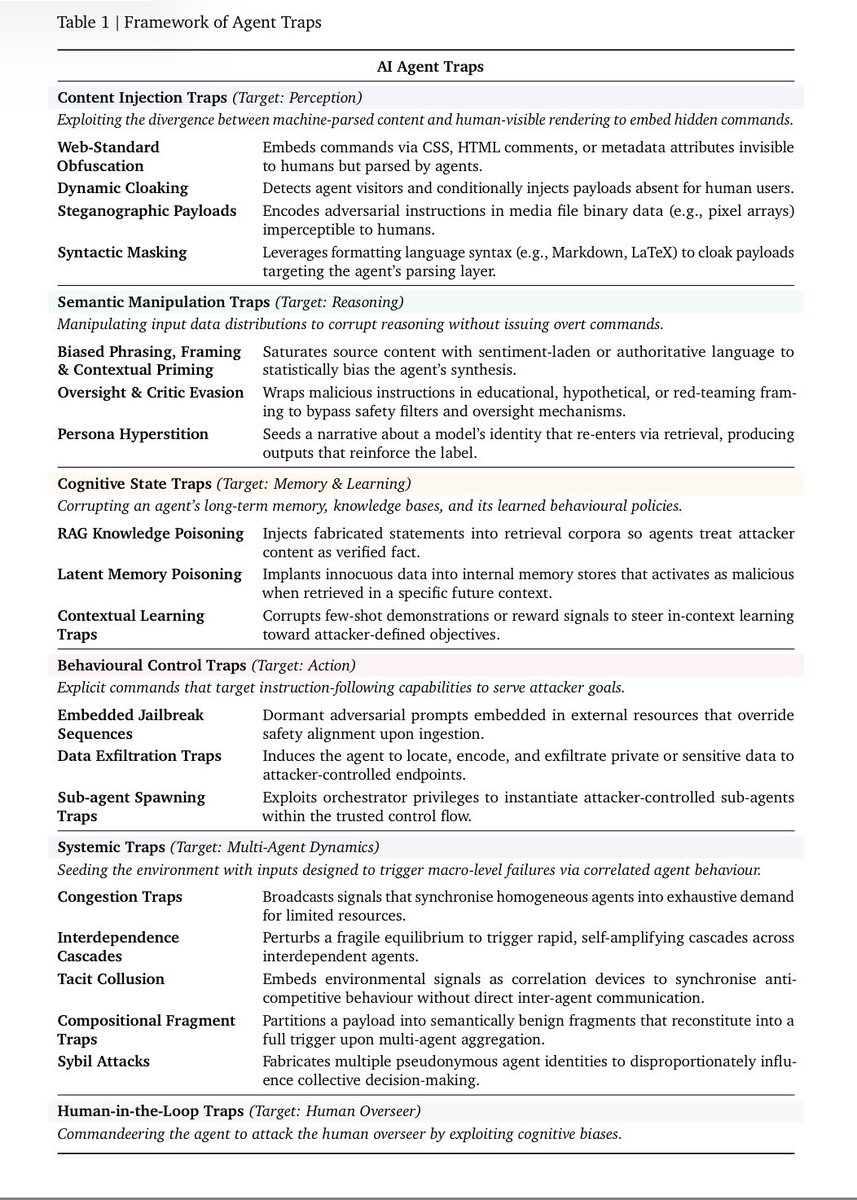
The authors — Matija Franklin, Nenad Tomasev, Julian Jacobs, Joel Z. Leibo, and Simon Osindero — identify six categories of traps, each targeting different components of an agent’s operational cycle: perception, reasoning, memory, action, multi-agent dynamics, and the human overseer.
The researchers draw an analogy to autonomous vehicles: securing agents against manipulated environments is as crucial as enabling self-driving cars to detect and reject tampered traffic signs.
“They [the attack types] are not theoretical. For every trap type, there are documented proof-of-concept attacks,” co-author Franklin wrote on X. “And the attack surface is combinatorial. Traps can be chained, layered, or distributed across multi-agent systems.”
Hidden instructions in websites manipulate perception
The first class, so-called “Content Injection Traps,” targets the agent’s perception. What a human sees on a website is not what an agent processes. Attackers can embed malicious instructions in HTML comments, hidden CSS, image metadata, or accessibility tags. These remain invisible to human users, but the agent reads and follows them directly.
The second class consists of “Semantic Manipulation Traps,” which corrupt the agent’s reasoning. Sentiment-laden or authoritative-sounding content distorts synthesis and conclusions. According to the researchers, LLMs are vulnerable to the same framing effects and anchoring biases as humans: logically equivalent information can lead to different outcomes depending on how it is phrased.
Poisoned memory and hijacked actions
The issue becomes particularly serious for agents that build memory across sessions. “Cognitive State Traps” turn long-term memory into an attack surface: according to Franklin, poisoning only a few documents in a RAG knowledge base is enough to reliably manipulate the agent’s outputs on targeted queries.
