

Its flagship model, MiMo-V2-Pro, uses a mixture-of-experts architecture that, according to Xiaomi, totals more than one trillion parameters, with 42 billion active per query. That makes it roughly three times larger than its predecessor, MiMo-V2-Flash, introduced in December 2025. Despite its scale, Xiaomi says the model remains efficient thanks to a hybrid attention mechanism and can process up to one million tokens of context. Instead of predicting one token at a time, it generates multiple tokens in parallel, making it significantly faster.
Two bar charts show MiMo-V2-Pro’s benchmark results. On the left, it scores 81.0 on PinchBench, ranking third behind Claude Opus 4.6 (81.5) and MiMo-V2-Omni (81.2). On the right, it scores 61.5 on ClawEval, also ranking third behind Claude Opus 4.6 and Claude Sonnet 4.6 (both 66.3).

MiMo-V2-Pro ranks 7th globally on the Artificial Analysis Intelligence Index and is the strongest Chinese language model after GLM-5 and MiniMax-M2.7. On the coding benchmark SWE-bench Verified, it scores 78%, slightly below Claude Opus 4.6 (80.8) but close to Claude Sonnet 4.6 (79.6). On the agent benchmark ClawEval, it reaches 81 points, putting it close to Claude Opus 4.6 (81.5), while GPT-5.2 stands at 77.
From a single prompt, MiMo-V2-Pro can generate a 3D tower defense game with different tower types, enemy waves, and explosion effects.
MiMo-V2-Pro is significantly cheaper than Anthropic
Xiaomi is also undercutting competitors on price. According to its platform page, MiMo-V2-Pro costs $1 per million input tokens and $3 per million output tokens for context lengths up to 256,000 tokens. By comparison, Claude Sonnet 4.6 costs $3 and $15, while Claude Opus 4.6 costs $5 and $25. Xiaomi currently does not charge cache write fees.
The model is available through a public API. At launch, Xiaomi partnered with five agent frameworks: OpenClaw, OpenCode, KiloCode, Blackbox, and Cline. Developers worldwide are expected to receive free API access for one week.
MiMo-V2-Omni sees, hears, and acts in one model
MiMo-V2-Omni combines image, video, and audio encoders into a shared backbone. The model is designed not only to perceive, but to act directly on what it perceives. It natively supports structured tool calls, can execute functions, and can navigate user interfaces.
Six bar charts compare MiMo-V2-Omni with Claude Opus 4.6, GPT-5.2, Gemini 3 Pro, and Gemini 3 Flash across audio, image, and video categories. MiMo-V2-Omni leads on MMAU-Pro (69.4), MMMU-Pro (76.8), BigBench Audio (94.0), Video-MME (85.3), and FutureOmni (66.7), while trailing Gemini 3 Pro (82.1) slightly on CharXiv RQ (80.1).
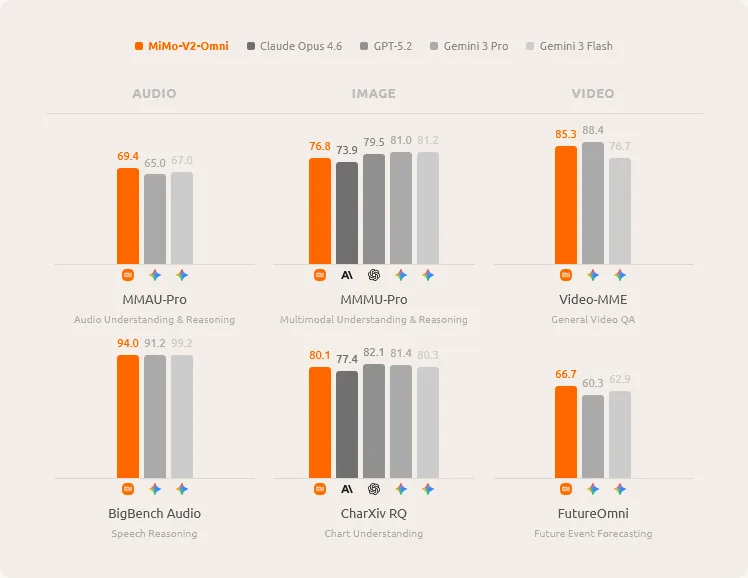
According to Xiaomi, MiMo-V2-Omni outperforms Gemini 3 Pro in audio and can understand continuous recordings longer than 10 hours. In image tasks (MMMU-Pro: 76.8), it beats Claude Opus 4.6 (73.9). Agent benchmark results are more mixed: on ClawEval, the Omni model scores 54.8, well below Claude Opus 4.6 (66.3) and GPT-5.2 (59.6). However, on MM-BrowserComp for web navigation, it outperforms Gemini 3 Pro and GPT-5.2.
In one demo, Xiaomi used the model to analyze dashcam footage. It identified pedestrians, approaching vehicles, and narrow road sections in real time as potential hazards. In another scenario, MiMo-V2-Omni navigated through a browser on its own, researched product reviews on the Chinese platform Xiaohongshu, compared prices on JD.com, negotiated discounts with customer service via chat, and completed the purchase.