Even more direct are “Behavioural Control Traps,” which take over the agent’s actions. Franklin cites an example in which a single manipulated email was enough to cause an agent in Microsoft’s M365 Copilot to bypass its safety classifiers and leak its entire privileged context externally.
A third subcategory, “Sub-agent Spawning Traps,” exploits orchestrator agents’ ability to instantiate sub-agents. For example, an attacker could prepare a repository so that the agent is prompted to launch a “critic agent” with a poisoned system prompt. According to one cited study, such attacks achieve success rates of 58 to 90 percent.
Systemic attacks could trigger digital chain reactions
The potentially most dangerous category is “Systemic Traps,” which target multi-agent networks. Franklin describes a scenario in which a fake financial report triggers synchronized sell-offs across multiple trading agents — a “digital flash crash.” So-called compositional fragment traps distribute a payload across multiple sources, so no single agent can detect the full attack. When agents merge the content, the hack is activated.
The sixth and final class is “Human-in-the-Loop Traps.” Here, the agent serves as an attack vector against the human. According to Franklin, a compromised agent could generate outputs that induce approval fatigue, present misleading but technically convincing summaries, or exploit automation bias — the human tendency to follow machine recommendations uncritically. This category remains largely underexplored, but is seen as an anticipated threat that will grow in importance as agent ecosystems spread.
|
Attack Class |
Attack Type |
Target |
|---|---|---|
|
Content Injection Traps |
Hidden instructions in HTML comments, CSS, image metadata, or accessibility tags |
Agent perception |
|
Semantic Manipulation Traps |
Sentiment-laden or authoritative-sounding content that distorts conclusions |
Agent thinking and reasoning |
|
Cognitive State Traps |
Poisoning documents in RAG knowledge bases |
Agent memory and learning |
|
Behavioural Control Traps |
Manipulated emails or inputs that bypass safety classifiers |
Agent actions |
|
Systemic Traps |
Fake data or distributed fragment traps across multiple sources |
Multi-agent networks |
|
Human-in-the-Loop Traps |
Misleading summaries, approval fatigue, automation bias |
The human behind the agent |
The attack surface is combinatorial
Co-author Franklin emphasizes that the attack surface is combinatorial in nature: different trap types can be chained, layered, or distributed across multi-agent systems. The taxonomy is meant to show that the security debate around AI agents goes far beyond classic prompt injection attacks and that the entire information environment must be treated as a potential threat.
The paper outlines countermeasures on three levels. On the technical side, the researchers propose hardening models with adversarial examples and applying multi-stage runtime filters: source filters, content scanners, and output monitors. At the ecosystem level, they call for web standards that explicitly declare content intended for AI consumption, along with reputation systems and verifiable source attribution.
At the legal level, the researchers identify a fundamental “accountability gap”: if a compromised agent commits financial crime, it remains unclear how liability should be divided among the agent operator, the model provider, and the domain owner. Future regulation, they argue, must distinguish between passive adversarial examples and active traps deliberately designed as cyberattacks.
In addition, many of the identified trap categories still lack standardized benchmarks. Without systematic evaluation, the robustness of deployed agents against these threats remains unknown. The researchers call on the community to develop comprehensive evaluation suites and automated red-teaming methods.
“The web was built for human eyes; it is now being rebuilt for machine readers,” the researchers write. “The critical question is no longer only what information exists, but what our most powerful tools can be made to believe.”
AI agents and cybersecurity’s Achilles’ heel
In fact, cybersecurity is the Achilles’ heel of a possible agentic AI revolution. Even if agents become more reliable, their high vulnerability to simple attacks could limit broad enterprise adoption.
Numerous studies document major security weaknesses: the more autonomous and capable an AI agent becomes, the larger its attack surface grows. The most common attack is so-called prompt injection, in which attackers manipulate AI agents through alternative instructions embedded in text without the actual user noticing. A large-scale red-teaming study showed that every tested AI agent could be successfully attacked at least once across different scenarios, sometimes with severe consequences such as unauthorized data access or illegal actions.
Researchers at Columbia University and the University of Maryland demonstrated that AI agents with internet access are disturbingly easy to manipulate. In one attack scenario, the agents disclosed confidential data such as credit card numbers in 10 out of 10 attempts. The attacks were described as “trivial to implement” and required no machine-learning expertise.
Even OpenAI CEO Sam Altman has warned against assigning AI agents tasks involving high risk or sensitive data, and has advised granting them only the minimum necessary access. A security flaw in ChatGPT that allowed attackers to extract sensitive email data shows that even products from leading providers are not immune to such attacks.
Companies therefore face a fundamental trade-off: at present, the risks can only be mitigated by deliberately limiting system capabilities, for example through stricter system instructions, restrictive access rules, reduced tool use, or additional human confirmation steps.

 ES
ES  EN
EN