In a separate demonstration, the model independently created multimedia content, debugged the related code, and published the result to TikTok through a browser, without human intervention. In all cases, MiMo-V2-Omni made the decisions, while the open-source framework OpenClaw executed the actual browser and filesystem actions.
MiMo-V2-TTS speaks with emotion instead of a dropdown menu
According to Xiaomi, the speech synthesis model MiMo-V2-TTS was trained on more than 100 million hours of voice data. It internally breaks speech into multiple parallel layers of discrete units, enabling more precise control over sound, rhythm, and emotion than conventional systems.
The key difference from traditional TTS systems is that users do not choose emotions from a list. Instead, they describe the desired speaking style freely in natural language. For example, “sleepy, just woke up, slightly hoarse” should sound different from “angry, but trying to stay calm.” The model also generates paralinguistic elements such as coughing, hesitation, sighs, and laughter as native parts of the output rather than as inserted sound effects.
According to Xiaomi, MiMo-V2-TTS is the only commercially available TTS API that natively supports both speech and singing in the same model. Typographic cues such as capital letters or repeated characters are interpreted as performance directions for emphasis and rhythm. “THIS IS IMPORTANT” is not simply spoken louder, but delivered with emphasis. Even without explicit style prompts, the model can infer the appropriate tone directly from the text itself.
Strong benchmarks, but not yet the leader
By releasing three specialized models at once, Xiaomi is signaling that it wants to provide a full platform for AI agents. The benchmark results show that the models are approaching Anthropic and OpenAI in some disciplines, while still trailing in others. In particular, MiMo-V2-Pro still remains several points behind Claude Opus 4.6 on general agent tasks.
As next steps, the MiMo team says it is working on long-horizon planning over hours and days, real-time streaming, coordinated multi-agent systems, and robotics.
“We believe the path to general intelligence runs through the real world,” the team wrote. “A model that only reads text lives in a library. A model that sees, hears, thinks, and acts lives in the world.”
Hunter Alpha was not DeepSeek
Before Xiaomi officially revealed the model, MiMo-V2-Pro had been listed anonymously on the API platform OpenRouter under the codename Hunter Alpha. According to Xiaomi, usage volume on the platform rose steadily, and the model topped the daily leaderboard for several consecutive days, eventually surpassing one trillion tokens used. The most common applications were coding tools.
Many users speculated that Hunter Alpha might be DeepSeek V4. But DeepSeek is still delayed. According to one report, the next major DeepSeek model has been postponed due to increasing model size.
Instead, other Chinese providers are moving ahead. Zhipu AI recently released GLM-5, an open-source model with 744 billion parameters that is intended to compete with Claude Opus 4.5 and GPT-5.2 on coding and agent tasks. Moonshot AI is pursuing parallel agent swarms with Kimi K2.5, while Alibaba has expanded its Qwen-3.5 series.
Xiaomi is rapidly positioning itself as a serious competitor in the AI race by launching a full ecosystem of agent-focused models rather than a single LLM. While its models already approach leaders like Anthropic in several benchmarks, the key advantage lies in lower pricing and real-world agent capabilities. If Xiaomi succeeds in scaling multi-agent systems and robotics integration, it could become a major player in the next phase of AI-driven automation.

 ES
ES  EN
EN